Continuous Deployment with GitLab: how to build and deploy a RPM Package with GitLab CI
I would like to automate building custom rpm packages with gitlab using their CI/CD functionality. This article is a documentation of my personal notes on the matter.
[updated: 2018-03-20 gitlab-runner Possible Problems]
Installation
You can find notes on how to install gitlab-community-edition here: Installation methods for GitLab. If you are like me, then you dont run a shell script on you machines unless you are absolutely sure what it does. Assuming you read script.rpm.sh and you are on a CentOS 7 machine, you can follow the notes below and install gitlab-ce manually:
Import gitlab PGP keys
# rpm --import https://packages.gitlab.com/gitlab/gitlab-ce/gpgkey
# rpm --import https://packages.gitlab.com/gitlab/gitlab-ce/gpgkey/gitlab-gitlab-ce-3D645A26AB9FBD22.pub.gpgGitlab repo
# curl -s 'https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/config_file.repo?os=centos&dist=7&source=script' \
-o /etc/yum.repos.d/gitlab-ce.repo Install Gitlab
# yum -y install gitlab-ceConfiguration File
The gitlab core configuration file is /etc/gitlab/gitlab.rb
Remember that every time you make a change, you need to reconfigure gitlab:
# gitlab-ctl reconfigureMy VM’s IP is: 192.168.122.131. Update the external_url to use the same IP or add a new entry on your hosts file (eg. /etc/hosts).
external_url 'http://gitlab.example.com'Run: gitlab-ctl reconfigure for updates to take effect.
Firewall
To access the GitLab dashboard from your lan, you have to configure your firewall appropriately.
You can do this in many ways:
-
Accept everything on your http service
# firewall-cmd --permanent --add-service=http -
Accept your lan:
# firewall-cmd --permanent --add-source=192.168.122.0/24 -
Accept only tcp IPv4 traffic from a specific lan
# firewall-cmd --permanent --direct --add-rule ipv4 filter INPUT 0 -p tcp -s 192.168.0.0/16 -j ACCEPT
or you can complete stop firewalld (but not recommended)
- Stop your firewall
# systemctl stop firewalld
okay, I think you’ve got the idea.
Reload your firewalld after every change on it’s zones/sources/rules.
# firewall-cmd --reload
successBrowser
Point your browser to your gitlab installation:
http://192.168.122.131/this is how it looks the first time:
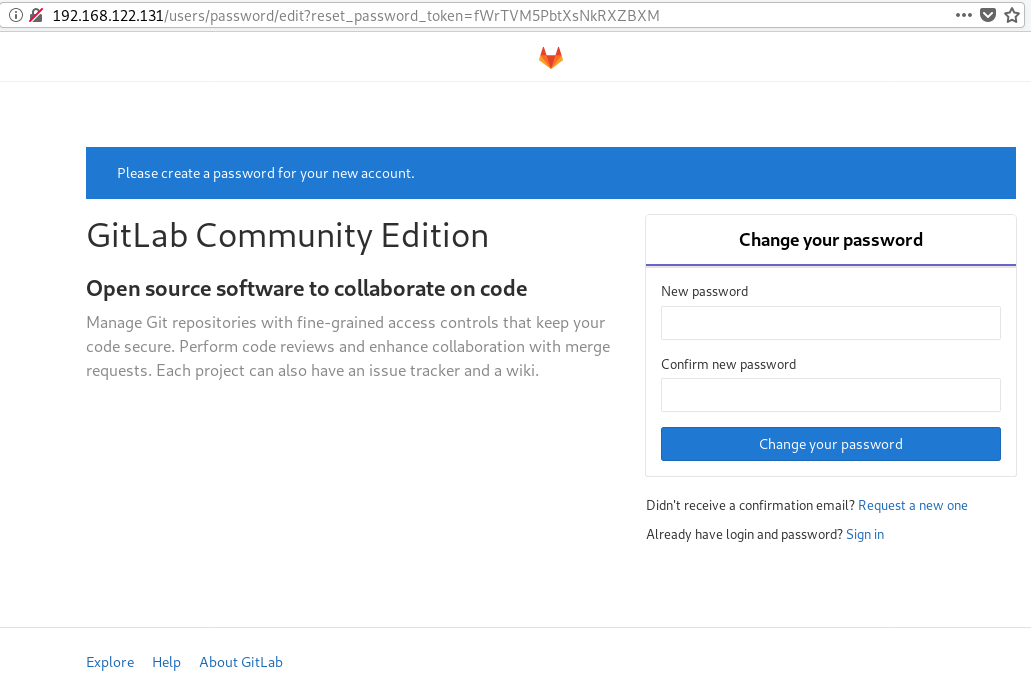
and your first action is to Create a new password by typing a password and hitting the Change your password button.
Login
First Page

New Project
I want to start this journey with a simple-to-build project, so I will try to build libsodium,
a modern, portable, easy to use crypto library.
New project --> Blank project
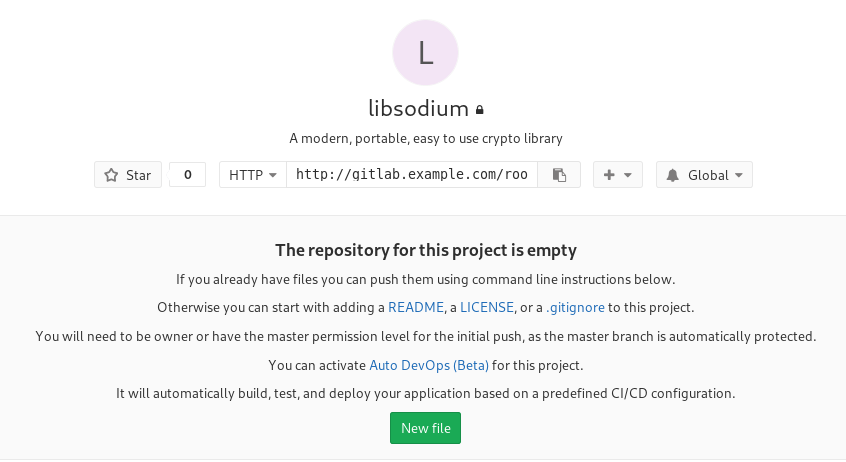
I will use this libsodium.spec file as the example for the CI/CD.
Docker
The idea is to build out custom rpm package of libsodium for CentOS 6, so we want to use docker containers through the gitlab CI/CD. We want clean & ephemeral images, so we will use containers as the building enviroments for the GitLab CI/CD.
Installing docker is really simple.
Installation
# yum -y install docker Run Docker
# systemctl restart docker
# systemctl enable dockerDownload image
Download a fresh CentOS v6 image from Docker Hub:
# docker pull centos:6 Trying to pull repository docker.io/library/centos ...
6: Pulling from docker.io/library/centos
ca9499a209fd: Pull complete
Digest: sha256:551de58ca434f5da1c7fc770c32c6a2897de33eb7fde7508e9149758e07d3fe3View Docker Images
# docker imagesREPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/centos 6 609c1f9b5406 7 weeks ago 194.5 MBGitlab Runner
Now, it is time to install and setup GitLab Runner.
In a nutshell this program, that is written in golang, will listen to every change on our repository and run every job that it can find on our yml file. But lets start with the installation:
# curl -s 'https://packages.gitlab.com/install/repositories/runner/gitlab-runner/config_file.repo?os=centos&dist=7&source=script' \
-o /etc/yum.repos.d/gitlab-runner.repo
# yum -y install gitlab-runnerGitLab Runner Settings
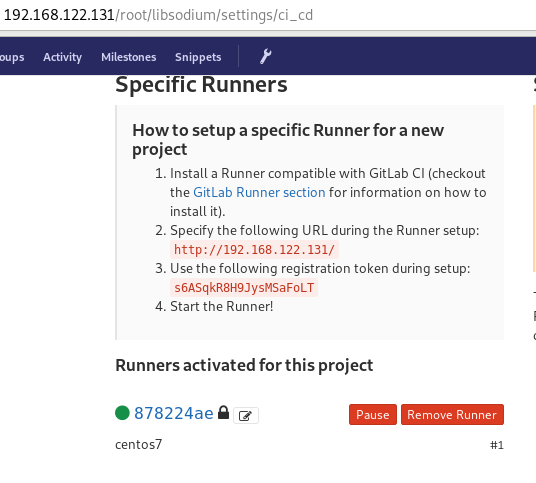
We need to connect our project with the gitlab-runner.
Project --> Settings --> CI/CDor in our example:
http://192.168.122.131/root/libsodium/settings/ci_cd
click on the expand button on Runner’s settings and you should see something like this:

Register GitLab Runner
Type into your terminal:
# gitlab-runner registerfollowing the instructions
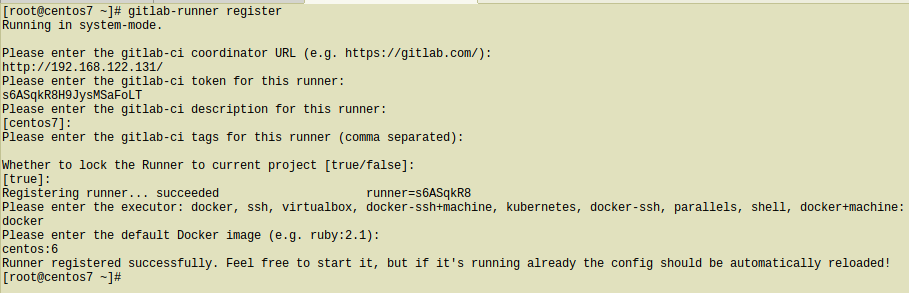
[root@centos7 ~]# gitlab-runner register
Running in system-mode.
Please enter the gitlab-ci coordinator URL (e.g. https://gitlab.com/):
http://192.168.122.131/
Please enter the gitlab-ci token for this runner:
s6ASqkR8H9JysMSaFoLT
Please enter the gitlab-ci description for this runner:
[centos7]:
Please enter the gitlab-ci tags for this runner (comma separated):
Whether to lock the Runner to current project [true/false]:
[true]:
Registering runner... succeeded runner=s6ASqkR8
Please enter the executor: docker, ssh, virtualbox, docker-ssh+machine, kubernetes, docker-ssh, parallels, shell, docker+machine:
docker
Please enter the default Docker image (e.g. ruby:2.1):
centos:6
Runner registered successfully. Feel free to start it, but if it's running already the config should be automatically reloaded!
[root@centos7 ~]#
by refreshing the previous page we will see a new active runner on our project.
The Docker executor
We are ready to setup our first executor to our project. That means we are ready to run our first CI/CD example!
In gitlab this is super easy, just add a
New file --> Template --> gitlab-ci.yml --> based on bashDont forget to change the image from busybox:latest to centos:6

that will start a pipeline
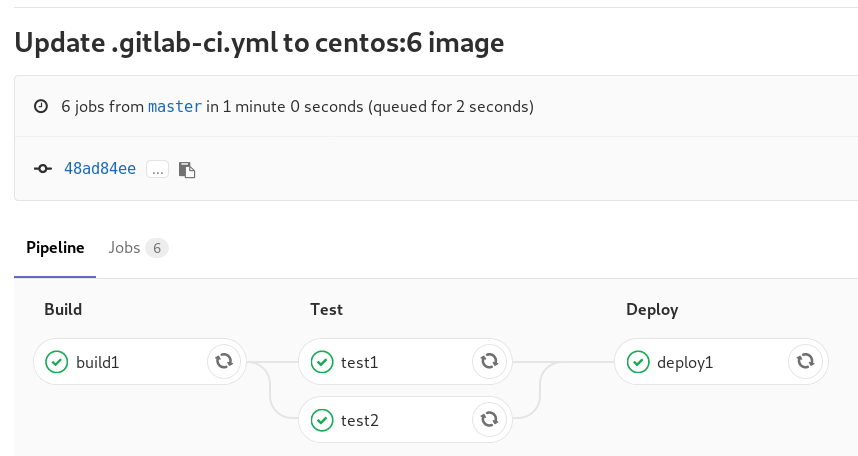
GitLab Continuous Integration
Below is a gitlab ci test file that builds the rpm libsodium :
.gitlab-ci.yml
image: centos:6
before_script:
- echo "Get the libsodium version and name from the rpm spec file"
- export LIBSODIUM_VERS=$(egrep '^Version:' libsodium.spec | awk '{print $NF}')
- export LIBSODIUM_NAME=$(egrep '^Name:' libsodium.spec | awk '{print $NF}')
run-build:
stage: build
artifacts:
untracked: true
script:
- echo "Install rpm-build package"
- yum -y install rpm-build
- echo "Install BuildRequires"
- yum -y install gcc
- echo "Create rpmbuild directories"
- mkdir -p rpmbuild/{BUILD,RPMS,SOURCES,SPECS,SRPMS}
- echo "Download source file from github"
- curl -s -L https://github.com/jedisct1/$LIBSODIUM_NAME/releases/download/$LIBSODIUM_VERS/$LIBSODIUM_NAME-$LIBSODIUM_VERS.tar.gz -o rpmbuild/SOURCES/$LIBSODIUM_NAME-$LIBSODIUM_VERS.tar.gz
- rpmbuild -D "_topdir `pwd`/rpmbuild" --clean -ba `pwd`/libsodium.spec
run-test:
stage: test
script:
- echo "Test it, Just test it !"
- yum -y install rpmbuild/RPMS/x86_64/$LIBSODIUM_NAME-$LIBSODIUM_VERS-*.rpm
run-deploy:
stage: deploy
script:
- echo "Do your deploy here"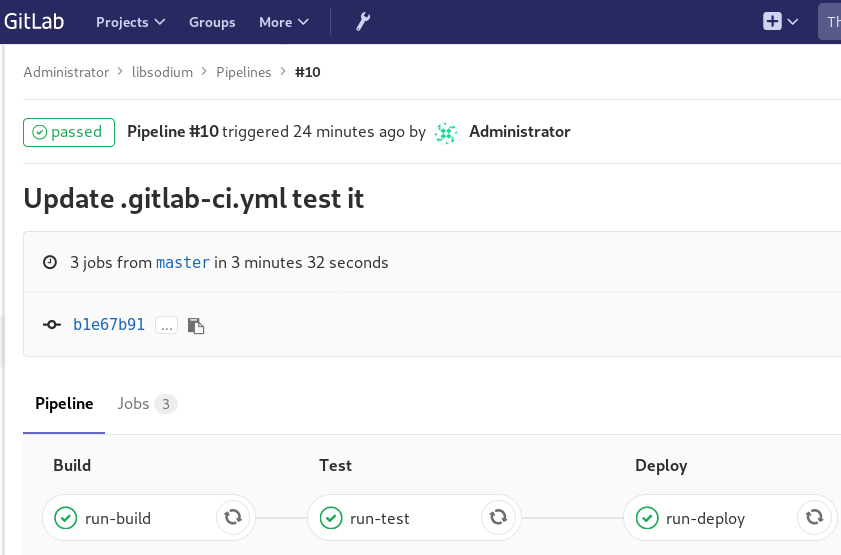
GitLab Artifacts
Before we continue I need to talk about artifacts
Artifacts is a list of files and directories that we produce at stage jobs and are not part of the git repository. We can pass those artifacts between stages, but you have to remember that gitlab can track files that only exist under the git-clone repository and not on the root fs of the docker image.
GitLab Continuous Delivery
We have successfully build an rpm file!! Time to deploy it to another machine. To do that, we need to add the secure shell private key to gitlab secret variables.
Project --> Settings --> CI/CD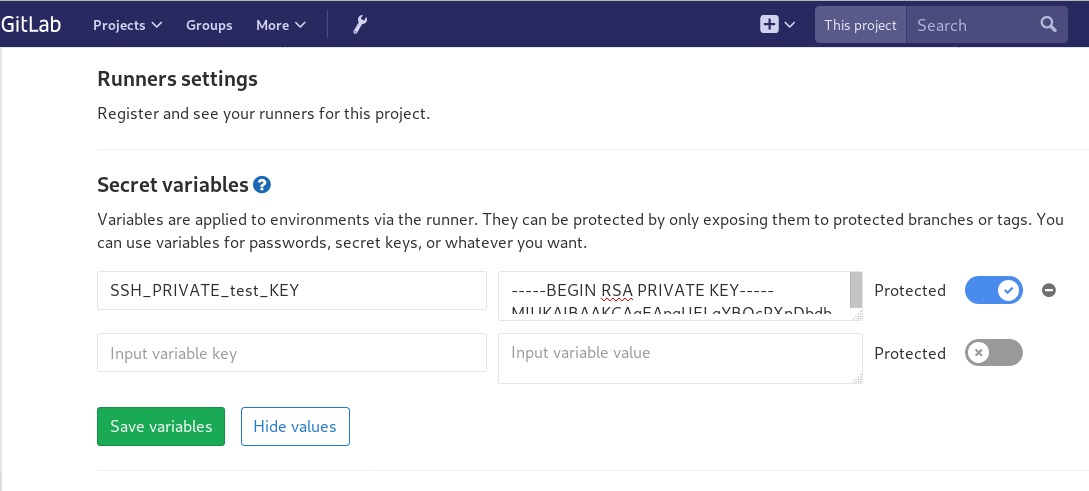
stage: deploy
Lets re-write gitlab deployment state:
variables:
DESTINATION_SERVER: '192.168.122.132'
run-deploy:
stage: deploy
script:
- echo "Create ssh root directory"
- mkdir -p ~/.ssh/ && chmod 700 ~/.ssh/
- echo "Append secret variable to the ssh private key file"
- echo -e "$SSH_PRIVATE_test_KEY" > ~/.ssh/id_rsa
- chmod 0600 ~/.ssh/id_rsa
- echo "Install SSH client"
- yum -y install openssh-clients
- echo "Secure Copy the libsodium rpm file to the destination server"
- scp -o StrictHostKeyChecking=no rpmbuild/RPMS/x86_64/$LIBSODIUM_NAME-$LIBSODIUM_VERS-*.rpm $DESTINATION_SERVER:/tmp/
- echo "Install libsodium rpm file to the destination server"
- ssh -o StrictHostKeyChecking=no $DESTINATION_SERVER yum -y install /tmp/$LIBSODIUM_NAME-$LIBSODIUM_VERS-*.rpm
and we can see that our pipeline has passed!
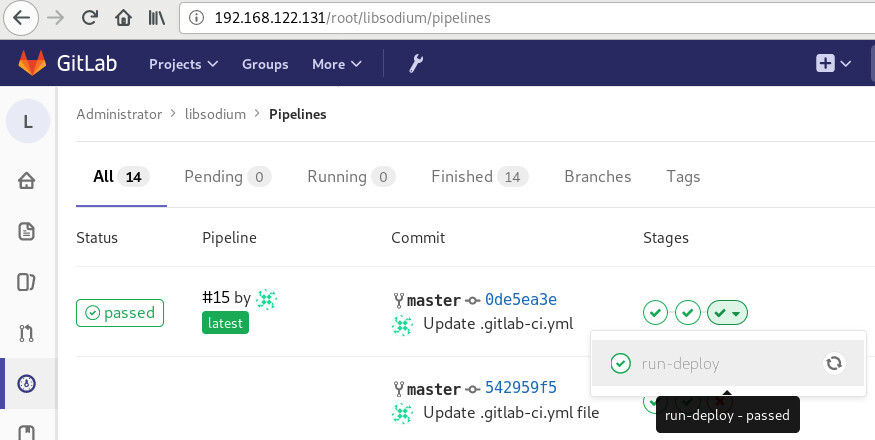
Possible Problems:
that will probable fail!
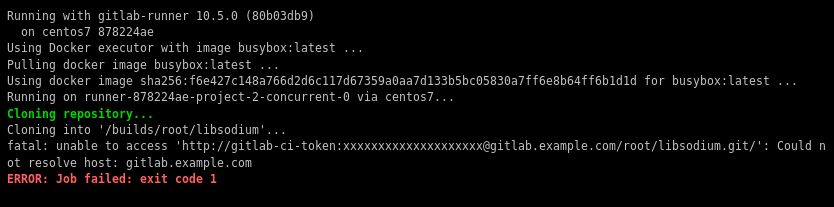
because our docker images don’t recognize gitlab.example.com.
Disclaimer: If you are using real fqdn - ip then you will probably not face this problem. I am referring to this issue, only for people who will follow this article step by step.
Easy fix:
# export -p EXTERNAL_URL="http://192.168.122.131" && yum -y reinstall gitlab-ceGitLab Runner
GitLab Runner is not running !
# gitlab-runner verify
Running in system-mode.
Verifying runner... is alive runner=e9bbcf90
Verifying runner... is alive runner=77701bad
# gitlab-runner status
gitlab-runner: Service is not running.
# gitlab-runner install -u gitlab-runner -d /home/gitlab-runner/
# systemctl is-active gitlab-runner
inactive
# systemctl enable gitlab-runner
# systemctl start gitlab-runner
# systemctl is-active gitlab-runner
active
# systemctl | egrep gitlab-runner
gitlab-runner.service loaded active running GitLab Runner
# gitlab-runner status
gitlab-runner: Service is running!
# ps -e fuwww | egrep -i gitlab-[r]unner
root 5116 0.4 0.1 63428 16968 ? Ssl 07:44 0:00 /usr/bin/gitlab-runner run --working-directory /home/gitlab-runner/ --config /etc/gitlab-runner/config.toml --service gitlab-runner --syslog --user gitlab-runner
Encrypted files in Dropbox
As we live in the age of smartphones and mobility access to the cloud, the more there is the need to access our files from anywhere. We need our files to be available on any computer, ours (private) or others (public). Traveling with your entire tech equipment is not always a good idea and with the era of cloud you dont need to bring everything with you.
There are a lot of cloud hosting files providers out there. On wikipedia there is a good Comparison of file hosting services article you can read.
I’ve started to use Dropbox for that reason. I use dropbox as a public digital bucket, to store and share public files. Every digital asset that is online is somehow public and only when you are using end-to-end encryption then you can say that something is more secure than before.
I also want to store some encrypted files on my cloud account, without the need to trust dropbox (or any cloud hosting file provider for that reason). As an extra security layer on top of dropbox, I use encfs and this blog post is a mini tutorial of a proof of concept.
EncFS - Encrypted Virtual Filesystem
(definition from encfs github account)
EncFS creates a virtual encrypted filesystem which stores encrypted data in the rootdir directory and makes the unencrypted data visible at the mountPoint directory. The user must supply a password which is used to (indirectly) encrypt both filenames and file contents.
That means that you can store your encrypted files somewhere and mount the decrypted files on folder on your computer.
Disclaimer: I dont know how secure is encfs. It is an extra layer that doesnt need any root access (except the installation part) for end users and it is really simple to use. There is a useful answer on stackexchange that you night like to read .
For more information on enfs you can also visit EncFS - Wikipedia Page
Install EncFS
-
archlinux
$ sudo pacman -S --noconfirm encfs -
fedora
$ sudo dnf -y install fuse-encfs -
ubuntu
$ sudo apt-get install -y encfs
How does Encfs work ?
- You have two(2) directories. The source and the mountpoint.
- You encrypt and store the files in the source directory with a password.
- You can view/edit your files in cleartext, in the mount point.
-
Create a folder inside dropbox
eg./home/ebal/Dropbox/Boostnote -
Create a folder outside of dropbox
eg./home/ebal/Boostnote
both folders are complete empty.
- Choose a long password.
just for testing, I am using a SHA256 message digest from an image that I can found on the internet!
eg.sha256sum /home/ebal/secret.png
that means, I dont know the password but I can re-create it whenever I hash the image.
BE Careful This suggestion is an example - only for testing. The proper way is to use a random generated long password from your key password manager eg. KeePassX
How does dropbox works?
The dropbox-client is monitoring your /home/ebal/Dropbox/ directory for any changes so that can sync your files on your account.
You dont need dropbox running to use encfs.
Running the dropbox-client is the easiest way, but you can always use a sync client eg. rclone to sync your encrypted file to dropbox (or any cloud storage).
I guess it depends on your thread model. For this proof-of-concept article I run dropbox-client daemon in my background.

Create and Mount
Now is the time to mount the source directory inside dropbox with our mount point:
$ sha256sum /home/ebal/secret.png |
awk '{print $1}' |
encfs -S -s -f /home/ebal/Dropbox/Boostnote/ /home/ebal/Boostnote/Reminder: EncFs works with absolute paths!
Check Mount Point
$ mount | egrep -i encfsencfs on /home/ebal/Boostnote type fuse.encfs
(rw,nosuid,nodev,relatime,user_id=1001,group_id=1001,default_permissions)View Files on Dropbox
Files inside dropbox:
View Files on the Mount Point

Unmount EncFS Mount Point
When you mount the source directory, encfs has an option to auto-umount the mount point on idle.
Or you can use the below command on demand:
$ fusermount -u /home/ebal/BoostnoteOn another PC
The simplicity of this approach is when you want to access these files on another PC.
dropbox-client has already synced your encrypted files.
So the only thing you have to do, is to type on this new machine the exact same command as in Create & Mount chapter.
$ sha256sum /home/ebal/secret.png |
awk '{print $1}' |
encfs -S -s -f /home/ebal/Dropbox/Boostnote/ /home/ebal/Boostnote/Android
How about Android ?
You can use Cryptonite.
Cryptonite can use EncFS and TrueCrypt on Android and you can find the app on Google Play



I’ve listened two audiobooks this month, both on DevOps methodology or more accurate on continuous improving of streamflow.
also started audible - amazon for listening audiobooks. The android app is not great but decent enough, although most of the books are DRM.
The first one is The Goal - A Process of Ongoing Improvement by: Eliyahu M. Goldratt, Jeff Cox
I can not stress this enough: You Have To Read this book. This novel is been categorized under business and it is been written back in 1984. You will find innovating even for today’s business logic. This book is the bases of “The Phoenix Project” and you have to read it before the The Phoenix Project. You will understand in details how lean and agile methodologies drive us to DevOps as a result of Ongoing Improvement.
https://www.audible.com/pd/Business/The-Goal-Audiobook/B00IFG88SM
The second book is The DevOps Handbook or How to Create World-Class Agility, Reliability, and Security in Technology Organizations by By: Gene Kim, Patrick Debois, John Willis, Jez Humble Narrated by: Ron Butler
I have this book in both hardcopy and audiobook. It is indeed a handbook. If you are just now starting on devops you need to read it. Has stories of companies that have applied the devops practices and It is really well structured. My suggestion is to keep notes when reading/listening to this book. Keep notes and re-read them.
https://www.audible.com/pd/Business/The-DevOps-Handbook-Audiobook/B0767HHZLZ
systemd
Latest systemd version now contains the systemd-importd daemon .
That means that we can use machinectl to import a tar or a raw image from the internet to use it with the systemd-nspawn command.
so here is an example
machinectl
from my archlinux box:
# cat /etc/arch-release
Arch Linux releaseCentOS 7
We can download the tar centos7 docker image from the docker hub registry:
# machinectl pull-tar --verify=no https://github.com/CentOS/sig-cloud-instance-images/raw/79db851f4016c283fb3d30f924031f5a866d51a1/docker/centos-7-docker.tar.xz
...
Created new local image 'centos-7-docker'.
Operation completed successfully.
Exiting.we can verify that:
# ls -la /var/lib/machines/centos-7-docker
total 28
dr-xr-xr-x 1 root root 158 Jan 7 18:59 .
drwx------ 1 root root 488 Feb 1 21:17 ..
-rw-r--r-- 1 root root 11970 Jan 7 18:59 anaconda-post.log
lrwxrwxrwx 1 root root 7 Jan 7 18:58 bin -> usr/bin
drwxr-xr-x 1 root root 0 Jan 7 18:58 dev
drwxr-xr-x 1 root root 1940 Jan 7 18:59 etc
drwxr-xr-x 1 root root 0 Nov 5 2016 home
lrwxrwxrwx 1 root root 7 Jan 7 18:58 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Jan 7 18:58 lib64 -> usr/lib64
drwxr-xr-x 1 root root 0 Nov 5 2016 media
drwxr-xr-x 1 root root 0 Nov 5 2016 mnt
drwxr-xr-x 1 root root 0 Nov 5 2016 opt
drwxr-xr-x 1 root root 0 Jan 7 18:58 proc
dr-xr-x--- 1 root root 120 Jan 7 18:59 root
drwxr-xr-x 1 root root 104 Jan 7 18:59 run
lrwxrwxrwx 1 root root 8 Jan 7 18:58 sbin -> usr/sbin
drwxr-xr-x 1 root root 0 Nov 5 2016 srv
drwxr-xr-x 1 root root 0 Jan 7 18:58 sys
drwxrwxrwt 1 root root 140 Jan 7 18:59 tmp
drwxr-xr-x 1 root root 106 Jan 7 18:58 usr
drwxr-xr-x 1 root root 160 Jan 7 18:58 var
systemd-nspawn
Now test we can test it:
[root@myhomepc ~]# systemd-nspawn --machine=centos-7-docker
Spawning container centos-7-docker on /var/lib/machines/centos-7-docker.
Press ^] three times within 1s to kill container.
[root@centos-7-docker ~]#
[root@centos-7-docker ~]#
[root@centos-7-docker ~]# cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
[root@centos-7-docker ~]#
[root@centos-7-docker ~]# exit
logout
Container centos-7-docker exited successfully.
and now returning to our system:
[root@myhomepc ~]#
[root@myhomepc ~]#
[root@myhomepc ~]# cat /etc/arch-release
Arch Linux release
Ubuntu 16.04.4 LTS
ubuntu example:
# machinectl pull-tar --verify=no https://github.com/tianon/docker-brew-ubuntu-core/raw/46511cf49ad5d2628f3e8d88e1f8b18699a3ad8f/xenial/ubuntu-xenial-core-cloudimg-amd64-root.tar.gz
# systemd-nspawn --machine=ubuntu-xenial-core-cloudimg-amd64-rootSpawning container ubuntu-xenial-core-cloudimg-amd64-root on /var/lib/machines/ubuntu-xenial-core-cloudimg-amd64-root.
Press ^] three times within 1s to kill container.
Timezone Europe/Athens does not exist in container, not updating container timezone.
root@ubuntu-xenial-core-cloudimg-amd64-root:~# root@ubuntu-xenial-core-cloudimg-amd64-root:~# cat /etc/os-release NAME="Ubuntu"
VERSION="16.04.4 LTS (Xenial Xerus)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 16.04.4 LTS"
VERSION_ID="16.04"
HOME_URL="http://www.ubuntu.com/"
SUPPORT_URL="http://help.ubuntu.com/"
BUG_REPORT_URL="http://bugs.launchpad.net/ubuntu/"
VERSION_CODENAME=xenial
UBUNTU_CODENAME=xenialroot@ubuntu-xenial-core-cloudimg-amd64-root:~# exitlogout
Container ubuntu-xenial-core-cloudimg-amd64-root exited successfully.# cat /etc/os-release NAME="Arch Linux"
PRETTY_NAME="Arch Linux"
ID=arch
ID_LIKE=archlinux
ANSI_COLOR="0;36"
HOME_URL="https://www.archlinux.org/"
SUPPORT_URL="https://bbs.archlinux.org/"
BUG_REPORT_URL="https://bugs.archlinux.org/"Network-Bound Disk Encryption
I was reading the redhat release notes on 7.4 and came across: Chapter 15. Security
New packages: tang, clevis, jose, luksmeta
Network Bound Disk Encryption (NBDE) allows the user to encrypt root volumes of the hard drives on physical and virtual machines without requiring to manually enter password when systems are rebooted.
That means, we can now have an encrypted (luks) volume that will be de-crypted on reboot, without the need of typing a passphrase!!!
Really - really useful on VPS (and general in cloud infrastructures)
Useful Links
- https://github.com/latchset/tang
- https://github.com/latchset/jose
- https://github.com/latchset/clevis
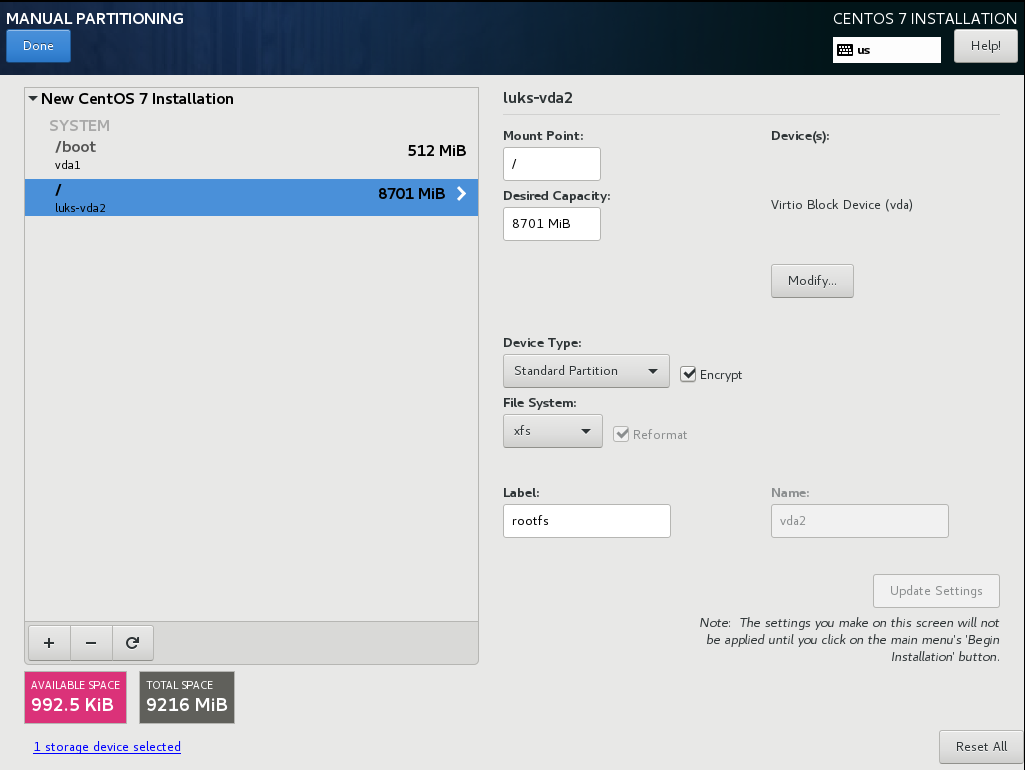
CentOS 7.4 with Encrypted rootfs
(aka client machine)
Below is a test centos 7.4 virtual machine with an encrypted root filesystem:
/boot
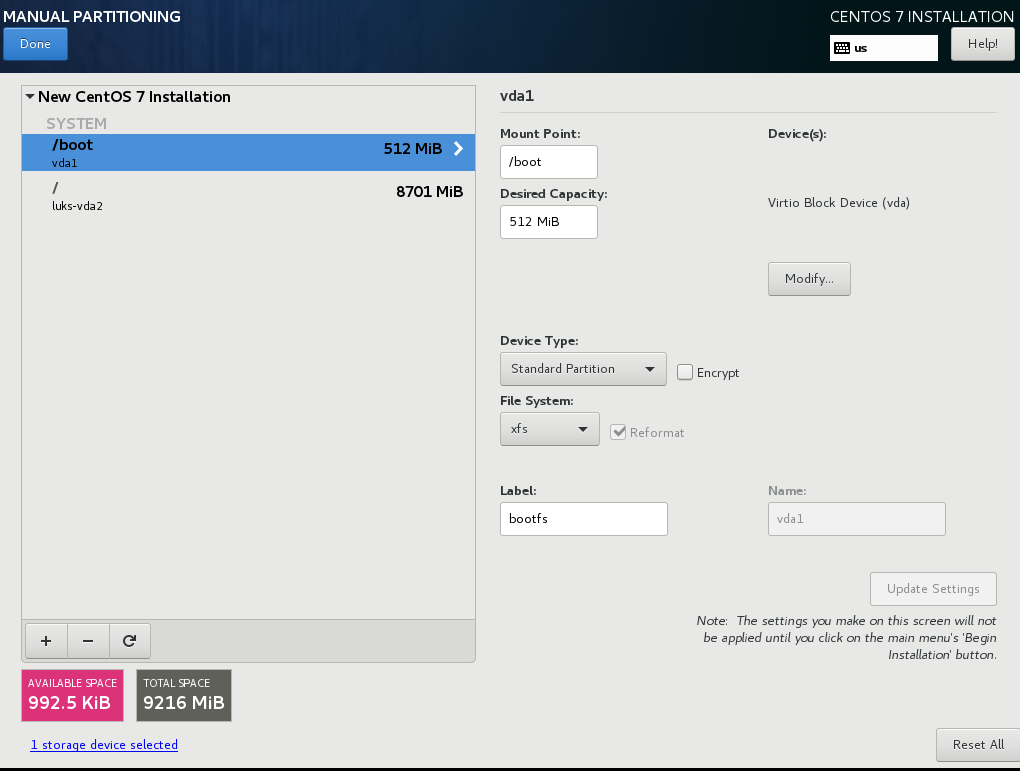
/
Tang Server
(aka server machine)
Tang is a server for binding data to network presence. This is a different centos 7.4 virtual machine from the above.
Installation
Let’s install the server part:
# yum -y install tang
Start socket service:
# systemctl restart tangd.socket
Enable socket service:
# systemctl enable tangd.socket
TCP Port
Check that the tang server is listening:
# netstat -ntulp | egrep -i systemd
tcp6 0 0 :::80 :::* LISTEN 1/systemdFirewall
Dont forget the firewall:
Firewall Zones
# firewall-cmd --get-active-zones
public
interfaces: eth0
Firewall Port
# firewall-cmd --zone=public --add-port=80/tcp --permanent
or
# firewall-cmd --add-port=80/tcp --permanent
successReload
# firewall-cmd --reload
successWe have finished with the server part!
Client Machine - Encrypted rootfs
Now it is time to configure the client machine, but before let’s check the encrypted partition:
CryptTab
Every encrypted block devices is configured under crypttab file:
[root@centos7 ~]# cat /etc/crypttab
luks-3cc09d38-2f55-42b1-b0c7-b12f6c74200c UUID=3cc09d38-2f55-42b1-b0c7-b12f6c74200c none FsTab
and every filesystem that is static mounted on boot, is configured under fstab:
[root@centos7 ~]# cat /etc/fstab
UUID=c5ffbb05-d8e4-458c-9dc6-97723ccf43bc /boot xfs defaults 0 0
/dev/mapper/luks-3cc09d38-2f55-42b1-b0c7-b12f6c74200c / xfs defaults,x-systemd.device-timeout=0 0 0Installation
Now let’s install the client (clevis) part that will talk with tang:
# yum -y install clevis clevis-luks clevis-dracut
Configuration
with a very simple command:
# clevis bind luks -d /dev/vda2 tang '{"url":"http://192.168.122.194"}'
The advertisement contains the following signing keys:
FYquzVHwdsGXByX_rRwm0VEmFRo
Do you wish to trust these keys? [ynYN] y
You are about to initialize a LUKS device for metadata storage.
Attempting to initialize it may result in data loss if data was
already written into the LUKS header gap in a different format.
A backup is advised before initialization is performed.
Do you wish to initialize /dev/vda2? [yn] y
Enter existing LUKS password:
we’ve just configured our encrypted volume against tang!
Luks MetaData
We can verify it’s luks metadata with:
[root@centos7 ~]# luksmeta show -d /dev/vda2
0 active empty
1 active cb6e8904-81ff-40da-a84a-07ab9ab5715e
2 inactive empty
3 inactive empty
4 inactive empty
5 inactive empty
6 inactive empty
7 inactive empty
dracut
We must not forget to regenerate the initramfs image, that on boot will try to talk with our tang server:
[root@centos7 ~]# dracut -f
Reboot
Now it’s time to reboot!
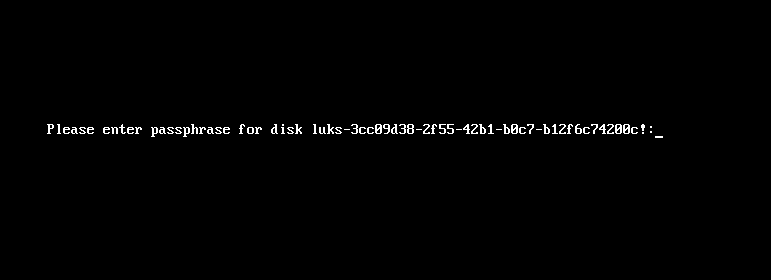
A short msg will appear in our screen, but in a few seconds and if successfully exchange messages with the tang server, our server with de-crypt the rootfs volume.

Tang messages
To finish this article, I will show you some tang msg via journalct:
Initialization
Getting the signing key from the client on setup:
Jan 31 22:43:09 centos7 systemd[1]: Started Tang Server (192.168.122.195:58088).
Jan 31 22:43:09 centos7 systemd[1]: Starting Tang Server (192.168.122.195:58088)...
Jan 31 22:43:09 centos7 tangd[1219]: 192.168.122.195 GET /adv/ => 200 (src/tangd.c:85)reboot
Client is trying to decrypt the encrypted volume on reboot
Jan 31 22:46:21 centos7 systemd[1]: Started Tang Server (192.168.122.162:42370).
Jan 31 22:46:21 centos7 systemd[1]: Starting Tang Server (192.168.122.162:42370)...
Jan 31 22:46:22 centos7 tangd[1223]: 192.168.122.162 POST /rec/Shdayp69IdGNzEMnZkJasfGLIjQ => 200 (src/tangd.c:168)
Ready Player One by Ernest Cline
I’ve listened to the audiobook, Narrated by Wil Wheaton.
The book is AMAZING! Taking a trip down memory lane to ’80s pop culture, video games, music & movies. A sci-fi futuristic book that online gamers are trying to solve puzzles on a easter egg hunt for the control of oasis, a virtual reality game.

You can find more info here
Fabric
Fabric is a Python (2.5-2.7) library and command-line tool for streamlining the use of SSH for application deployment or systems administration tasks.
You can find the documentation here
Installation
# yum -y install epel-release
# yum -y install fabric
Hello World
# cat > fabfile.py <<EOF
> def hello():
> print("Hello world!")
>
> EOFand run it
# fab hello -f ./fabfile.py
Hello world!
Done.A more complicated example
def HelloWorld():
print("Hello world!")
def hello(name="world"):
print("Hello %s!" % name )# fab HelloWorld -f ./fabfile.py
Hello world!
Done.
# fab hello -f ./fabfile.py
Hello world!
Done.
# fab hello:name=ebal -f ./fabfile.py
Hello ebal!
Done.
A remote example
from fabric.api import run , env
env.use_ssh_config = True
def HelloWorld():
print("Hello world!")
def hello(name="world"):
print("Hello %s!" % name )
def uptime():
run('uptime')
ssh configuration file
with the below variable declaration
(just remember to import env)
fabric can use the ssh configuration file of your system
env.use_ssh_config = Trueand run it against server test
$ fab -H test uptime -f ./fabfile.py
[test] Executing task 'uptime'
[test] run: uptime
[test] out: 20:21:30 up 10 days, 11 min, 1 user, load average: 0.00, 0.00, 0.00
[test] out:
Done.
Disconnecting from 192.168.122.1:22... done.2FA SSH aka OpenSSH OATH, Two-Factor Authentication
prologue
Good security is based on layers of protection. At some point the usability gets in the way. My thread model on accessing systems is to create a different ssh pair of keys (private/public) and only use them instead of a login password. I try to keep my digital assets separated and not all of them under the same basket. My laptop is encrypted and I dont run any services on it, but even then a bad actor can always find a way.
Back in the days, I was looking on Barada/Gort. Barada is an implementation of HOTP: An HMAC-Based One-Time Password Algorithm and Gort is the android app you can install to your mobile and connect to barada. Both of these application have not been updated since 2013/2014 and Gort is even removed from f-droid!
Talking with friends on our upcoming trip to 34C4, discussing some security subjects, I thought it was time to review my previous inquiry on ssh-2FA. Most of my friends are using yubikeys. I would love to try some, but at this time I dont have the time to order/test/apply to my machines. To reduce any risk, the idea of combining a bastion/jump-host server with 2FA seemed to be an easy and affordable solution.
OpenSSH with OATH
As ssh login is based on PAM (Pluggable Authentication Modules), we can use Gnu OATH Toolkit. OATH stands for Open Authentication and it is an open standard. In a nutshell, we add a new authorization step that we can verify our login via our mobile device.
Below are my personal notes on how to setup oath-toolkit, oath-pam and how to synchronize it against your android device. These are based on centos 6.9
EPEL
We need to install the epel repository:
# yum -y install https://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
Searching packages
Searching for oath
# yum search oath
the results are similar to these:
liboath.x86_64 : Library for OATH handling
liboath-devel.x86_64 : Development files for liboath
liboath-doc.noarch : Documentation files for liboath
pam_oath.x86_64 : A PAM module for pluggable login authentication for OATH
gen-oath-safe.noarch : Script for generating HOTP/TOTP keys (and QR code)
oathtool.x86_64 : A command line tool for generating and validating OTPs
Installing packages
We need to install three packages:
- pam_oath is the PAM for OATH
- oathtool is the gnu oath-toolkit
- gen-oath-safe is the program that we will use to sync our mobile device with our system
# yum -y install pam_oath oathtool gen-oath-safe
FreeOTP
Before we continue with our setup, I believe now is the time to install FreeOTP

FreeOTP looks like:

HOTP
Now, it is time to generate and sync our 2FA, using HOTP
Generate
You should replace username with your USER_NAME !
# gen-oath-safe username HOTP

Sync
and scan the QR with FreeOTP

You can see in the top a new entry!

Save
Do not forget to save your HOTP key (hex) to the gnu oath-toolkit user file.
eg.
Key in Hex: e9379dd63ec367ee5c378a7c6515af01cf650c89
# echo "HOTP username - e9379dd63ec367ee5c378a7c6515af01cf650c89" > /etc/liboath/oathuserfile
verify:
# cat /etc/liboath/oathuserfile
HOTP username - e9379dd63ec367ee5c378a7c6515af01cf650c89OpenSSH
The penultimate step is to setup our ssh login with the PAM oath library.
Verify PAM
# ls -l /usr/lib64/security/pam_oath.so
-rwxr-xr-x 1 root root 11304 Nov 11 2014 /usr/lib64/security/pam_oath.soSSHD-PAM
# cat /etc/pam.d/sshd
In modern systems, the sshd pam configuration file seems:
#%PAM-1.0
auth required pam_sepermit.so
auth include password-auth
account required pam_nologin.so
account include password-auth
password include password-auth
# pam_selinux.so close should be the first session rule
session required pam_selinux.so close
session required pam_loginuid.so
# pam_selinux.so open should only be followed by sessions to be executed in the user context
session required pam_selinux.so open env_params
session required pam_namespace.so
session optional pam_keyinit.so force revoke
session include password-authWe need one line in the top of the file.
I use something like this:
auth sufficient /usr/lib64/security/pam_oath.so debug usersfile=/etc/liboath/oathuserfile window=5 digits=6
Depending on your policy and thread model, you can switch sufficient to requisite , you can remove debug option. In the third field, you can try typing just the pam_path.so without the full path and you can change the window to something else:
eg.
auth requisite pam_oath.so usersfile=/etc/liboath/oathuserfile window=10 digits=6Restart sshd
In every change/test remember to restart your ssh daemon:
# service sshd restart
Stopping sshd: [ OK ]
Starting sshd: [ OK ]SELINUX
If you are getting some weird messages, try to change the status of selinux to permissive and try again. If the selinux is the issue, you have to review selinux audit logs and add/fix any selinux policies/modules so that your system can work properly.
# getenforce
Enforcing
# setenforce 0
# getenforce
PermissiveTesting
The last and most important thing, is to test it !

Links
- 34C3 - https://events.ccc.de/congress/2017/wiki/index.php/Main_Page
- HOTP - https://tools.ietf.org/html/rfc4226
- OATH - https://openauthentication.org/
- FreeOTP - https://freeotp.github.io
- Gnu OATH ToolKit - http://www.nongnu.org/oath-toolkit/index.html
- PAM - https://www.linux.com/news/understanding-pam
Post Scriptum
The idea of using OATH & FreeOTP can also be applied to login into your laptop as PAM is the basic authentication framework on a linux machine. You can use OATH in every service that can authenticate it self through PAM.
How to install Signal dekstop to archlinux
Download Signal Desktop
eg. latest version v1.0.41
$ curl -s https://updates.signal.org/desktop/apt/pool/main/s/signal-desktop/signal-desktop_1.0.41_amd64.deb \
-o /tmp/signal-desktop_1.0.41_amd64.debVerify Package
There is a way to manually verify the integrity of the package, by checking the hash value of the file against a gpg signed file. To do that we need to add a few extra steps in our procedure.
Download Key from the repository
$ wget -c https://updates.signal.org/desktop/apt/keys.asc
--2017-12-11 22:13:34-- https://updates.signal.org/desktop/apt/keys.asc
Loaded CA certificate '/etc/ssl/certs/ca-certificates.crt'
Connecting to 127.0.0.1:8118... connected.
Proxy request sent, awaiting response... 200 OK
Length: 3090 (3.0K) [application/pgp-signature]
Saving to: ‘keys.asc’
keys.asc 100%[============================================================>] 3.02K --.-KB/s in 0s
2017-12-11 22:13:35 (160 MB/s) - ‘keys.asc’ saved [3090/3090]Import the key to your gpg keyring
$ gpg2 --import keys.asc
gpg: key D980A17457F6FB06: public key "Open Whisper Systems <support@whispersystems.org>" imported
gpg: Total number processed: 1
gpg: imported: 1you can also verify/get public key from a known key server
$ gpg2 --verbose --keyserver pgp.mit.edu --recv-keys 0xD980A17457F6FB06
gpg: data source: http://pgp.mit.edu:11371
gpg: armor header: Version: SKS 1.1.6
gpg: armor header: Comment: Hostname: pgp.mit.edu
gpg: pub rsa4096/D980A17457F6FB06 2017-04-05 Open Whisper Systems <support@whispersystems.org>
gpg: key D980A17457F6FB06: "Open Whisper Systems <support@whispersystems.org>" not changed
gpg: Total number processed: 1
gpg: unchanged: 1Here is already in place, so no changes.
Download Release files
$ wget -c https://updates.signal.org/desktop/apt/dists/xenial/Release
$ wget -c https://updates.signal.org/desktop/apt/dists/xenial/Release.gpg
Verify Release files
$ gpg2 --no-default-keyring --verify Release.gpg Release
gpg: Signature made Sat 09 Dec 2017 04:11:06 AM EET
gpg: using RSA key D980A17457F6FB06
gpg: Good signature from "Open Whisper Systems <support@whispersystems.org>" [unknown]
gpg: WARNING: This key is not certified with a trusted signature!
gpg: There is no indication that the signature belongs to the owner.
Primary key fingerprint: DBA3 6B51 81D0 C816 F630 E889 D980 A174 57F6 FB06That means that Release file is signed from whispersystems and the integrity of the file is not changed/compromized.
Download Package File
We need one more file and that is the Package file that contains the hash values of the deb packages.
$ wget -c https://updates.signal.org/desktop/apt/dists/xenial/main/binary-amd64/Packages
But is this file compromized?
Let’s check it against Release file:
$ sha256sum Packages
ec74860e656db892ab38831dc5f274d54a10347934c140e2a3e637f34c402b78 Packages$ grep ec74860e656db892ab38831dc5f274d54a10347934c140e2a3e637f34c402b78 Release
ec74860e656db892ab38831dc5f274d54a10347934c140e2a3e637f34c402b78 1713 main/binary-amd64/Packagesyeay !
Verify deb Package
Finally we are now ready to manually verify the integrity of the deb package:
$ sha256sum signal-desktop_1.0.41_amd64.deb
9cf87647e21bbe0c1b81e66f88832fe2ec7e868bf594413eb96f0bf3633a3f25 signal-desktop_1.0.41_amd64.deb$ egrep 9cf87647e21bbe0c1b81e66f88832fe2ec7e868bf594413eb96f0bf3633a3f25 Packages
SHA256: 9cf87647e21bbe0c1b81e66f88832fe2ec7e868bf594413eb96f0bf3633a3f25Perfect, we are now ready to continue
Extract under tmp filesystem
$ cd /tmp/
$ ar vx signal-desktop_1.0.41_amd64.deb
x - debian-binary
x - control.tar.gz
x - data.tar.xzExtract data under tmp filesystem
$ tar xf data.tar.xz
Move Signal-Desktop under root filesystem
# sudo mv opt/Signal/ /opt/Signal/
Done
Actually, that’s it!
Run
Run signal-desktop as a regular user:
$ /opt/Signal/signal-desktop
Signal Desktop

Proxy
Define your proxy settings on your environment:
declare -x ftp_proxy="proxy.example.org:8080"
declare -x http_proxy="proxy.example.org:8080"
declare -x https_proxy="proxy.example.org:8080"Signal

The year is 2144. A group of anti-patent scientists are working to reverse engineer drugs in free labs, for (poor) people to have access to them. Agents of International Property Coalition are trying to find the lead pirate-scientist and stop any patent violation by any means necessary. In this era, without a franchise (citizenship) autonomous robots and people are slaves. But only a few of the bots have are autonomous. Even then, can they be free ? Can androids choose their own gender identity ? Transhumanism and extension life drugs are helping people to live a longer and better life.
A science fiction novel without Digital Rights Management (DRM).
Fighting Spam
Fighting email spam in modern times most of the times looks like this:

Rspamd
Rspamd is a rapid spam filtering system. Written in C with Lua script engine extension seems to be really fast and a really good solution for SOHO environments.
In this blog post, I'’ll try to present you a quickstart guide on working with rspamd on a CentOS 6.9 machine running postfix.
DISCLAIMER: This blog post is from a very technical point of view!
Installation
We are going to install rspamd via know rpm repositories:
Epel Repository
We need to install epel repository first:
# yum -y install http://fedora-mirror01.rbc.ru/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
Rspamd Repository
Now it is time to setup the rspamd repository:
# curl https://rspamd.com/rpm-stable/centos-6/rspamd.repo -o /etc/yum.repos.d/rspamd.repo
Install the gpg key
# rpm --import http://rspamd.com/rpm-stable/gpg.key
and verify the repository with # yum repolist
repo id repo name
base CentOS-6 - Base
epel Extra Packages for Enterprise Linux 6 - x86_64
extras CentOS-6 - Extras
rspamd Rspamd stable repository
updates CentOS-6 - UpdatesRpm
Now it is time to install rspamd to our linux box:
# yum -y install rspamd
# yum info rspamd
Name : rspamd
Arch : x86_64
Version : 1.6.3
Release : 1
Size : 8.7 M
Repo : installed
From repo : rspamd
Summary : Rapid spam filtering system
URL : https://rspamd.com
License : BSD2c
Description : Rspamd is a rapid, modular and lightweight spam filter. It is designed to work
: with big amount of mail and can be easily extended with own filters written in
: lua.
Init File
We need to correct rspamd init file so that rspamd can find the correct configuration file:
# vim /etc/init.d/rspamd
# ebal, Wed, 06 Sep 2017 00:31:37 +0300
## RSPAMD_CONF_FILE="/etc/rspamd/rspamd.sysvinit.conf"
RSPAMD_CONF_FILE="/etc/rspamd/rspamd.conf"or
# ln -s /etc/rspamd/rspamd.conf /etc/rspamd/rspamd.sysvinit.conf
Start Rspamd
We are now ready to start for the first time rspamd daemon:
# /etc/init.d/rspamd restart
syntax OK
Stopping rspamd: [FAILED]
Starting rspamd: [ OK ]verify that is running:
# ps -e fuwww | egrep -i rsp[a]md
root 1337 0.0 0.7 205564 7164 ? Ss 20:19 0:00 rspamd: main process
_rspamd 1339 0.0 0.7 206004 8068 ? S 20:19 0:00 _ rspamd: rspamd_proxy process
_rspamd 1340 0.2 1.2 209392 12584 ? S 20:19 0:00 _ rspamd: controller process
_rspamd 1341 0.0 1.0 208436 11076 ? S 20:19 0:00 _ rspamd: normal process perfect, now it is time to enable rspamd to run on boot:
# chkconfig rspamd on
# chkconfig --list | egrep rspamd
rspamd 0:off 1:off 2:on 3:on 4:on 5:on 6:offPostfix
In a nutshell, postfix will pass through (filter) an email using the milter protocol to another application before queuing it to one of postfix’s mail queues. Think milter as a bridge that connects two different applications.

Rspamd Proxy
In Rspamd 1.6 Rmilter is obsoleted but rspamd proxy worker supports milter protocol. That means we need to connect our postfix with rspamd_proxy via milter protocol.
Rspamd has a really nice documentation: https://rspamd.com/doc/index.html
On MTA integration you can find more info.
# netstat -ntlp | egrep -i rspamd
output:
tcp 0 0 0.0.0.0:11332 0.0.0.0:* LISTEN 1451/rspamd
tcp 0 0 0.0.0.0:11333 0.0.0.0:* LISTEN 1451/rspamd
tcp 0 0 127.0.0.1:11334 0.0.0.0:* LISTEN 1451/rspamd
tcp 0 0 :::11332 :::* LISTEN 1451/rspamd
tcp 0 0 :::11333 :::* LISTEN 1451/rspamd
tcp 0 0 ::1:11334 :::* LISTEN 1451/rspamd # egrep -A1 proxy /etc/rspamd/rspamd.conf
worker "rspamd_proxy" {
bind_socket = "*:11332";
.include "$CONFDIR/worker-proxy.inc"
.include(try=true; priority=1,duplicate=merge) "$LOCAL_CONFDIR/local.d/worker-proxy.inc"
.include(try=true; priority=10) "$LOCAL_CONFDIR/override.d/worker-proxy.inc"
}
Milter
If you want to know all the possibly configuration parameter on postfix for milter setup:
# postconf | egrep -i milter
output:
milter_command_timeout = 30s
milter_connect_macros = j {daemon_name} v
milter_connect_timeout = 30s
milter_content_timeout = 300s
milter_data_macros = i
milter_default_action = tempfail
milter_end_of_data_macros = i
milter_end_of_header_macros = i
milter_helo_macros = {tls_version} {cipher} {cipher_bits} {cert_subject} {cert_issuer}
milter_macro_daemon_name = $myhostname
milter_macro_v = $mail_name $mail_version
milter_mail_macros = i {auth_type} {auth_authen} {auth_author} {mail_addr} {mail_host} {mail_mailer}
milter_protocol = 6
milter_rcpt_macros = i {rcpt_addr} {rcpt_host} {rcpt_mailer}
milter_unknown_command_macros =
non_smtpd_milters =
smtpd_milters = We are mostly interested in the last two, but it is best to follow rspamd documentation:
# vim /etc/postfix/main.cf
Adding the below configuration lines:
# ebal, Sat, 09 Sep 2017 18:56:02 +0300
## A list of Milter (mail filter) applications for new mail that does not arrive via the Postfix smtpd(8) server.
on_smtpd_milters = inet:127.0.0.1:11332
## A list of Milter (mail filter) applications for new mail that arrives via the Postfix smtpd(8) server.
smtpd_milters = inet:127.0.0.1:11332
## Send macros to mail filter applications
milter_mail_macros = i {auth_type} {auth_authen} {auth_author} {mail_addr} {client_addr} {client_name} {mail_host} {mail_mailer}
## skip mail without checks if something goes wrong, like rspamd is down !
milter_default_action = accept
Reload postfix
# postfix reload
postfix/postfix-script: refreshing the Postfix mail systemTesting
netcat
From a client:
$ nc 192.168.122.96 25
220 centos69.localdomain ESMTP Postfix
EHLO centos69
250-centos69.localdomain
250-PIPELINING
250-SIZE 10240000
250-VRFY
250-ETRN
250-ENHANCEDSTATUSCODES
250-8BITMIME
250 DSN
MAIL FROM: <root@example.org>
250 2.1.0 Ok
RCPT TO: <root@localhost>
250 2.1.5 Ok
DATA
354 End data with <CR><LF>.<CR><LF>
test
.
250 2.0.0 Ok: queued as 4233520144
^]
Logs
Looking through logs may be a difficult task for many, even so it is a task that you have to do.
MailLog
# egrep 4233520144 /var/log/maillog
Sep 9 19:08:01 localhost postfix/smtpd[1960]: 4233520144: client=unknown[192.168.122.1]
Sep 9 19:08:05 localhost postfix/cleanup[1963]: 4233520144: message-id=<>
Sep 9 19:08:05 localhost postfix/qmgr[1932]: 4233520144: from=<root@example.org>, size=217, nrcpt=1 (queue active)
Sep 9 19:08:05 localhost postfix/local[1964]: 4233520144: to=<root@localhost.localdomain>, orig_to=<root@localhost>, relay=local, delay=12, delays=12/0.01/0/0.01, dsn=2.0.0, status=sent (delivered to mailbox)
Sep 9 19:08:05 localhost postfix/qmgr[1932]: 4233520144: removedEverything seems fine with postfix.
Rspamd Log
# egrep -i 4233520144 /var/log/rspamd/rspamd.log
2017-09-09 19:08:05 #1455(normal) <79a04e>; task; rspamd_message_parse: loaded message; id: <undef>; queue-id: <4233520144>; size: 6; checksum: <a6a8e3835061e53ed251c57ab4f22463>
2017-09-09 19:08:05 #1455(normal) <79a04e>; task; rspamd_task_write_log: id: <undef>, qid: <4233520144>, ip: 192.168.122.1, from: <root@example.org>, (default: F (add header): [9.40/15.00] [MISSING_MID(2.50){},MISSING_FROM(2.00){},MISSING_SUBJECT(2.00){},MISSING_TO(2.00){},MISSING_DATE(1.00){},MIME_GOOD(-0.10){text/plain;},ARC_NA(0.00){},FROM_NEQ_ENVFROM(0.00){;root@example.org;},RCVD_COUNT_ZERO(0.00){0;},RCVD_TLS_ALL(0.00){}]), len: 6, time: 87.992ms real, 4.723ms virtual, dns req: 0, digest: <a6a8e3835061e53ed251c57ab4f22463>, rcpts: <root@localhost>
It works !
Training
If you have already a spam or junk folder is really easy training the Bayesian classifier with rspamc.
I use Maildir, so for my setup the initial training is something like this:
# cd /storage/vmails/balaskas.gr/evaggelos/.Spam/cur/ # find . -type f -exec rspamc learn_spam {} \;
Auto-Training
I’ve read a lot of tutorials that suggest real-time training via dovecot plugins or something similar. I personally think that approach adds complexity and for small companies or personal setup, I prefer using Cron daemon:
@daily /bin/find /storage/vmails/balaskas.gr/evaggelos/.Spam/cur/ -type f -mtime -1 -exec rspamc learn_spam {} \;
That means every day, search for new emails in my spam folder and use them to train rspamd.
Training from mbox
First of all seriously ?
Split mbox
There is a nice and simply way to split a mbox to separated files for rspamc to use them.
# awk '/^From / {i++}{print > "msg"i}' Spam
and then feed rspamc:
# ls -1 msg* | xargs rspamc --verbose learn_spam
Stats
# rspamc stat
Results for command: stat (0.068 seconds)
Messages scanned: 2
Messages with action reject: 0, 0.00%
Messages with action soft reject: 0, 0.00%
Messages with action rewrite subject: 0, 0.00%
Messages with action add header: 2, 100.00%
Messages with action greylist: 0, 0.00%
Messages with action no action: 0, 0.00%
Messages treated as spam: 2, 100.00%
Messages treated as ham: 0, 0.00%
Messages learned: 1859
Connections count: 2
Control connections count: 2157
Pools allocated: 2191
Pools freed: 2170
Bytes allocated: 542k
Memory chunks allocated: 41
Shared chunks allocated: 10
Chunks freed: 0
Oversized chunks: 736
Fuzzy hashes in storage "rspamd.com": 659509399
Fuzzy hashes stored: 659509399
Statfile: BAYES_SPAM type: sqlite3; length: 32.66M; free blocks: 0; total blocks: 430.29k; free: 0.00%; learned: 1859; users: 1; languages: 4
Statfile: BAYES_HAM type: sqlite3; length: 9.22k; free blocks: 0; total blocks: 0; free: 0.00%; learned: 0; users: 1; languages: 1
Total learns: 1859
X-Spamd-Result
To view the spam score in every email, we need to enable extended reporting headers and to do that we need to edit our configuration:
# vim /etc/rspamd/modules.d/milter_headers.conf
and just above use add :
# ebal, Wed, 06 Sep 2017 01:52:08 +0300
extended_spam_headers = true;
use = [];
then reload rspamd:
# /etc/init.d/rspamd reload
syntax OK
Reloading rspamd: [ OK ]
View Source
If your open the email in view-source then you will see something like this:
X-Rspamd-Queue-Id: D0A5728ABF
X-Rspamd-Server: centos69
X-Spamd-Result: default: False [3.40 / 15.00]
Web Server
Rspamd comes with their own web server. That is really useful if you dont have a web server in your mail server, but it is not recommended.
By-default, rspamd web server is only listening to local connections. We can see that from the below ss output
# ss -lp | egrep -i rspamd
LISTEN 0 128 :::11332 :::* users:(("rspamd",7469,10),("rspamd",7471,10),("rspamd",7472,10),("rspamd",7473,10))
LISTEN 0 128 *:11332 *:* users:(("rspamd",7469,9),("rspamd",7471,9),("rspamd",7472,9),("rspamd",7473,9))
LISTEN 0 128 :::11333 :::* users:(("rspamd",7469,18),("rspamd",7473,18))
LISTEN 0 128 *:11333 *:* users:(("rspamd",7469,16),("rspamd",7473,16))
LISTEN 0 128 ::1:11334 :::* users:(("rspamd",7469,14),("rspamd",7472,14),("rspamd",7473,14))
LISTEN 0 128 127.0.0.1:11334 *:* users:(("rspamd",7469,12),("rspamd",7472,12),("rspamd",7473,12))
127.0.0.1:11334
So if you want to change that (dont) you have to edit the rspamd.conf (core file):
# vim +/11334 /etc/rspamd/rspamd.conf
and change this line:
bind_socket = "localhost:11334";to something like this:
bind_socket = "YOUR_SERVER_IP:11334";or use sed:
# sed -i -e 's/localhost:11334/YOUR_SERVER_IP/' /etc/rspamd/rspamd.conf
and then fire up your browser:

Web Password
It is a good tactic to change the default password of this web-gui to something else.
# vim /etc/rspamd/worker-controller.inc
# password = "q1";
password = "password";always a good idea to restart rspamd.
Reverse Proxy
I dont like having exposed any web app without SSL or basic authentication, so I shall put rspamd web server under a reverse proxy (apache).
So on httpd-2.2 the configuration is something like this:
ProxyPreserveHost On
<Location /rspamd>
AuthName "Rspamd Access"
AuthType Basic
AuthUserFile /etc/httpd/rspamd_htpasswd
Require valid-user
ProxyPass http://127.0.0.1:11334
ProxyPassReverse http://127.0.0.1:11334
Order allow,deny
Allow from all
</Location>Http Basic Authentication
You need to create the file that is going to be used to store usernames and password for basic authentication:
# htpasswd -csb /etc/httpd/rspamd_htpasswd rspamd rspamd_passwd
Adding password for user rspamd
restart your apache instance.
bind_socket
Of course for this to work, we need to change the bind socket on rspamd.conf
Dont forget this ;)
bind_socket = "127.0.0.1:11334";Selinux
If there is a problem with selinux, then:
# setsebool -P httpd_can_network_connect=1
or
# setsebool httpd_can_network_connect_db on
Errors ?
If you see an error like this:
IO write error
when running rspamd, then you need explicit tell rspamd to use:
rspamc -h 127.0.0.1:11334
To prevent any future errors, I’ve created a shell wrapper:
/usr/local/bin/rspamc
#!/bin/sh
/usr/bin/rspamc -h 127.0.0.1:11334 $*
Final Thoughts
I am using rspamd for a while know and I am pretty happy with it.
I’ve setup a spamtrap email address to feed my spam folder and let the cron script to train rspamd.
So after a thousand emails:
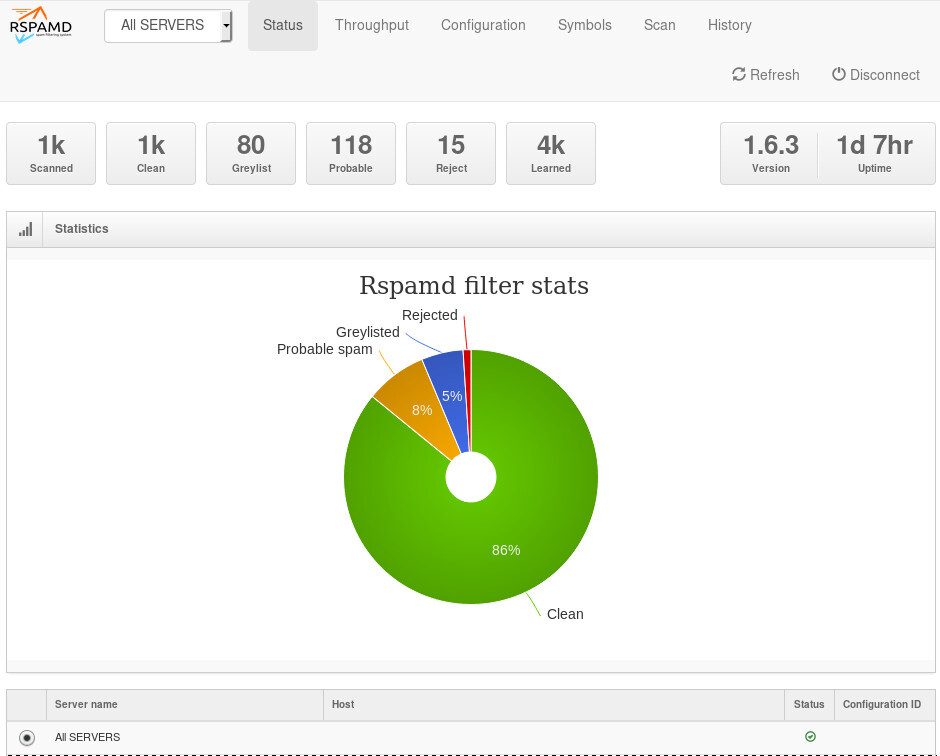

![]()
In many companies, nagios is the de-facto monitoring tool. Even with new modern alternatives solutions, this opensource project, still, has a large amount of implementations in place. This guide is based on a “clean/fresh” CentOS 6.9 virtual machine.
Epel
An official nagios repository exist in this address: https://repo.nagios.com/
I prefer to install nagios via the EPEL repository:
# yum -y install http://fedora-mirror01.rbc.ru/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
# yum info nagios | grep Version
Version : 4.3.2# yum -y install nagios
Selinux
Every online manual, suggest to disable selinux with nagios. There is a reason for that ! but I will try my best to provide info on how to keep selinux enforced. To write our own nagios selinux policies the easy way, we need one more package:
# yum -y install policycoreutils-python
Starting nagios:
# /etc/init.d/nagios restart
will show us some initial errors in /var/log/audit/audit.log selinux log file
Filtering the results:
# egrep denied /var/log/audit/audit.log | audit2allow
will display something like this:
#============= nagios_t ==============
allow nagios_t initrc_tmp_t:file write;
allow nagios_t self:capability chown;
To create a policy file based on your errors:
# egrep denied /var/log/audit/audit.log | audit2allow -a -M nagios_t
and to enable it:
# semodule -i nagios_t.pp
BE AWARE this is not the only problem with selinux, but I will provide more details in few moments.
Nagios
Now we are ready to start the nagios daemon:
# /etc/init.d/nagios restart
filtering the processes of our system:
# ps -e fuwww | egrep na[g]ios
nagios 2149 0.0 0.1 18528 1720 ? Ss 19:37 0:00 /usr/sbin/nagios -d /etc/nagios/nagios.cfg
nagios 2151 0.0 0.0 0 0 ? Z 19:37 0:00 _ [nagios] <defunct>
nagios 2152 0.0 0.0 0 0 ? Z 19:37 0:00 _ [nagios] <defunct>
nagios 2153 0.0 0.0 0 0 ? Z 19:37 0:00 _ [nagios] <defunct>
nagios 2154 0.0 0.0 0 0 ? Z 19:37 0:00 _ [nagios] <defunct>
nagios 2155 0.0 0.0 18076 712 ? S 19:37 0:00 _ /usr/sbin/nagios -d /etc/nagios/nagios.cfg
super!
Apache
Now it is time to start our web server apache:
# /etc/init.d/httpd restart
Starting httpd: httpd: apr_sockaddr_info_get() failed
httpd: Could not reliably determine the server's fully qualified domain name, using 127.0.0.1 for ServerNameThis is a common error, and means that we need to define a ServerName in our apache configuration.
First, we give an name to our host file:
# vim /etc/hosts
for this guide, I ‘ll go with the centos69 but you can edit that according your needs:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 centos69then we need to edit the default apache configuration file:
# vim /etc/httpd/conf/httpd.conf
#ServerName www.example.com:80
ServerName centos69and restart the process:
# /etc/init.d/httpd restart
Stopping httpd: [ OK ]
Starting httpd: [ OK ]We can see from the netstat command that is running:
# netstat -ntlp | grep 80
tcp 0 0 :::80 :::* LISTEN 2729/httpd Firewall
It is time to fix our firewall and open the default http port, so that we can view the nagios from our browser.
That means, we need to fix our iptables !
# iptables -A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
this is want we need. To a more permanent solution, we need to edit the default iptables configuration file:
# vim /etc/sysconfig/iptables
and add the below entry on INPUT chain section:
-A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPTWeb Browser
We are ready to fire up our web browser and type the address of our nagios server.
Mine is on a local machine with the IP: 129.168.122.96, so
http://192.168.122.96/nagios/
User Authentication
The default user authentication credentials are:
nagiosadmin // nagiosadminbut we can change them!
From our command line, we type something similar:
# htpasswd -sb /etc/nagios/passwd nagiosadmin e4j9gDkk6LXncCdDg
so that htpasswd will update the default nagios password entry on the /etc/nagios/passwd with something else, preferable random and difficult password.
ATTENTION: e4j9gDkk6LXncCdDg is just that, a random password that I created for this document only. Create your own and dont tell anyone!
Selinux, Part Two
at this moment and if you are tail-ing the selinux audit file, you will see some more error msgs.
Below, you will see my nagios_t selinux policy file with all the things that are needed for nagios to run properly - at least at the moment.!
module nagios_t 1.0;
require {
type nagios_t;
type initrc_tmp_t;
type nagios_spool_t;
type nagios_system_plugin_t;
type nagios_exec_t;
type httpd_nagios_script_t;
class capability chown;
class file { write read open execute_no_trans getattr };
}
#============= httpd_nagios_script_t ==============
allow httpd_nagios_script_t nagios_spool_t:file { open read getattr };
#============= nagios_t ==============
allow nagios_t initrc_tmp_t:file write;
allow nagios_t nagios_exec_t:file execute_no_trans;
allow nagios_t self:capability chown;
#============= nagios_system_plugin_t ==============
allow nagios_system_plugin_t nagios_exec_t:file getattr;Edit your nagios_t.te file accordingly and then build your selinux policy:
# make -f /usr/share/selinux/devel/Makefile
You are ready to update the previous nagios selinux policy :
# semodule -i nagios_t.pp
Selinux - Nagios package
So … there is an rpm package with the name: nagios-selinux on Version: 4.3.2
you can install it, but does not resolve all the selinux errors in audit file ….. so ….
I think my way is better, cause you can understand some things better and have more flexibility on defining your selinux policy
Nagios Plugins
Nagios is the core process, daemon. We need the nagios plugins - the checks !
You can do something like this:
# yum install nagios-plugins-all.x86_64
but I dont recommend it.
These are the defaults :
nagios-plugins-load-2.2.1-4git.el6.x86_64
nagios-plugins-ping-2.2.1-4git.el6.x86_64
nagios-plugins-disk-2.2.1-4git.el6.x86_64
nagios-plugins-procs-2.2.1-4git.el6.x86_64
nagios-plugins-users-2.2.1-4git.el6.x86_64
nagios-plugins-http-2.2.1-4git.el6.x86_64
nagios-plugins-swap-2.2.1-4git.el6.x86_64
nagios-plugins-ssh-2.2.1-4git.el6.x86_64# yum -y install nagios-plugins-load nagios-plugins-ping nagios-plugins-disk nagios-plugins-procs nagios-plugins-users nagios-plugins-http nagios-plugins-swap nagios-plugins-ssh
and if everything is going as planned, you will see something like this:

PNP4Nagios
It is time, to add pnp4nagios a simple graphing tool and get read the nagios performance data and represent them to graphs.
# yum info pnp4nagios | grep Version
Version : 0.6.22# yum -y install pnp4nagios
We must not forget to restart our web server:
# /etc/init.d/httpd restart
Bulk Mode with NPCD
I’ve spent toooooo much time to understand why the default Synchronous does not work properly with nagios v4x and pnp4nagios v0.6x
In the end … this is what it works - so try not to re-invent the wheel , as I tried to do and lost so many hours.
Performance Data
We need to tell nagios to gather performance data from their check:
# vim +/process_performance_data /etc/nagios/nagios.cfg
process_performance_data=1
We also need to tell nagios, what to do with this data:
nagios.cfg
# *** the template definition differs from the one in the original nagios.cfg
#
service_perfdata_file=/var/log/pnp4nagios/service-perfdata
service_perfdata_file_template=DATATYPE::SERVICEPERFDATAtTIMET::$TIMET$tHOSTNAME::$HOSTNAME$tSERVICEDESC::$SERVICEDESC$tSERVICEPERFDATA::$SERVICEPERFDATA$tSERVICECHECKCOMMAND::$SERVICECHECKCOMMAND$tHOSTSTATE::$HOSTSTATE$tHOSTSTATETYPE::$HOSTSTATETYPE$tSERVICESTATE::$SERVICESTATE$tSERVICESTATETYPE::$SERVICESTATETYPE$
service_perfdata_file_mode=a
service_perfdata_file_processing_interval=15
service_perfdata_file_processing_command=process-service-perfdata-file
# *** the template definition differs from the one in the original nagios.cfg
#
host_perfdata_file=/var/log/pnp4nagios/host-perfdata
host_perfdata_file_template=DATATYPE::HOSTPERFDATAtTIMET::$TIMET$tHOSTNAME::$HOSTNAME$tHOSTPERFDATA::$HOSTPERFDATA$tHOSTCHECKCOMMAND::$HOSTCHECKCOMMAND$tHOSTSTATE::$HOSTSTATE$tHOSTSTATETYPE::$HOSTSTATETYPE$
host_perfdata_file_mode=a
host_perfdata_file_processing_interval=15
host_perfdata_file_processing_command=process-host-perfdata-fileCommands
In the above configuration, we introduced two new commands
service_perfdata_file_processing_command &
host_perfdata_file_processing_commandWe need to define them in the /etc/nagios/objects/commands.cfg file :
#
# Bulk with NPCD mode
#
define command {
command_name process-service-perfdata-file
command_line /bin/mv /var/log/pnp4nagios/service-perfdata /var/spool/pnp4nagios/service-perfdata.$TIMET$
}
define command {
command_name process-host-perfdata-file
command_line /bin/mv /var/log/pnp4nagios/host-perfdata /var/spool/pnp4nagios/host-perfdata.$TIMET$
}If everything have gone right … then you will be able to see on a nagios check something like this:

Verify
Verify your pnp4nagios setup:
# wget -c http://verify.pnp4nagios.org/verify_pnp_config
# perl verify_pnp_config -m bulk+npcd -c /etc/nagios/nagios.cfg -p /etc/pnp4nagios/ NPCD
The NPCD daemon (Nagios Performance C Daemon) is the daemon/process that will translate the gathered performance data to graphs, so let’s started it:
# /etc/init.d/npcd restart
Stopping npcd: [FAILED]
Starting npcd: [ OK ]You should see some warnings but not any critical errors.
Templates
Two new template definition should be created, one for the host and one for the service:
/etc/nagios/objects/templates.cfg
define host {
name host-pnp
action_url /pnp4nagios/index.php/graph?host=$HOSTNAME$&srv=_HOST_' class='tips' rel='/pnp4nagios/index.php/popup?host=$HOSTNAME$&srv=_HOST_
register 0
}
define service {
name srv-pnp
action_url /pnp4nagios/graph?host=$HOSTNAME$&srv=$SERVICEDESC$' class='tips' rel='/pnp4nagios/popup?host=$HOSTNAME$&srv=$SERVICEDESC$
register 0
}Host Definition
Now we need to apply the host-pnp template to our system:
so this configuration: /etc/nagios/objects/localhost.cfg
define host{
use linux-server ; Name of host template to use
; This host definition will inherit all variables that are defined
; in (or inherited by) the linux-server host template definition.
host_name localhost
alias localhost
address 127.0.0.1
}
becomes:
define host{
use linux-server,host-pnp ; Name of host template to use
; This host definition will inherit all variables that are defined
; in (or inherited by) the linux-server host template definition.
host_name localhost
alias localhost
address 127.0.0.1
}Service Definition
And we finally must append the pnp4nagios service template to our services:
srv-pnp
define service{
use local-service,srv-pnp ; Name of service template to use
host_name localhostGraphs
We should be able to see graphs like these:

Happy Measurements!
appendix
These are some extra notes on the above article, you need to take in mind:
Services
# chkconfig httpd on
# chkconfig iptables on
# chkconfig nagios on
# chkconfig npcd on PHP
If you are not running the default php version on your system, it is possible to get this error msg:
Non-static method nagios_Core::SummaryLink()There is a simply solution for that, you need to modify the index file to exclude the deprecated php error msgs:
# vim +/^error_reporting /usr/share/nagios/html/pnp4nagios/index.php
// error_reporting(E_ALL & ~E_STRICT);
error_reporting(E_ALL & ~E_STRICT & ~E_DEPRECATED);
Let’s Encrypt
I’ve written some posts on Let’s Encrypt but the most frequently question is how to auto renew a certificate every 90 days.
Disclaimer
This is my mini how-to, on centos 6 with a custom compiled Python 2.7.13 that I like to run on virtualenv from latest git updated certbot. Not a copy/paste solution for everyone!
Cron
Cron doesnt not seem to have something useful to use on comparison to 90 days:

Modification Time
The most obvious answer is to look on the modification time on lets encrypt directory :
eg. domain: balaskas.gr
# find /etc/letsencrypt/live/balaskas.gr -type d -mtime +90 -exec ls -ld {} \;
# find /etc/letsencrypt/live/balaskas.gr -type d -mtime +80 -exec ls -ld {} \;
# find /etc/letsencrypt/live/balaskas.gr -type d -mtime +70 -exec ls -ld {} \;
# find /etc/letsencrypt/live/balaskas.gr -type d -mtime +60 -exec ls -ld {} \;
drwxr-xr-x. 2 root root 4096 May 15 20:45 /etc/letsencrypt/live/balaskas.gr
OpenSSL
# openssl x509 -in <(openssl s_client -connect balaskas.gr:443 2>/dev/null) -noout -enddate
If you have registered your email with Let’s Encrypt then you get your first email in 60 days!
Renewal
Here are my own custom steps:
# cd /root/certbot.git
# git pull origin
# source venv/bin/activate && source venv/bin/activate
# cd venv/bin/
# monit stop httpd
# ./venv/bin/certbot renew --cert-name balaskas.gr --standalone
# monit start httpd
# deactivate
Script
I use monit, you can edit the script accordingly to your needs :
#!/bin/sh
DOMAIN=$1
## Update certbot
cd /root/certbot.git
git pull origin
# Enable Virtual Environment for python
source venv/bin/activate && source venv/bin/activate
## Stop Apache
monit stop httpd
sleep 5
## Renewal
./venv/bin/certbot renew --cert-name ${DOMAIN} --standalone
## Exit virtualenv
deactivate
## Start Apache
monit start httpd
All Together
# find /etc/letsencrypt/live/balaskas.gr -type d -mtime +80 -exec /usr/local/bin/certbot.autorenewal.sh balaskas.gr \;
Systemd Timers
or put it on cron
whatever :P
How to install slack dekstop to archlinux
Download Slack Desktop
eg. latest version
https://downloads.slack-edge.com/linux_releases/slack-2.6.3-0.1.fc21.x86_64.rpm
Extract under root filesystem
# cd /
# rpmextract.sh slack-2.6.3-0.1.fc21.x86_64.rpm
Done
Actually, that’s it!
Run
Run slack-desktop as a regular user:
$ /usr/lib/slack/slack
Slack Desktop
Proxy
Define your proxy settings on your environment:
declare -x ftp_proxy="proxy.example.org:8080"
declare -x http_proxy="proxy.example.org:8080"
declare -x https_proxy="proxy.example.org:8080"Slack
Iterator
a few months ago, I wrote an article on RecursiveDirectoryIterator, you can find the article here: PHP Recursive Directory File Listing . If you run the code example, you ‘ll see that the output is not sorted.
Object
Recursive Iterator is actually an object, a special object that we can perform iterations on sequence (collection) of data. So it is a little difficult to sort them using known php functions. Let me give you an example:
$Iterator = new RecursiveDirectoryIterator('./');
foreach ($Iterator as $file)
var_dump($file);
object(SplFileInfo)#7 (2) {
["pathName":"SplFileInfo":private]=>
string(12) "./index.html"
["fileName":"SplFileInfo":private]=>
string(10) "index.html"
}
You see here, the iterator is an object of SplFileInfo class.
Internet Answers
Unfortunately stackoverflow and other related online results provide the most complicated answers on this matter. Of course this is not stackoverflow’s error, and it is really a not easy subject to discuss or understand, but personally I dont get the extra fuzz (complexity) on some of the responses.
Back to basics
So let us go back a few steps and understand what an iterator really is. An iterator is an object that we can iterate! That means we can use a loop to walk through the data of an iterator. Reading the above output you can get (hopefully) a better idea.
We can also loop the Iterator as a simply array.
eg.
$It = new RecursiveDirectoryIterator('./');
foreach ($It as $key=>$val)
echo $key.":".$val."n";output:
./index.html:./index.htmlArrays
It is difficult to sort Iterators, but it is really easy to sort arrays!
We just need to convert the Iterator into an Array:
// Copy the iterator into an array
$array = iterator_to_array($Iterator);that’s it!
Sorting
For my needs I need to reverse sort the array by key (filename on a recursive directory), so my sorting looks like:
krsort( $array );easy, right?
Just remember that you can use ksort before the array is already be defined. You need to take two steps, and that is ok.
Convert to Iterator
After sorting, we need to change back an iterator object format:
// Convert Array to an Iterator
$Iterator = new ArrayIterator($array);and that’s it !
Full Code Example
the entire code in one paragraph:
<?php
# ebal, Fri, 07 Jul 2017 22:01:48 +0300
// Directory to Recursive search
$dir = "/tmp/";
// Iterator Object
$files = new RecursiveIteratorIterator(
new RecursiveDirectoryIterator($dir)
);
// Convert to Array
$Array = iterator_to_array ( $files );
// Reverse Sort by key the array
krsort ( $Array );
// Convert to Iterator
$files = new ArrayIterator( $Array );
// Print the file name
foreach($files as $name => $object)
echo "$namen";
?>Prologue
Part of my day job is to protect a large mail infrastructure. That means that on a daily basis we are fighting SPAM and try to protect our customers for any suspicious/malicious mail traffic. This is not an easy job. Actually globally is not a easy job. But we are trying and trying hard.
ReplyTo
The last couple months, I have started a project on gitlab gathering the malicious ReplyTo from already identified spam emails. I was looking for a pattern or something that I can feed our antispam engines with so that we can identify spam more accurately. It’s doesnt seem to work as i thought. Spammers can alter their ReplyTo in a matter of minutes!
TheList
Here is the list for the last couple months: ReplyTo
I will -from time to time- try to update it and hopefully someone can find it useful
Free domains
It’s not much yet, but even with this small sample you can see that ~ 50% of phishing goes back to gmail !
105 gmail.com
49 yahoo.com
18 hotmail.com
17 outlook.comMore Info
You can contact me with various ways if you are interested in more details.
Preferably via encrypted email: PGP: ‘ 0×1c8968af8d2c621f ‘
or via DM in twitter: @ebalaskas
PS
I also keep another list, of suspicious fwds
but keep in mind that it might have some false positives.
Prologue
I should have written this post like a decade ago, but laziness got the better of me.
I use TLS with IMAP and SMTP mail server. That means I encrypt the connection by protocol against the mail server and not by port (ssl Vs tls). Although I do not accept any authentication before STARTTLS command is being provided (that means no cleartext passwords in authentication), I was leaving the PLAIN TEXT authentication mechanism in the configuration. That’s not an actual problem unless you are already on the server and you are trying to connect on localhost but I can do better.
LDAP
I use OpenLDAP as my backend authentication database. Before all, the ldap attribute password must be changed from cleartext to CRAM-MD5
Typing the doveadm command from dovecot with the password method:
# doveadm pw
Enter new password: test
Retype new password: test
{CRAM-MD5}e02d374fde0dc75a17a557039a3a5338c7743304777dccd376f332bee68d2cf6will return the CRAM-MD5 hash of our password (test)
Then we need to edit our DN (distinguished name) with ldapvi:
From:
uid=USERNAME,ou=People,dc=example,dc=org
userPassword: testTo:
uid=USERNAME,ou=People,dc=example,dc=org
userPassword: {CRAM-MD5}e02d374fde0dc75a17a557039a3a5338c7743304777dccd376f332bee68d2cf6Dovecot
Dovecot is not only the imap server but also the “Simple Authentication and Security Layer” aka SASL service. That means that imap & smtp are speaking with dovecot for authentication and dovecot uses ldap as the backend. To change AUTH=PLAIN to cram-md5 we need to do the below change:
file: 10-auth.conf
From:
auth_mechanisms = plain
To:
auth_mechanisms = cram-md5Before restarting dovecot, we need to make one more change. This step took me a couple hours to figure it out! On our dovecot-ldap.conf.ext configuration file, we need to tell dovecot NOT to bind to ldap for authentication but let dovecot to handle the authentication process itself:
From:
# Enable Authentication Binds
# auth_bind = yesTo:
# Enable Authentication Binds
auth_bind = noTo guarantee that the entire connection is protected by TLS encryption, change in 10-ssl.conf the below setting:
From:
ssl = yesTo:
ssl = requiredSSL/TLS is always required, even if non-plaintext authentication mechanisms are used. Any attempt to authenticate before SSL/TLS is enabled will cause an authentication failure.
After that, restart your dovecot instance.
Testing
# telnet example.org imap
Trying 172.12.13.14 ...
Connected to example.org.
Escape character is '^]'.
* OK [CAPABILITY IMAP4rev1 LITERAL+ SASL-IR LOGIN-REFERRALS ID ENABLE IDLE STARTTLS AUTH=CRAM-MD5] Dovecot ready.
1 LOGIN USERNAME@example.org test
1 NO [ALERT] Unsupported authentication mechanism.
^]
telnet> clo
That meas no cleartext authentication is permitted
MUA
Now the hard part, the mail clients:
RainLoop
My default webmail client since v1.10.1.123 supports CRAM-MD5
To verify that, open your application.ini file under your data folder and search for something like that:
imap_use_auth_plain = On
imap_use_auth_cram_md5 = On
smtp_use_auth_plain = On
smtp_use_auth_cram_md5 = Onas a bonus, rainloop supports STARTTLS and authentication for imap & smtp, even when talking to 127.0.0.1
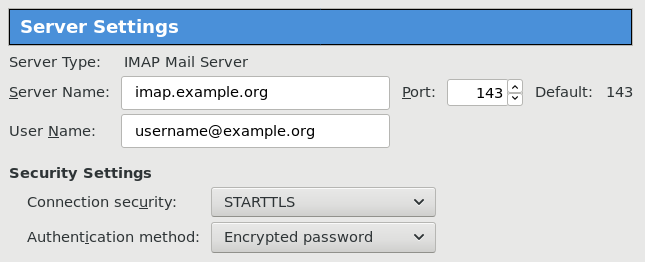
Thunderbird
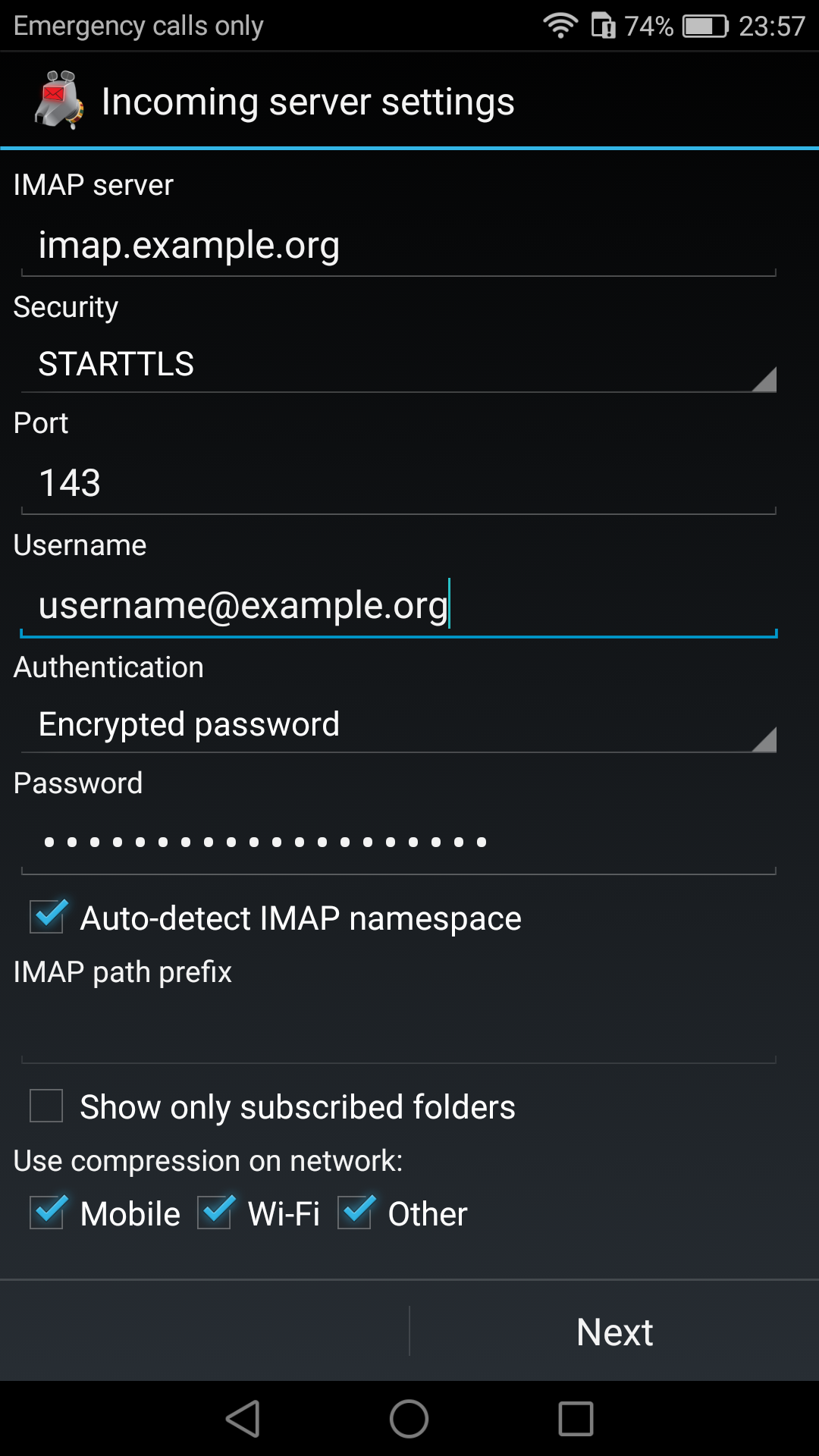
K9
When traveling, I make an effort to visit the local hackerspace. I understand that this is not normal behavior for many people, but for us (free / opensource advocates) is always a must.
This was my 4th week on Bratislava and for the first time, I had a couple free hours to visit ProgressBar HackerSpace.
For now, they are allocated in the middle of the historical city on the 2nd floor. The entrance is on a covered walkway (gallery) between two buildings. There is a bell to ring and automated (when members are already inside) the door is wide open for any visitor. No need to wait or explain why you are there!
Entering ProgressBar there is no doubt that you are entering a hackerspace.

You can view a few photos by clicking here: ProgressBar - Photos
And you can find ProgressBar on OpenStreet Map
Some cool-notable projects:
- bitcoin vending machine
- robot arm to fetch clubmate
- magic wood to switch on/off lights
- blinkwall
- Cool T-shirts
their lab is fool with almost anything you need to play/hack with.
I was really glad to make time and visit them.

An Amazing Book!!!
Must Read !!
I’ve listened to the audiobook like in two days.
Couldnt leave it down.
Then organize a CryptoParty to your local hackerspace