Prologue
I should have written this post like a decade ago, but laziness got the better of me.
I use TLS with IMAP and SMTP mail server. That means I encrypt the connection by protocol against the mail server and not by port (ssl Vs tls). Although I do not accept any authentication before STARTTLS command is being provided (that means no cleartext passwords in authentication), I was leaving the PLAIN TEXT authentication mechanism in the configuration. That’s not an actual problem unless you are already on the server and you are trying to connect on localhost but I can do better.
LDAP
I use OpenLDAP as my backend authentication database. Before all, the ldap attribute password must be changed from cleartext to CRAM-MD5
Typing the doveadm command from dovecot with the password method:
# doveadm pw
Enter new password: test
Retype new password: test
{CRAM-MD5}e02d374fde0dc75a17a557039a3a5338c7743304777dccd376f332bee68d2cf6will return the CRAM-MD5 hash of our password (test)
Then we need to edit our DN (distinguished name) with ldapvi:
From:
uid=USERNAME,ou=People,dc=example,dc=org
userPassword: testTo:
uid=USERNAME,ou=People,dc=example,dc=org
userPassword: {CRAM-MD5}e02d374fde0dc75a17a557039a3a5338c7743304777dccd376f332bee68d2cf6Dovecot
Dovecot is not only the imap server but also the “Simple Authentication and Security Layer” aka SASL service. That means that imap & smtp are speaking with dovecot for authentication and dovecot uses ldap as the backend. To change AUTH=PLAIN to cram-md5 we need to do the below change:
file: 10-auth.conf
From:
auth_mechanisms = plain
To:
auth_mechanisms = cram-md5Before restarting dovecot, we need to make one more change. This step took me a couple hours to figure it out! On our dovecot-ldap.conf.ext configuration file, we need to tell dovecot NOT to bind to ldap for authentication but let dovecot to handle the authentication process itself:
From:
# Enable Authentication Binds
# auth_bind = yesTo:
# Enable Authentication Binds
auth_bind = noTo guarantee that the entire connection is protected by TLS encryption, change in 10-ssl.conf the below setting:
From:
ssl = yesTo:
ssl = requiredSSL/TLS is always required, even if non-plaintext authentication mechanisms are used. Any attempt to authenticate before SSL/TLS is enabled will cause an authentication failure.
After that, restart your dovecot instance.
Testing
# telnet example.org imap
Trying 172.12.13.14 ...
Connected to example.org.
Escape character is '^]'.
* OK [CAPABILITY IMAP4rev1 LITERAL+ SASL-IR LOGIN-REFERRALS ID ENABLE IDLE STARTTLS AUTH=CRAM-MD5] Dovecot ready.
1 LOGIN USERNAME@example.org test
1 NO [ALERT] Unsupported authentication mechanism.
^]
telnet> clo
That meas no cleartext authentication is permitted
MUA
Now the hard part, the mail clients:
RainLoop
My default webmail client since v1.10.1.123 supports CRAM-MD5
To verify that, open your application.ini file under your data folder and search for something like that:
imap_use_auth_plain = On
imap_use_auth_cram_md5 = On
smtp_use_auth_plain = On
smtp_use_auth_cram_md5 = Onas a bonus, rainloop supports STARTTLS and authentication for imap & smtp, even when talking to 127.0.0.1
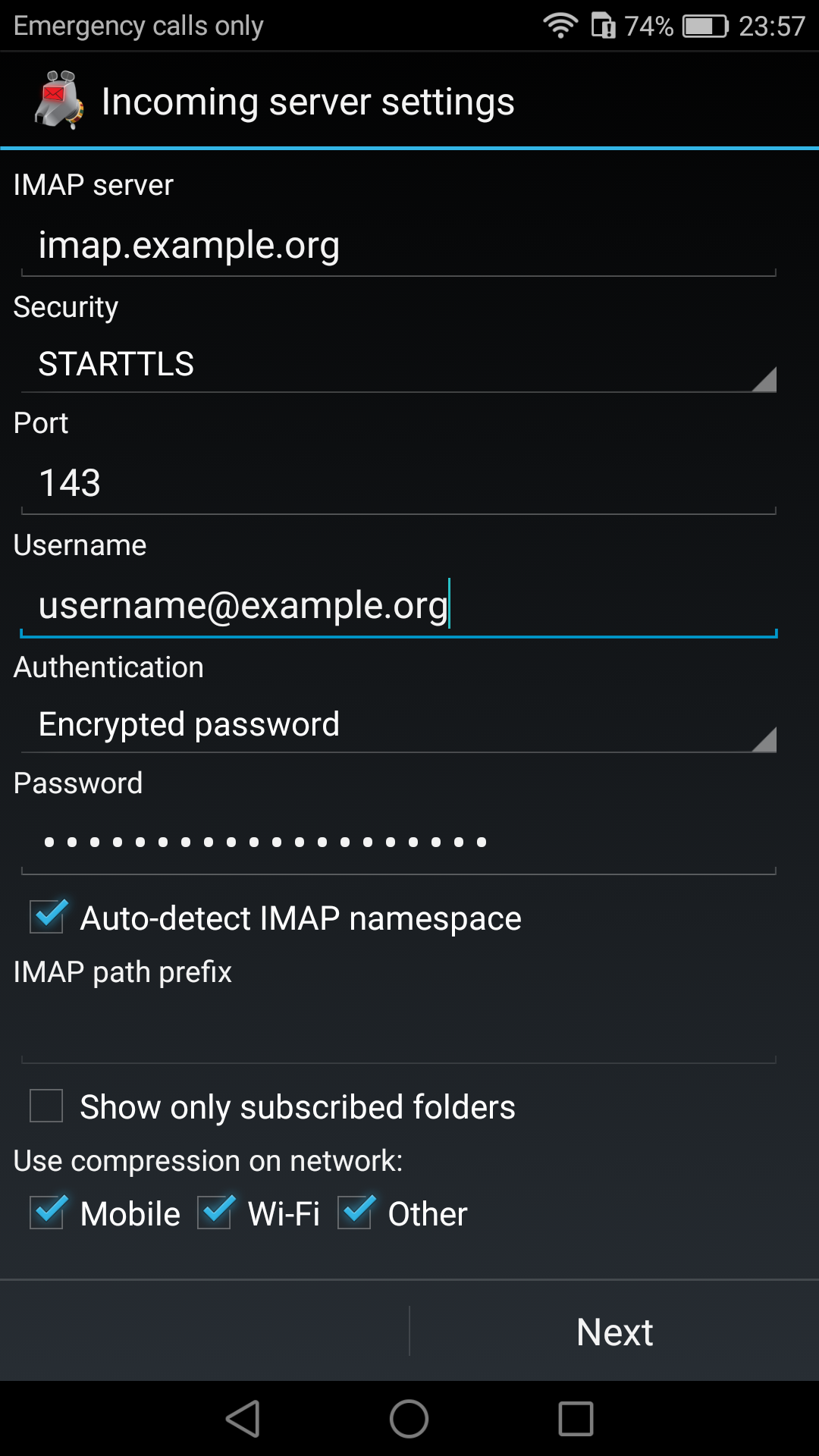
Thunderbird
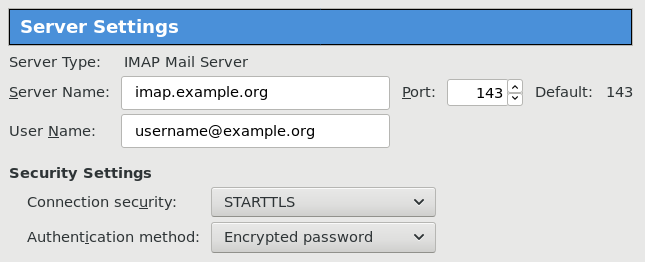
K9



When traveling, I make an effort to visit the local hackerspace. I understand that this is not normal behavior for many people, but for us (free / opensource advocates) is always a must.
This was my 4th week on Bratislava and for the first time, I had a couple free hours to visit ProgressBar HackerSpace.
For now, they are allocated in the middle of the historical city on the 2nd floor. The entrance is on a covered walkway (gallery) between two buildings. There is a bell to ring and automated (when members are already inside) the door is wide open for any visitor. No need to wait or explain why you are there!
Entering ProgressBar there is no doubt that you are entering a hackerspace.

You can view a few photos by clicking here: ProgressBar - Photos
And you can find ProgressBar on OpenStreet Map
Some cool-notable projects:
- bitcoin vending machine
- robot arm to fetch clubmate
- magic wood to switch on/off lights
- blinkwall
- Cool T-shirts
their lab is fool with almost anything you need to play/hack with.
I was really glad to make time and visit them.

An Amazing Book!!!
Must Read !!
I’ve listened to the audiobook like in two days.
Couldnt leave it down.
Then organize a CryptoParty to your local hackerspace
Failures
Every SysAdmin, DevOp, SRE, Computer Engineer or even Developer knows that failures WILL occur. So you need to plan with that constant in mind. Failure causes can be present in hardware, power, operating system, networking, memory or even bugs in software. We often call them system failures but it is possible that a Human can be also the cause of such failure!
Listening to the stories on the latest episode of stack overflow podcast felt compelled to share my own oh-shit moment in recent history.
I am writing this article so others can learn from this story, as I did in the process.
Rolling upgrades
I am a really big fun of rolling upgrades.
I am used to work with server farms. In a nutshell that means a lot of servers connected to their own switch behind routers/load balancers. This architecture gives me a great opportunity when it is time to perform operations, like scheduling service updates in working hours.
eg. Update software version 1.2.3 to 1.2.4 on serverfarm001
The procedure is really easy:
- From the load balancers, stop any new incoming traffic to one of the servers.
- Monitor all processes on the server and wait for them to terminate.
- When all connections hit zero, stop the service you want to upgrade.
- Perform the service update
- Testing
- Monitor logs and possible alarms
- Be ready to rollback if necessary
- Send some low traffic and try to test service with internal users
- When everything is OK, tell the load balancers to send more traffic
- Wait, monitor everything, test, be sure
- Revert changes on the load balancers so that the specific server can take equal traffic/connection as the others.
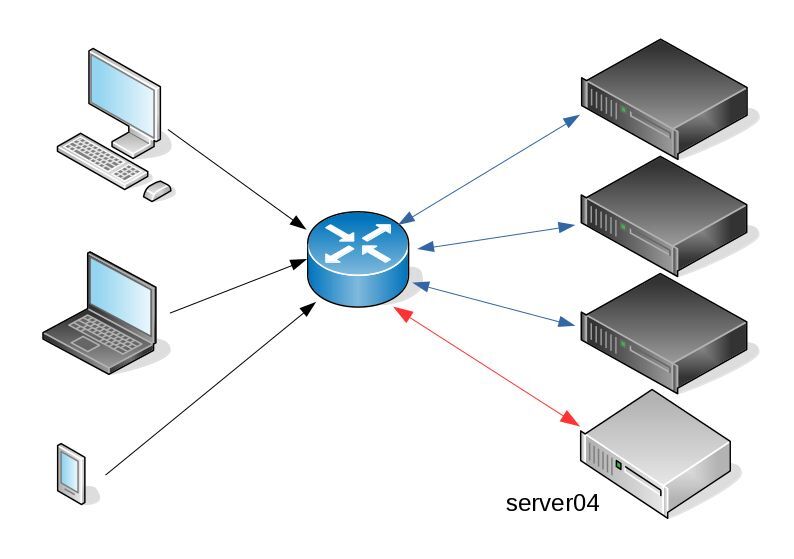
This procedure is well established in such environments, and gives us the benefit of working with the whole team in working hours without the need of scheduling a maintenance window in the middle of the night, when low customer traffic is reaching us. During the day, if something is not going as planned, we can also reach other departments and work with them, figuring out what is happening.
Configuration Management
We are using ansible as the main configuration management tool. Every file, playbook, role, task of ansible is under a version control system, so that we can review changes before applying them to production. Viewing diffs from a modern web tool can be a lifesaver in these days.
Virtualization
We also use docker images or virtual images as development machines, so that we can perform any new configuration, update/upgrade on those machines and test it there.
Ansible Inventory
To perform service updates with ansible on servers, we are using the ansible inventory to host some metadata (aka variables) for every machine in a serverfarm. Let me give you an example:
[serverfarm001]
server01 version=1.2.3
server02 version=1.2.3
server03 version=1.2.3
server04 version=1.2.4And performing the update action via ansible limits
eg.
~> ansible-playbook serverfarm001.yml -t update -C -D -l server04
Rollback
When something is not going as planned, we revert the changes on ansible (version control) and re-push the previous changes on a system. Remember the system is not getting any traffic from the front-end routers.
The Update
I was ready to do the update. Nagios was opened, logs were tailed -f
and then:
~> ansible-playbook serverfarm001.yml -t update
The Mistake
I run the ansible-playbook without limiting the server I wanted to run the update !!!
So all new changes passed through all servers, at once!
On top of that, new configuration broke running software with previous version. When the restart notify of service occurred every server simple stopped!!!
Funny thing, the updated machine server04 worked perfectly, but no traffic was reaching through the load balancers to this server.
Activate Rollback
It was time to run the rollback procedure.
Reverting changes from version control is easy. Took me like a moment or something.
Running again:
~> ansible-playbook serverfarm001.yml
and …
Waiting for Nagios
In 2,5 minutes I had fixed the error and I was waiting for nagios to be green again.
Then … Nothing! Red alerts everywhere!
Oh-Shit Moment
It was time for me to inform everyone what I have done.
Explaining to my colleagues and manager the mistake and trying to figuring out what went wrong with the rollback procedure.
Collaboration
On this crucial moment everything else worked like clockwise.
My colleagues took every action to:
- informing helpdesk
- looking for errors
- tailing logs
- monitor graphs
- viewing nagios
- talking to other people
- do the leg-work in general
and leaving me in piece with calm to figure out what went wrong.
I felt so proud to be part of the team at that specific moment.
If any of you reading this article: Truly thank all guys and gals .
Work-Around
I bypass ansible and copied the correct configuration to all servers via ssh.
My colleagues were telling me the good news and I was going through one by one of ~xx servers.
In 20minutes everything was back in normal.
And finally nagios was green again.
Blameless Post-Mortem
It was time for post-mortem and of course drafting the company’s incident report.
We already knew what happened and how, but nevertheless we need to write everything down and try to keep a good timeline of all steps.
This is not only for reporting but also for us. We need to figure out what happened exactly, do we need more monitoring tools?
Can we place any failsafes in our procedures? Also why the rollback procedure didnt work.
Fixing Rollback
I am writing this paragraph first, but to be honest with you, it took me some time getting to the bottom of this!
Rollback procedure actually is working as planned. I did a mistake with the version control system.
What we have done is to wrap ansible under another script so that we can select the version control revision number at runtime.
This is actually pretty neat, cause it gives us the ability to run ansible with previous versions of our configuration, without reverting in master branch.
The ansible wrapper asks for revision and by default we run it with [tip].
So the correct way to do rollbacks is:
eg.
~> ansible-playbook serverfarm001.yml -rev 238
At the time of problem, I didnt do that. I thought it was better to revert all changes and re-run ansible.
But ansible was running into default mode with tip revision !!
Although I manage pretty well on panic mode, that day my brain was frozen!
Re-Design Ansible
I wrap my head around and tried to find a better solution on performing service updates. I needed to change something that can run without the need of limit in ansible.
The answer has obvious in less than five minutes later:
files/serverfarm001/1.2.3
files/serverfarm001/1.2.4I need to keep a separated configuration folder and run my ansible playbooks with variable instead of absolute paths.
eg.
- copy: src=files/serverfarm001/{{version}} dest=/etc/service/configuration
That will suffice next time (and actually did!). When the service upgrade is finished, We can simple remove the previous configuration folder without changing anything else in ansible.
Ansible Groups
Another (more simplistic) approach is to create a new group in ansible inventory.
Like you do with your staging Vs production environment.
eg.
[serverfarm001]
server01 version=1.2.3
server02 version=1.2.3
server03 version=1.2.3
[serverfarm001_new]
server04 version=1.2.4and create a new yml file
---
- hosts: serverfarm001_new
run the ansible-playbook against the new serverfarm001_new group .
Validation
A lot of services nowadays have syntax check commands for their configuration.
You can use this validation process in ansible!
here is an example from ansible docs:
# Update sshd configuration safely, avoid locking yourself out
- template:
src: etc/ssh/sshd_config.j2
dest: /etc/ssh/sshd_config
owner: root
group: root
mode: '0600'
validate: /usr/sbin/sshd -t -f %s
backup: yesor you can use registers like this:
- name: Check named
shell: /usr/sbin/named-checkconf -t /var/named/chroot
register: named_checkconf
changed_when: "named_checkconf.rc == 0"
notify: anycast rndc reconfigConclusion
Everyone makes mistakes. I know, I have some oh-shit moments in my career for sure. Try to learn from these failures and educate others. Keep notes and write everything down in a wiki or in whatever documentation tool you are using internally. Always keep your calm. Do not hide any errors from your team or your manager. Be the first person that informs everyone. If the working environment doesnt make you feel safe, making mistakes, perhaps you should think changing scenery. You will make a mistake, failures will occur. It is a well known fact and you have to be ready when the time is up. Do a blameless post-mortem. The only way a team can be better is via responsibility, not blame. You need to perform disaster-recovery scenarios from time to time and test your backup. And always -ALWAYS- use a proper configuration management tool for all changes on your infrastructure.
post scriptum
After writing this draft, I had a talk with some friends regarding the cloud industry and how this experience can be applied into such environment. The quick answer is you SHOULD NOT.
Working with cloud, means you are mostly using virtualization. Docker images or even Virtual Machines should be ephemeral. When it’s time to perform upgrades (system patching or software upgrades) you should be creating new virtual machines that will replace the old ones. There is no need to do it in any other way. You can rolling replacing the virtual machines (or docker images) without the need of stopping the service in a machine, do the upgrade, testing, put it back. Those ephemeral machines should not have any data or logs in the first place. Cloud means that you can (auto) scale as needed it without thinking where the data are.
thanks for reading.
CAA
Reading RFC 6844 you will find the definition of “DNS Certification Authority Authorization (CAA) Resource Record”.
You can read everything here: RFC 6844
So, what is CAA anyhow?
Certificate Authority
In a nutshell you are declaring which your Certificate Authority is for your domain.
It’s another way to verify that the certificate your site is announcing is in fact signed by the issuer that the certificate is showing.
So let’s see what my certificate is showing:

DNS
Now, let’s find out what my DNS is telling us:
# dig caa balaskas.gr ;; ANSWER SECTION: balaskas.gr. 5938 IN CAA 1 issue "letsencrypt.org"
Testing
You can also use the Qualys ssl server test:
https://www.ssllabs.com/ssltest/

Postfix
smtp Vs smtpd

- postfix/smtp
- The SMTP daemon is for sending emails to the Internet (outgoing mail server).
- postfix/smtpd
- The SMTP daemon is for receiving emails from the Internet (incoming mail server).
TLS
Encryption on mail transport is what we call: opportunistic. If both parties (sender’s outgoing mail server & recipient’s incoming mail server) agree to exchange encryption keys, then a secure connection may be used. Otherwise a plain connection will be established. Plain as in non-encrypted aka cleartext over the wire.
SMTP - Outgoing Traffic
In the begging there where only three options in postfix:
- none
- may
- encrypt
The default option on a Centos 6x is none:
# postconf -d | grep smtp_tls_security_level smtp_tls_security_level =
Nowadays, postfix supports more options, like:
- dane
- verify
- secure
Here is the basic setup, to enable TLS on your outgoing mail server:
smtp_tls_security_level = may smtp_tls_loglevel = 1
From postfix v2.6 and later, can you disable weak encryption by selecting the cipher suite and protocols you prefer to use:
smtp_tls_ciphers = export smtp_tls_protocols = !SSLv2, !SSLv3
You can also define where the file that holds all the root certificates on your linux server is, and thus to verify the certificate that provides an incoming mail server:
smtp_tls_CAfile = /etc/pki/tls/certs/ca-bundle.crt
I dont recommend to go higher with your setup, cause (unfortunately) not everyone is using TLS on their incoming mail server!
SMTPD - Incoming Traffic
To enable TLS in your incoming mail server, you need to provide some encryption keys aka certificates!
I use letsencrypt on my server and the below notes are based on that.
Let’s Encrypt
A quick explanation on what exists on your letsencrypt folder:
# ls -1 /etc/letsencrypt/live/example.com/ privkey.pem ===> You Private Key cert.pem ===> Your Certificate chain.pem ===> Your Intermediate fullchain.pem ===> Your Certificate with Your Intermediate
Postfix
Below you can find the most basic configuration setup you need for your incoming mail server.
smtpd_tls_ask_ccert = yes smtpd_tls_security_level = may smtpd_tls_loglevel = 1
Your mail server is asking for a certificate so that a trusted TLS connection can be established between outgoing and incoming mail server.
The servers must exchange certificates and of course, verify them!
Now, it’s time to present your own domain certificate to the world. Offering only your public certificate cert.pem isnt enough. You have to offer both your certificate and the intermediate’s certificate, so that the sender’s mail server can verify you, by checking the digital signatures on those certificates.
smtpd_tls_cert_file = /etc/letsencrypt/live/example.com/fullchain.pem smtpd_tls_key_file = /etc/letsencrypt/live/example.com/privkey.pem smtpd_tls_CAfile = /etc/pki/tls/certs/ca-bundle.crt smtpd_tls_CApath = /etc/pki/tls/certs
CAfile & CApath helps postfix to verify the sender’s certificate by looking on your linux distribution file, that holds all the root certificates.
And you can also disable weak ciphers and protocols:
smtpd_tls_ciphers = high smtpd_tls_exclude_ciphers = aNULL, MD5, EXPORT smtpd_tls_protocols = !SSLv2, !SSLv3
Logs
Here is an example from gmail:
SMTPD - Incoming Mail from Gmail
You can see that there is a trusted TLS connection established From google:
Jun 4 11:52:07 kvm postfix/smtpd[14150]:
connect from mail-oi0-x236.google.com[2607:f8b0:4003:c06::236]
Jun 4 11:52:08 kvm postfix/smtpd[14150]:
Trusted TLS connection established from mail-oi0-x236.google.com[2607:f8b0:4003:c06::236]:
TLSv1.2 with cipher ECDHE-RSA-AES128-GCM-SHA256 (128/128 bits)
Jun 4 11:52:09 kvm postfix/smtpd[14150]:
4516420F32: client=mail-oi0-x236.google.com[2607:f8b0:4003:c06::236]
Jun 4 11:52:10 kvm postfix/smtpd[14150]:
disconnect from mail-oi0-x236.google.com[2607:f8b0:4003:c06::236]
SMTP - Outgoing Mail from Gmail
And this is the response To gmail :
Jun 4 12:01:32 kvm postfix/smtpd[14808]:
initializing the server-side TLS engine
Jun 4 12:01:32 kvm postfix/smtpd[14808]:
connect from example.com[2a00:1838:20:1::XXXX:XXXX]
Jun 4 12:01:33 kvm postfix/smtpd[14808]:
setting up TLS connection from example.com[2a00:1838:20:1::XXXX:XXXX]
Jun 4 12:01:33 kvm postfix/smtpd[14808]:
example.com[2a00:1838:20:1::XXXX:XXXX]: TLS cipher list "aNULL:-aNULL:ALL:!EXPORT:!LOW:!MEDIUM:+RC4:@STRENGTH:!aNULL:!MD5:!EXPORT:!aNULL"
Jun 4 12:01:33 kvm postfix/smtpd[14808]:
Anonymous TLS connection established from example.com[2a00:1838:20:1::XXXX:XXXX]:
TLSv1.2 with cipher ECDHE-RSA-AES128-GCM-SHA256 (128/128 bits)
Jun 4 12:01:35 kvm postfix/smtpd[14808]:
disconnect from example.com[2a00:1838:20:1::XXXX:XXXX]
As you can see -In both cases (sending/receiving)- the mail servers have established a trusted secure TLSv1.2 connection.
The preferred cipher (in both scenarios) is : ECDHE-RSA-AES128-GCM-SHA256
IPv6
Tell postfix to prefer ipv6 Vs ipv4 and use TLS if two mail servers support it !
#IPv6 smtp_address_preference = ipv6