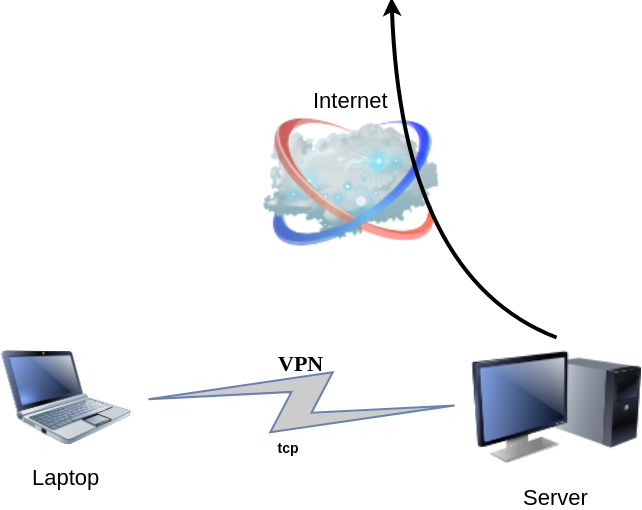
DSVPN is designed to address the most common use case for using a VPN
Works with TCP, blocks IPv6 leaks, redirect-gateway out-of-the-box!
last updated: 20190810
- iptables rules example added
- change vpn.key to dsvpn.key
- add base64 example for easy copy/transfer across machines
dsvpn binary
I keep a personal gitlab CI for dsvpn here: DSVPN
Compile
Notes on the latest ubuntu:18.04 docker image:
# git clone https://github.com/jedisct1/dsvpn.git
Cloning into 'dsvpn'...
remote: Enumerating objects: 88, done.
remote: Counting objects: 100% (88/88), done.
remote: Compressing objects: 100% (59/59), done.
remote: Total 478 (delta 47), reused 65 (delta 29), pack-reused 390
Receiving objects: 100% (478/478), 93.24 KiB | 593.00 KiB/s, done.
Resolving deltas: 100% (311/311), done.
# cd dsvpn
# ls
LICENSE Makefile README.md include logo.png src
# make
cc -march=native -Ofast -Wall -W -Wshadow -Wmissing-prototypes -Iinclude -o dsvpn src/dsvpn.c src/charm.c src/os.c
strip dsvpn
# ldd dsvpn
linux-vdso.so.1 (0x00007ffd409ba000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fd78480b000)
/lib64/ld-linux-x86-64.so.2 (0x00007fd784e03000)
# ls -l dsvpn
-rwxr-xr-x 1 root root 26840 Jul 20 15:51 dsvpnJust copy the dsvpn binary to your machines.
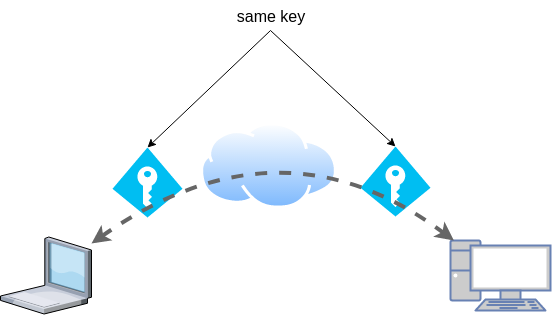
Symmetric Key
dsvpn uses symmetric-key cryptography, that means both machines uses the same encyrpted key.
dd if=/dev/urandom of=dsvpn.key count=1 bs=32
Copy the key to both machines using a secure media, like ssh.
base64
An easy way is to convert key to base64
cat dsvpn.key | base64
ZqMa31qBLrfjjNUfhGj8ADgzmo8+FqlyTNJPBzk/x4k=on the other machine:
echo ZqMa31qBLrfjjNUfhGj8ADgzmo8+FqlyTNJPBzk/x4k= | base64 -d > dsvpn.key
Server
It is very easy to run dsvpn in server mode:
eg.
dsvpn server dsvpn.key auto
Interface: [tun0]
net.ipv4.ip_forward = 1
Listening to *:443ip addr show tun0
4: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 9000 qdisc fq_codel state UNKNOWN group default qlen 500
link/none
inet 192.168.192.254 peer 192.168.192.1/32 scope global tun0
valid_lft forever preferred_lft foreverI prefer to use 10.8.0.0/24 CIDR in my VPNs, so in my VPN setup:
dsvpn server /root/dsvpn.key auto 443 auto 10.8.0.254 10.8.0.2
Using 10.8.0.254 as the VPN Server IP.
systemd service unit - server
I’ve created a simple systemd script dsvpn_server.service
or you can copy it from here:
/etc/systemd/system/dsvpn.service
[Unit]
Description=Dead Simple VPN - Server
[Service]
ExecStart=/usr/local/bin/dsvpn server /root/dsvpn.key auto 443 auto 10.8.0.254 10.8.0.2
Restart=always
RestartSec=20
[Install]
WantedBy=network.targetand then:
systemctl enable dsvpn.service
systemctl start dsvpn.serviceClient
It is also easy to run dsvpn in client mode:
eg.
dsvpn client dsvpn.key 93.184.216.34
# dsvpn client dsvpn.key 93.184.216.34
Interface: [tun0]
Trying to reconnect
Connecting to 93.184.216.34:443...
net.ipv4.tcp_congestion_control = bbr
Connectedip addr show tun0
4: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 9000 qdisc fq_codel state UNKNOWN group default qlen 500
link/none
inet 192.168.192.1 peer 192.168.192.254/32 scope global tun0
valid_lft forever preferred_lft foreverdsvpn works in redict-gateway mode,
so it will apply routing rules to pass all the network traffic through the VPN.
ip route list
0.0.0.0/1 via 192.168.192.254 dev tun0
default via 192.168.122.1 dev eth0 proto static
93.184.216.34 via 192.168.122.1 dev eth0
128.0.0.0/1 via 192.168.192.254 dev tun0
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.69
192.168.192.254 dev tun0 proto kernel scope link src 192.168.192.1As I mentioned above, I prefer to use 10.8.0.0/24 CIDR in my VPNs, so in my VPN client:
dsvpn client /root/dsvpn.key 93.184.216.34 443 auto 10.8.0.2 10.8.0.254
Using 10.8.0.2 as the VPN Client IP.
ip addr show tun0
11: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 9000 qdisc fq_codel state UNKNOWN group default qlen 500
link/none
inet 10.8.0.2 peer 10.8.0.254/32 scope global tun0
valid_lft forever preferred_lft foreversystemd service unit - client
I’ve also created a simple systemd script for the client dsvpn_client.service
or you can copy it from here:
/etc/systemd/system/dsvpn.service
[Unit]
Description=Dead Simple VPN - Client
[Service]
ExecStart=/usr/local/bin/dsvpn client /root/dsvpn.key 93.184.216.34 443 auto 10.8.0.2 10.8.0.254
Restart=always
RestartSec=20
[Install]
WantedBy=network.targetand then:
systemctl enable dsvpn.service
systemctl start dsvpn.serviceand here is an MTR from the client:
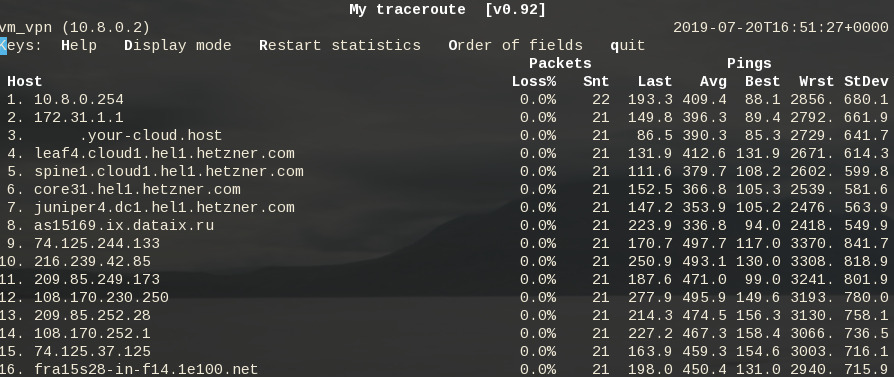
Enjoy !
firewall
It is important to protect your traffic from network leaks. That mean, sometimes, we do not want our network traffic to pass through our provider if the vpn server/client went down. To prevent any network leak, here is an example of iptables rules for a virtual machine:
# Empty iptables rule file
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -i lo -j ACCEPT
-A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A INPUT -m conntrack --ctstate INVALID -j DROP
-A INPUT -p icmp --icmp-type 8 -m conntrack --ctstate NEW -j ACCEPT
# LibVirt
-A INPUT -i eth0 -s 192.168.122.0/24 -j ACCEPT
# Reject incoming traffic
-A INPUT -j REJECT
# DSVPN
-A OUTPUT -p tcp -m tcp -o eth0 -d 93.184.216.34 --dport 443 -j ACCEPT
# LibVirt
-A OUTPUT -o eth0 -d 192.168.122.0/24 -j ACCEPT
# Allow tun
-A OUTPUT -o tun+ -j ACCEPT
# Reject outgoing traffic
-A OUTPUT -p tcp -j REJECT --reject-with tcp-reset
-A OUTPUT -p udp -j REJECT --reject-with icmp-port-unreachable
COMMITHere is the prefable output:
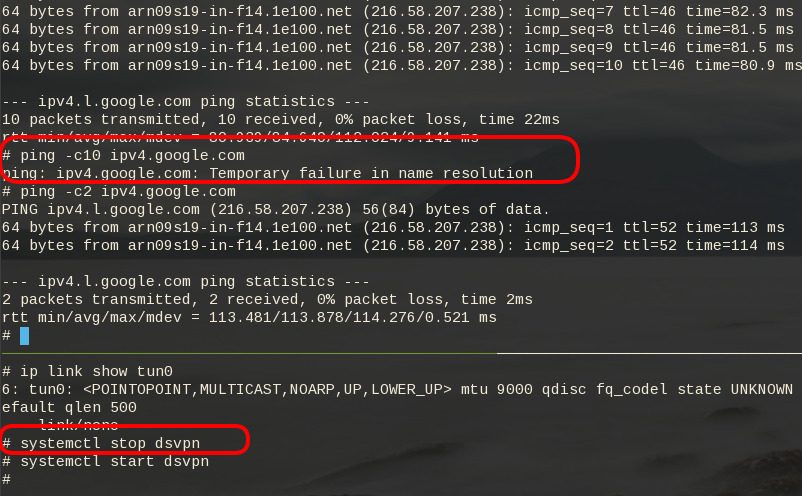
Notes from archlinux
xdg-open - opens a file or URL in the user’s preferred application
When you are trying to authenticate to a new workspace (with 2fa) using the slack-desktop, it will open your default browser and after the authentication your browser will re-direct you to the slack-desktop again using something like this
slack://6f69f7c8b/magic-login/t3bnakl6qabc-16869c6603bdb64f3a6f69f7c8b2d920fa26149f990e0556b4e5c6f26984db0aThis is mime query !
$ xdg-mime query default x-scheme-handler/slack
slack.desktop
$ locate slack.desktop
/usr/share/applications/slack.desktop
$ more /usr/share/applications/slack.desktop
[Desktop Entry]
Name=Slack
Comment=Slack Desktop
GenericName=Slack Client for Linux
Exec=/usr/bin/slack --disable-gpu %U
Icon=/usr/share/pixmaps/slack.png
Type=Application
StartupNotify=true
Categories=GNOME;GTK;Network;InstantMessaging;
MimeType=x-scheme-handler/slack;
I had to change the Exec entry above to point to my slack-desktop binary
Notes based on Ubuntu 18.04 LTS
My notes for this k8s blog post are based upon an Ubuntu 18.05 LTS KVM Virtual Machine. The idea is to use nested-kvm to run minikube inside a VM, that then minikube will create a kvm node.
minikube builds a local kubernetes cluster on a single node with a set of small resources to run a small kubernetes deployment.
Archlinux –> VM Ubuntu 18.04 LTS runs minikube/kubeclt —> KVM minikube node
Pre-requirements
Nested kvm
Host
(archlinux)
$ grep ^NAME /etc/os-release
NAME="Arch Linux"Check that nested-kvm is already supported:
$ cat /sys/module/kvm_intel/parameters/nested
NIf the output is N (No) then remove & enable kernel module again:
$ sudo modprobe -r kvm_intel
$ sudo modprobe kvm_intel nested=1Check that nested-kvm is now enabled:
$ cat /sys/module/kvm_intel/parameters/nested
Y
Guest
Inside the virtual machine:
$ grep NAME /etc/os-release
NAME="Ubuntu"
PRETTY_NAME="Ubuntu 18.04.2 LTS"
VERSION_CODENAME=bionic
UBUNTU_CODENAME=bionic$ egrep -o 'vmx|svm|0xc0f' /proc/cpuinfo
vmx$ kvm-ok
INFO: /dev/kvm exists
KVM acceleration can be used
LibVirtd
If the above step fails, try to edit the xml libvirtd configuration file in your host:
# virsh edit ubuntu_18.04
and change cpu mode to passthrough:
from
<cpu mode='custom' match='exact' check='partial'>
<model fallback='allow'>Nehalem</model>
</cpu>to
<cpu mode='host-passthrough' check='none'/>
Install Virtualization Tools
Inside the VM
sudo apt -y install
qemu-kvm
bridge-utils
libvirt-clients
libvirt-daemon-system
Permissions
We need to be included in the libvirt group
sudo usermod -a -G libvirt $(whoami)
newgrp libvirt
kubectl
kubectl is a command line interface for running commands against Kubernetes clusters.
size: ~41M
$ export VERSION=$(curl -sL https://storage.googleapis.com/kubernetes-release/release/stable.txt)
$ curl -LO https://storage.googleapis.com/kubernetes-release/release/$VERSION/bin/linux/amd64/kubectl
$ chmod +x kubectl
$ sudo mv kubectl /usr/local/bin/kubectl
$ kubectl completion bash | sudo tee -a /etc/bash_completion.d/kubectl
$ kubectl versionif you wan to use bash autocompletion without logout/login use this:
source <(kubectl completion bash)What the json output of kubectl version looks like:
$ kubectl version -o json | jq .
The connection to the server localhost:8080 was refused - did you specify the right host or port?
{
"clientVersion": {
"major": "1",
"minor": "15",
"gitVersion": "v1.15.0",
"gitCommit": "e8462b5b5dc2584fdcd18e6bcfe9f1e4d970a529",
"gitTreeState": "clean",
"buildDate": "2019-06-19T16:40:16Z",
"goVersion": "go1.12.5",
"compiler": "gc",
"platform": "linux/amd64"
}
}Message:
The connection to the server localhost:8080 was refused - did you specify the right host or port?it’s okay if minikube hasnt started yet.
minikube
size: ~40M
$ curl -sLO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
$ chmod +x minikube-linux-amd64
$ sudo mv minikube-linux-amd64 /usr/local/bin/minikube
$ minikube version
minikube version: v1.2.0
$ minikube update-check
CurrentVersion: v1.2.0
LatestVersion: v1.2.0
$ minikube completion bash | sudo tee -a /etc/bash_completion.d/minikube To include bash completion without login/logout:
source $(minikube completion bash)
KVM2 driver
We need a driver so that minikube can build a kvm image/node for our kubernetes cluster.
size: ~36M
$ curl -sLO https://storage.googleapis.com/minikube/releases/latest/docker-machine-driver-kvm2
$ chmod +x docker-machine-driver-kvm2
$ mv docker-machine-driver-kvm2 /usr/local/bin/
Start minikube
$ minikube start --vm-driver kvm2
* minikube v1.2.0 on linux (amd64)
* Downloading Minikube ISO ...
129.33 MB / 129.33 MB [============================================] 100.00% 0s
* Creating kvm2 VM (CPUs=2, Memory=2048MB, Disk=20000MB) ...
* Configuring environment for Kubernetes v1.15.0 on Docker 18.09.6
* Downloading kubeadm v1.15.0
* Downloading kubelet v1.15.0
* Pulling images ...
* Launching Kubernetes ...
* Verifying: apiserver proxy etcd scheduler controller dns
* Done! kubectl is now configured to use "minikube"Check via libvirt, you will find out a new VM, named: minikube
$ virsh list
Id Name State
----------------------------------------------------
1 minikube running
Something gone wrong:
Just delete the VM and configuration directories and start again:
$ minikube delete
$ rm -rf ~/.minikube/ ~/.kubekubectl version
Now let’s run kubectl version again
$ kubectl version -o json | jq .
{
"clientVersion": {
"major": "1",
"minor": "15",
"gitVersion": "v1.15.0",
"gitCommit": "e8462b5b5dc2584fdcd18e6bcfe9f1e4d970a529",
"gitTreeState": "clean",
"buildDate": "2019-06-19T16:40:16Z",
"goVersion": "go1.12.5",
"compiler": "gc",
"platform": "linux/amd64"
},
"serverVersion": {
"major": "1",
"minor": "15",
"gitVersion": "v1.15.0",
"gitCommit": "e8462b5b5dc2584fdcd18e6bcfe9f1e4d970a529",
"gitTreeState": "clean",
"buildDate": "2019-06-19T16:32:14Z",
"goVersion": "go1.12.5",
"compiler": "gc",
"platform": "linux/amd64"
}
}
Dashboard
Start kubernetes dashboard
$ kubectl proxy --address 0.0.0.0 --accept-hosts '.*'
Starting to serve on [::]:8001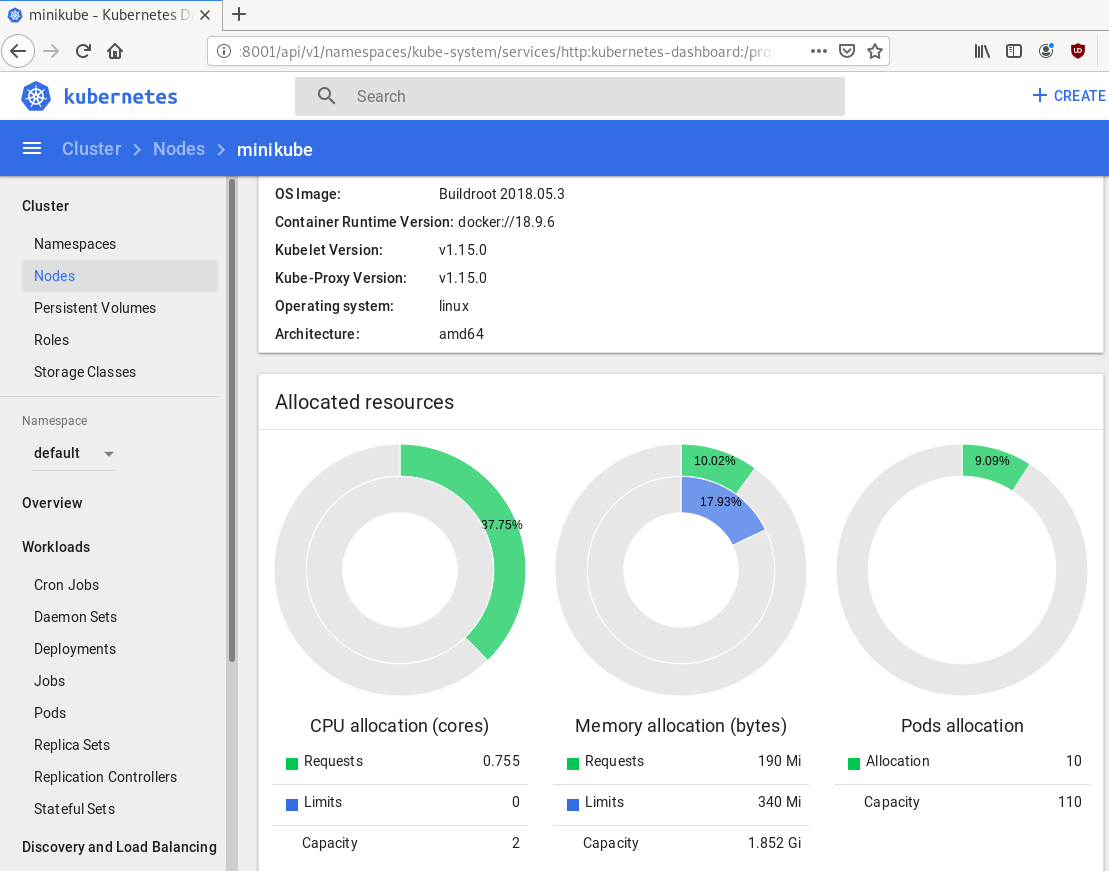
Quick notes
Identify slow disk
# hdparm -Tt /dev/sda
/dev/sda:
Timing cached reads: 2502 MB in 2.00 seconds = 1251.34 MB/sec
Timing buffered disk reads: 538 MB in 3.01 seconds = 178.94 MB/sec
# hdparm -Tt /dev/sdb
/dev/sdb:
Timing cached reads: 2490 MB in 2.00 seconds = 1244.86 MB/sec
Timing buffered disk reads: 536 MB in 3.01 seconds = 178.31 MB/sec
# hdparm -Tt /dev/sdc
/dev/sdc:
Timing cached reads: 2524 MB in 2.00 seconds = 1262.21 MB/sec
Timing buffered disk reads: 538 MB in 3.00 seconds = 179.15 MB/sec
# hdparm -Tt /dev/sdd
/dev/sdd:
Timing cached reads: 2234 MB in 2.00 seconds = 1117.20 MB/sec
Timing buffered disk reads: read(2097152) returned 929792 bytes
Set disk to Faulty State and Remove it
# mdadm --manage /dev/md0 --fail /dev/sdd
mdadm: set /dev/sdd faulty in /dev/md0
# mdadm --manage /dev/md0 --remove /dev/sdd
mdadm: hot removed /dev/sdd from /dev/md0Verify Status
# mdadm --verbose --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 6 15:06:34 2014
Raid Level : raid5
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 4
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Mon Jul 8 00:51:14 2019
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : ServerOne:0 (local to host ServerOne)
UUID : d635095e:50457059:7e6ccdaf:7da91c9b
Events : 18122
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
6 8 32 1 active sync /dev/sdc
4 0 0 4 removed
4 8 0 3 active sync /dev/sdaFormat Disk
- quick format to identify bad blocks,
- better solution zeroing the disk
# mkfs.ext4 -cc -v /dev/sdd - middle ground to use
-c
-c Check the device for bad blocks before creating the file system. If this option is specified twice, then a slower read-write test is used instead of a fast read-only test.
# mkfs.ext4 -c -v /dev/sdd output:
Running command: badblocks -b 4096 -X -s /dev/sdd 244190645
Checking for bad blocks (read-only test): 9.76% done, 7:37 elapsedRemove ext headers
# dd if=/dev/zero of=/dev/sdd bs=4096 count=4096Using dd to remove any ext headers
Test disk
# hdparm -Tt /dev/sdd
/dev/sdd:
Timing cached reads: 2174 MB in 2.00 seconds = 1087.20 MB/sec
Timing buffered disk reads: 516 MB in 3.00 seconds = 171.94 MB/secAdd Disk to Raid
# mdadm --add /dev/md0 /dev/sdd
mdadm: added /dev/sddSpeed
# hdparm -Tt /dev/md0
/dev/md0:
Timing cached reads: 2480 MB in 2.00 seconds = 1239.70 MB/sec
Timing buffered disk reads: 1412 MB in 3.00 seconds = 470.62 MB/sec
Status
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdd[5] sda[4] sdc[6] sdb[0]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/3] [UU_U]
[>....................] recovery = 0.0% (44032/976631296) finish=369.5min speed=44032K/sec
unused devices: <none>Verify Raid
# mdadm --verbose --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 6 15:06:34 2014
Raid Level : raid5
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Mon Jul 8 00:58:38 2019
State : clean, degraded, recovering
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Rebuild Status : 0% complete
Name : ServerOne:0 (local to host ServerOne)
UUID : d635095e:50457059:7e6ccdaf:7da91c9b
Events : 18244
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
6 8 32 1 active sync /dev/sdc
5 8 48 2 spare rebuilding /dev/sdd
4 8 0 3 active sync /dev/sdaHardware Details
HP ProLiant MicroServer
AMD Turion(tm) II Neo N54L Dual-Core Processor
Memory Size: 2 GB - DIMM Speed: 1333 MT/s
Maximum Capacity: 8 GBRunning 24×7 from 23/08/2010, so nine years!

Prologue
The above server started it’s life on CentOS 5 and ext3. Re-formatting to run CentOS 6.x with ext4 on 4 x 1TB OEM Hard Disks with mdadm raid-5. That provided 3 TB storage with Fault tolerance 1-drive failure. And believe me, I used that setup to zeroing broken disks or replacing faulty disks.
As we are reaching the end of CentOS 6.x and there is no official dist-upgrade path for CentOS, and still waiting for CentOS 8.x, I made decision to switch to Ubuntu 18.04 LTS. At that point this would be the 3rd official OS re-installation of this server. I chose ubuntu so that I can dist-upgrade from LTS to LTS.
This is a backup server, no need for huge RAM, but for a reliable system. On that storage I have 2m files that in retrospect are not very big. So with the re-installation I chose to use xfs instead of ext4 filesystem.
I am also running an internal snapshot mechanism to have delta for every day and that pushed the storage usage to 87% of the 3Tb. If you do the math, 2m is about 1.2Tb usage, we need a full initial backup, so 2.4Tb (80%) and then the daily (rotate) incremental backups are ~210Mb per day. That gave me space for five (5) daily snapshots aka a work-week.
To remove this impediment, I also replaced the disks with WD Red Pro 6TB 7200rpm disks, and use raid-1 instead of raid-5. Usage is now ~45%
Problem
Frozen System
From time to time, this very new, very clean, very reliable system froze to death!
When attached monitor & keyboard no output. Strange enough I can ping the network interfaces but I can not ssh to the server or even telnet (nc) to ssh port. Awkward! Okay - hardware cold reboot then.
As this system is remote … in random times, I need to ask from someone to cold-reboot this machine. Awkward again.
Kernel Panic
If that was not enough, this machine also has random kernel panics.

Errors
Let’s start troubleshooting this system
# journalctl -p 3 -x
Important Errors
ERST: Failed to get Error Log Address Range.
APEI: Can not request [mem 0x7dfab650-0x7dfab6a3] for APEI BERT registers
ipmi_si dmi-ipmi-si.0: Could not set up I/O spaceand more important Errors:
INFO: task kswapd0:40 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task xfsaild/dm-0:761 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/u9:2:3612 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/1:0:5327 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task rm:5901 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/u9:1:5902 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/0:0:5906 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kswapd0:40 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task xfsaild/dm-0:761 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/u9:2:3612 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
First impressions ?

BootOptions
After a few (hours) of internet research the suggestion is to disable
- ACPI stands for Advanced Configuration and Power Interface.
- APIC stands for Advanced Programmable Interrupt Controller.
This site is very helpful for ubuntu, although Red Hat still has a huge advanced on describing kernel options better than canonical.
Grub
# vim /etc/default/grub
GRUB_CMDLINE_LINUX="noapic acpi=off"then
# update-grub
Sourcing file `/etc/default/grub'
Sourcing file `/etc/default/grub.d/50-curtin-settings.cfg'
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.15.0-54-generic
Found initrd image: /boot/initrd.img-4.15.0-54-generic
Found linux image: /boot/vmlinuz-4.15.0-52-generic
Found initrd image: /boot/initrd.img-4.15.0-52-generic
doneVerify
# grep noapic /boot/grub/grub.cfg | head -1
linux /boot/vmlinuz-4.15.0-54-generic root=UUID=0c686739-e859-4da5-87a2-dfd5fcccde3d ro noapic acpi=off maybe-ubiquityreboot and check again:
# journalctl -p 3 -xb
-- Logs begin at Thu 2019-03-14 19:26:12 EET, end at Wed 2019-07-03 21:31:08 EEST. --
Jul 03 21:30:49 servertwo kernel: ipmi_si dmi-ipmi-si.0: Could not set up I/O spaceokay !!!
ipmi_si
Unfortunately I could not find anything useful regarding
# dmesg | grep -i ipm
[ 10.977914] ipmi message handler version 39.2
[ 11.188484] ipmi device interface
[ 11.203630] IPMI System Interface driver.
[ 11.203662] ipmi_si dmi-ipmi-si.0: ipmi_platform: probing via SMBIOS
[ 11.203665] ipmi_si: SMBIOS: mem 0x0 regsize 1 spacing 1 irq 0
[ 11.203667] ipmi_si: Adding SMBIOS-specified kcs state machine
[ 11.203729] ipmi_si: Trying SMBIOS-specified kcs state machine at mem address 0x0, slave address 0x20, irq 0
[ 11.203732] ipmi_si dmi-ipmi-si.0: Could not set up I/O space
# ipmitool list
Could not open device at /dev/ipmi0 or /dev/ipmi/0 or /dev/ipmidev/0: No such file or directory
# lsmod | grep -i ipmi
ipmi_si 61440 0
ipmi_devintf 20480 0
ipmi_msghandler 53248 2 ipmi_devintf,ipmi_si
blocked for more than 120 seconds.
But let’s try to fix the timeout warnings:
INFO: task kswapd0:40 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this messageif you search online the above message, most of the sites will suggest to tweak dirty pages for your system.
This is the most common response across different sites:
This is a know bug. By default Linux uses up to 40% of the available memory for file system caching. After this mark has been reached the file system flushes all outstanding data to disk causing all following IOs going synchronous. For flushing out this data to disk this there is a time limit of 120 seconds by default. In the case here the IO subsystem is not fast enough to flush the data withing 120 seconds. This especially happens on systems with a lot of memory.
Okay this may be the problem but we do not have a lot of memory, only 2GB RAM and 2GB Swap. But even then, our vm.dirty_ratio = 20 setting is 20% instead of 40%.
But I have the ability to cross-check ubuntu 18.04 with CentOS 6.10 to compare notes:
ubuntu 18.04
# uname -r
4.15.0-54-generic
# sysctl -a | egrep -i 'swap|dirty|raid'|sort
dev.raid.speed_limit_max = 200000
dev.raid.speed_limit_min = 1000
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
vm.dirtytime_expire_seconds = 43200
vm.dirty_writeback_centisecs = 500
vm.swappiness = 60
CentOS 6.11
# uname -r
2.6.32-754.15.3.el6.centos.plus.x86_64
# sysctl -a | egrep -i 'swap|dirty|raid'|sort
dev.raid.speed_limit_max = 200000
dev.raid.speed_limit_min = 1000
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
vm.dirty_writeback_centisecs = 500
vm.swappiness = 60
Scheduler for Raid
This is the best online documentation on the
optimize raid
Comparing notes we see that both systems have the same settings, even when the kernel version is a lot different, 2.6.32 Vs 4.15.0 !!!
Researching on raid optimization there is a note of kernel scheduler.
Ubuntu 18.04
# for drive in {a..c}; do cat /sys/block/sd${drive}/queue/scheduler; done
noop deadline [cfq]
noop deadline [cfq]
noop deadline [cfq]
CentOS 6.11
# for drive in {a..d}; do cat /sys/block/sd${drive}/queue/scheduler; done
noop anticipatory deadline [cfq]
noop anticipatory deadline [cfq]
noop anticipatory deadline [cfq]
noop anticipatory deadline [cfq]
Anticipatory scheduling
CentOS supports Anticipatory scheduling on the hard disks but nowadays anticipatory scheduler is not supported in modern kernel versions.
That said, from the above output we can verify that both systems are running the default scheduler cfq.
Disks
Ubuntu 18.04
- Western Digital Red Pro WDC WD6003FFBX-6
# for i in sd{b..c} ; do hdparm -Tt /dev/$i; done
/dev/sdb:
Timing cached reads: 2344 MB in 2.00 seconds = 1171.76 MB/sec
Timing buffered disk reads: 738 MB in 3.00 seconds = 245.81 MB/sec
/dev/sdc:
Timing cached reads: 2264 MB in 2.00 seconds = 1131.40 MB/sec
Timing buffered disk reads: 774 MB in 3.00 seconds = 257.70 MB/secCentOS 6.11
- Seagate ST1000DX001
/dev/sdb:
Timing cached reads: 2490 MB in 2.00 seconds = 1244.86 MB/sec
Timing buffered disk reads: 536 MB in 3.01 seconds = 178.31 MB/sec
/dev/sdc:
Timing cached reads: 2524 MB in 2.00 seconds = 1262.21 MB/sec
Timing buffered disk reads: 538 MB in 3.00 seconds = 179.15 MB/sec
/dev/sdd:
Timing cached reads: 2452 MB in 2.00 seconds = 1226.15 MB/sec
Timing buffered disk reads: 546 MB in 3.01 seconds = 181.64 MB/sec
So what I am missing ?
My initial personal feeling was the low memory. But after running a manual rsync I’ve realized that:
cpu
was load average: 0.87, 0.46, 0.19
mem
was (on high load), when hit 40% of RAM, started to use swap.
KiB Mem : 2008464 total, 77528 free, 635900 used, 1295036 buff/cache
KiB Swap: 2097148 total, 2096624 free, 524 used. 1184220 avail Mem So I tweaked a bit the swapiness and reduce it from 60% to 40%
and run a local snapshot (that is a bit heavy on the disks) and doing an upgrade and trying to increase CPU load. Still everything is fine !
I will keep an eye on this story.
