Elasticsearch, Logstash, Kibana or ELK Crash Course 101
Prologue aka Disclaimer
This blog post is the outcome of a Hackerspace Event:: Logstash Intro Course that happened a few days ago. I prefer doing workshops Vs presentations -as I pray to the Live-Coding Gods- and this is the actual workshop in bulletin notes.
Objectives
For our technical goal we will use my fail2ban !
We will figure (together) whom I ban with my fail2ban!!!
The results we want to present are:
| Date | IP | Country |
|---|
To help you with this inquiry, we will use this dataset: fail2ban.gz
If you read though this log you will see that it’s a grep from my messages logs.
So in the begging we have messages from compressed files … and in the end we have messages from uncompressed files.
But … Let’s begin with our journey !!
Prerequisite
For our little experiment we need Java
I Know, I know … not the beverage - the programming language !!
try java 1.7.x
# java -version
java version "1.7.0_111"
OpenJDK Runtime Environment (IcedTea 2.6.7) (Arch Linux build 7.u111_2.6.7-1-x86_64)
OpenJDK 64-Bit Server VM (build 24.111-b01, mixed mode)
In my archlinux machine:
# yes | pacman -S jdk7-openjdkVersions
As, October 26, 2016 all versions (logstash,elastic,kibana) are all in version 5.0.x and latests.
But we will try the well-known installed previous versions !!!
as from 5.0.x and later …. we have: Breaking changes and you will need Java 8
Download
Let’s download software
# wget -c https://download.elastic.co/logstash/logstash/logstash-2.4.1.zip
# wget -c https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-2.4.1.zip
# wget -c https://download.elastic.co/kibana/kibana/kibana-4.6.3-linux-x86_64.tar.gz
Logstash
Uncompress and test that logstash can run without a problem:
# unzip logstash-2.4.1.zip
# cd logstash-2.4.1
# logstash-2.4.1/
# ./bin/logstash --version
logstash 2.4.1
# ./bin/logstash --help
Basic Logstash Example
Reminder: Ctrl+c breaks the logstash
# ./bin/logstash -e 'input { stdin { } } output { stdout {} }'
We are now ready to type ‘Whatever’ and see what happens:
# ./bin/logstash -e 'input { stdin { } } output { stdout {} }'
Settings: Default pipeline workers: 4
Pipeline main startedwhatever
2016-11-15T19:18:09.638Z myhomepc whatever
Ctrl + c
Ctrl + c
^CSIGINT received. Shutting down the agent. {:level=>:warn}
stopping pipeline {:id=>"main"}
Received shutdown signal, but pipeline is still waiting for in-flight events
to be processed. Sending another ^C will force quit Logstash, but this may cause
data loss. {:level=>:warn}
^CSIGINT received. Terminating immediately.. {:level=>:fatal}
Standard Input and Standard Output
In this first example the input is our standard input, that means keyboard
and standard output means our display.
We typed:
whateverand logstash reports:
2016-11-15T19:18:09.638Z myhomepc whatever
There are three (3) fields:
- timestamp : 2016-11-15T19:18:09.638Z
- hostname : myhomepc
- message : whatever
Logstash Architecture

Logstash architecture reminds me Von Neumann .
Input --> Process --> Output In Process we have filter plugins and in input pluggins & output plugins we have codec plugins
Codec plugins
We can define the data representation (logs or events) via codec plugins. Most basic codec plugin is: rubydebug
rubydebug
eg. logstash -e ‘input { stdin { } } output { stdout { codec => rubydebug} }’
# ./bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug} }'
Settings: Default pipeline workers: 4
Pipeline main started
whatever
{
"message" => "whatever",
"@version" => "1",
"@timestamp" => "2016-11-15T19:40:46.070Z",
"host" => "myhomepc"
}
^CSIGINT received. Shutting down the agent. {:level=>:warn}
stopping pipeline {:id=>"main"}
^CSIGINT received. Terminating immediately.. {:level=>:fatal}
json
Let’s try the json codec plugin, but now we will try it via a linux pipe:
# echo whatever | ./bin/logstash -e 'input { stdin { } } output { stdout { codec => json } }'
Settings: Default pipeline workers: 4
Pipeline main started
{"message":"whatever","@version":"1","@timestamp":"2016-11-15T19:48:44.127Z","host":"myhomepc"}
Pipeline main has been shutdown
stopping pipeline {:id=>"main"}
json_lines
# echo -e 'whatever1nwhatever2nn' | ./bin/logstash -e 'input { stdin { } } output { stdout { codec => json_lines } }'
Settings: Default pipeline workers: 4
Pipeline main started
{"message":"whatever1","@version":"1","@timestamp":"2016-11-15T19:50:12.311Z","host":"myhomepc"}
{"message":"whatever2","@version":"1","@timestamp":"2016-11-15T19:50:12.324Z","host":"myhomepc"}
Pipeline main has been shutdown
stopping pipeline {:id=>"main"}
List of codec
Here is the basic list of codec:
avro
cef
compress_spooler
cloudtrail
cloudfront
collectd
dots
edn_lines
edn
es_bulk
fluent
gzip_lines
graphite
json_lines
json
line
msgpack
multiline
netflow
nmap
oldlogstashjson
plain
rubydebug
s3_plainConfiguration File
It is now very efficient to run everything from the command line, so we will try to move to a configuration file:
logstash.conf
input {
stdin { }
}
output {
stdout {
codec => rubydebug
}
}
and run the above example once more:
# echo -e 'whatever1nwhatever2' | ./bin/logstash -f logstash.conf
Settings: Default pipeline workers: 4
Pipeline main started
{
"message" => "whatever1",
"@version" => "1",
"@timestamp" => "2016-11-15T19:59:51.146Z",
"host" => "myhomepc"
}
{
"message" => "whatever2",
"@version" => "1",
"@timestamp" => "2016-11-15T19:59:51.295Z",
"host" => "myhomepc"
}
Pipeline main has been shutdown
stopping pipeline {:id=>"main"}
Config Test
Every time you need to test your configuration file for syntax check:
./bin/logstash --configtest
Configuration OK
fail2ban - logstash 1st try
Now it’s time to test our fail2ban file against our logstash setup. To avoid the terror of 22k lines, we will test the first 10 lines to see how it works:
# head ../fail2ban | ./bin/logstash -f logstash.conf
Settings: Default pipeline workers: 4
Pipeline main started
{
"message" => "messages-20160918.gz:Sep 11 09:13:13 myhostname fail2ban.actions[1510]: NOTICE [apache-badbots] Unban 93.175.200.191",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.784Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 09:51:08 myhostname fail2ban.actions[1510]: NOTICE [apache-badbots] Unban 186.125.190.156",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.966Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 11:51:24 myhostname fail2ban.filter[1510]: INFO [apache-badbots] Found 37.49.225.180",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.967Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 11:51:24 myhostname fail2ban.actions[1510]: NOTICE [apache-badbots] Ban 37.49.225.180",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.968Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 14:58:35 myhostname fail2ban.filter[1510]: INFO [postfix-sasl] Found 185.40.4.126",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.968Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 14:58:36 myhostname fail2ban.actions[1510]: NOTICE [postfix-sasl] Ban 185.40.4.126",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.969Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 15:03:08 myhostname fail2ban.filter[1510]: INFO [apache-fakegooglebot] Ignore 66.249.69.88 by command",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.970Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 15:03:08 myhostname fail2ban.filter[1510]: INFO [apache-fakegooglebot] Ignore 66.249.76.55 by command",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.970Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 15:26:04 myhostname fail2ban.filter[1510]: INFO [apache-fakegooglebot] Ignore 66.249.76.53 by command",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.971Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 17:01:02 myhostname fail2ban.filter[1510]: INFO [apache-badbots] Found 93.175.200.191",
"@version" => "1",
"@timestamp" => "2016-11-15T20:10:40.971Z",
"host" => "myhomepc"
}
Pipeline main has been shutdown
stopping pipeline {:id=>"main"}
fail2ban - filter
As we said in the begging of our journey, we want to check what IPs I Ban with fail2ban !!
So we need to filter the messages. Reading through our dataset, we will soon find out that we need lines like:
"messages-20160918.gz:Sep 11 11:51:24 myhostname fail2ban.actions[1510]: NOTICE [apache-badbots] Ban 37.49.225.180"so we could use an if-statement (conditional statements).
fail2ban - Conditionals
You can use the following comparison operators:
equality: ==, !=, <, >, <=, >=
regexp: =~, !~ (checks a pattern on the right against a string value on the left)
inclusion: in, not in
The supported boolean operators are:
and, or, nand, xor
The supported unary operators are:
!
Expressions can be long and complex.
fail2ban - message filter
With the above knowledge, our logstash configuration file can now be:
logstash.conf
input {
stdin { }
}
filter {
if [message] !~ ' Ban ' {
drop { }
}
}
output {
stdout {
codec => rubydebug
}
}
and the results:
# head ../fail2ban | ./bin/logstash -f logstash.conf -v
{
"message" => "messages-20160918.gz:Sep 11 11:51:24 myhostname fail2ban.actions[1510]: NOTICE [apache-badbots] Ban 37.49.225.180",
"@version" => "1",
"@timestamp" => "2016-11-15T20:33:39.858Z",
"host" => "myhomepc"
}
{
"message" => "messages-20160918.gz:Sep 11 14:58:36 myhostname fail2ban.actions[1510]: NOTICE [postfix-sasl] Ban 185.40.4.126",
"@version" => "1",
"@timestamp" => "2016-11-15T20:33:39.859Z",
"host" => "myhomepc"
}
but we are pretty far away from our goal.
The above approach is just fine for our example, but it is far away from perfect or even elegant !
And here is way: the regular expression ‘ Ban ‘ is just that, a regular expression.
The most elegant approach is to match the entire message and drop everything else. Then we could be most certain sure about the output of the logs.
grok
And here comes grok !!!
and to do that we must learn the grok:
Parses unstructured event data into fieldsthat would be extremely useful. Remember, we have a goal!
We dont need everything, we need the date, ip & country !!
Grok Patterns
grok work with patterns, that follows the below generic rule:
%{SYNTAX:SEMANTIC}
You can use the online grok debugger: grok heroku
to test your messages/logs/events against grok patterns
If you click on the left grok-patterns you will see the most common grok patterns.
In our setup:
# find . -type d -name patterns
./vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/lib/logstash/patterns
./vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns
the latest directory is where our logstansh instance keeps the default grok patterns.
To avoid the suspense … here is the full grok pattern:
messages%{DATA}:%{SYSLOGTIMESTAMP} %{HOSTNAME} %{SYSLOGPROG}: %{LOGLEVEL} [%{PROG}] Ban %{IPV4}grok - match
If you run this new setup, we will see something peculiar:
logstash.conf
input {
stdin { }
}
filter {
# if [message] !~ ' Ban ' {
# drop { }
# }
grok {
match => {
"message" => "messages%{DATA}:%{SYSLOGTIMESTAMP} %{HOSTNAME} %{SYSLOGPROG}: %{LOGLEVEL} [%{PROG}] Ban %{IPV4}"
}
}
}
output {
stdout {
codec => rubydebug
}
}
We will get messages like these:
{
"message" => "messages:Nov 15 17:49:09 myhostname fail2ban.actions[1585]: NOTICE [apache-fakegooglebot] Ban 66.249.76.67",
"@version" => "1",
"@timestamp" => "2016-11-15T21:30:29.345Z",
"host" => "myhomepc",
"program" => "fail2ban.actions",
"pid" => "1585"
}
{
"message" => "messages:Nov 15 17:49:31 myhostname fail2ban.action[1585]: ERROR /etc/fail2ban/filter.d/ignorecommands/apache-fakegooglebot 66.249.76.104 -- stdout: ''",
"@version" => "1",
"@timestamp" => "2016-11-15T21:30:29.346Z",
"host" => "myhomepc",
"tags" => [
[0] "_grokparsefailure"
]
}
It match some of them and the all the rest are tagged with grokparsefailure
We can remove them easily:
logstash.conf
input {
stdin { }
}
filter {
# if [message] !~ ' Ban ' {
# drop { }
# }
grok {
match => {
"message" => "messages%{DATA}:%{SYSLOGTIMESTAMP} %{HOSTNAME} %{SYSLOGPROG}: %{LOGLEVEL} [%{PROG}] Ban %{IPV4}"
}
}
if "_grokparsefailure" in [tags] {
drop { }
}
}
output {
stdout {
codec => rubydebug
}
}Using colon (:) character on SYNTAX grok pattern is a new field for grok / logstash.
So we can change a little bit the above grok pattern to this:
messages%{DATA}:%{SYSLOGTIMESTAMP} %{HOSTNAME} %{PROG}(?:[%{POSINT}])?: %{LOGLEVEL} [%{PROG}] Ban %{IPV4}but then again, we want to filter some fields, like the date and IP, so
messages%{DATA}:%{SYSLOGTIMESTAMP:date} %{HOSTNAME} %{PROG}(?:[%{POSINT}])?: %{LOGLEVEL} [%{PROG}] Ban %{IPV4:ip}logstash.conf
input {
stdin { }
}
filter {
# if [message] !~ ' Ban ' {
# drop { }
# }
grok {
match => {
"message" => "messages%{DATA}:%{SYSLOGTIMESTAMP:date} %{HOSTNAME} %{PROG}(?:[%{POSINT}])?: %{LOGLEVEL} [%{PROG}] Ban %{IPV4:ip}"
}
}
if "_grokparsefailure" in [tags] {
drop { }
}
}
output {
stdout {
codec => rubydebug
}
}
output will be like this:
"message" => "messages:Nov 15 17:49:32 myhostname fail2ban.actions[1585]: NOTICE [apache-fakegooglebot] Ban 66.249.76.104",
"@version" => "1",
"@timestamp" => "2016-11-15T21:42:21.260Z",
"host" => "myhomepc",
"date" => "Nov 15 17:49:32",
"ip" => "66.249.76.104"
}
grok - custom pattern
If we want to match something specific with to a custom grok pattern, we can simple add one!
For example, we want to match Ban and Unban action:
# vim ./vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns/ebalACTION (Ban|Unban)and then our grok matching line will transform to :
logstash.conf
input {
stdin { }
}
filter {
# if [message] !~ ' Ban ' {
# drop { }
# }
grok {
match => {
# "message" => "messages%{DATA}:%{SYSLOGTIMESTAMP:date} %{HOSTNAME} %{PROG}(?:[%{POSINT}])?: %{LOGLEVEL} [%{PROG}] Ban %{IPV4:ip}"
"message" => "messages%{DATA}:%{SYSLOGTIMESTAMP:date} %{HOSTNAME} %{PROG}(?:[%{POSINT}])?: %{LOGLEVEL} [%{PROG}] %{ACTION:action} %{IPV4:ip}"
}
}
if "_grokparsefailure" in [tags] {
drop { }
}
}
output {
stdout {
codec => rubydebug
}
}
output:
{
"message" => "messages:Nov 15 18:13:53 myhostname fail2ban.actions[1585]: NOTICE [apache-badbots] Unban 41.82.165.220",
"@version" => "1",
"@timestamp" => "2016-11-15T21:53:59.634Z",
"host" => "myhomepc",
"date" => "Nov 15 18:13:53",
"action" => "Unban",
"ip" => "41.82.165.220"
}
mutate
We are getting pretty close … the most difficult part is over (grok patterns).
Just need to remove any exta fields. We can actually do that with two ways:
- grok - remove_field
- mutate -remove_field
We’ll try mutate cause is more powerful.
And for our example/goal we will not use any custom extra Action field, so:
logstash.conf
input {
stdin { }
}
filter {
# if [message] !~ ' Ban ' {
# drop { }
# }
grok {
match => {
"message" => "messages%{DATA}:%{SYSLOGTIMESTAMP:date} %{HOSTNAME} %{PROG}(?:[%{POSINT}])?: %{LOGLEVEL} [%{PROG}] Ban %{IPV4:ip}"
# "message" => "messages%{DATA}:%{SYSLOGTIMESTAMP:date} %{HOSTNAME} %{PROG}(?:[%{POSINT}])?: %{LOGLEVEL} [%{PROG}] %{ACTION:action} %{IPV4:ip}"
}
}
if "_grokparsefailure" in [tags] {
drop { }
}
mutate {
remove_field => [ "message", "@version", "@timestamp", "host" ]
}
}
output {
stdout {
codec => rubydebug
}
}
results:
{
"date" => "Nov 15 17:49:32",
"ip" => "66.249.76.104"
}so close !!!
mutate - replace
According to syslog RFC (request for comments) [RFC 3164 - RFC 3195]:
In particular, the timestamp has a year, making it a nonstandard formatso most of logs doesnt have a YEAR on their timestamp !!!
Logstash can add an extra field or replace an existing field :
logstash.conf
input {
stdin { }
}
filter {
# if [message] !~ ' Ban ' {
# drop { }
# }
grok {
match => {
"message" => "messages%{DATA}:%{SYSLOGTIMESTAMP:date} %{HOSTNAME} %{PROG}(?:[%{POSINT}])?: %{LOGLEVEL} [%{PROG}] Ban %{IPV4:ip}"
# "message" => "messages%{DATA}:%{SYSLOGTIMESTAMP:date} %{HOSTNAME} %{PROG}(?:[%{POSINT}])?: %{LOGLEVEL} [%{PROG}] %{ACTION:action} %{IPV4:ip}"
}
}
if "_grokparsefailure" in [tags] {
drop { }
}
mutate {
remove_field => [ "message", "@version", "@timestamp", "host" ]
replace => { date => "%{+YYYY} %{date}" }
}
}
output {
stdout {
codec => rubydebug
}
}the output:
{
"date" => "2016 Nov 15 17:49:32",
"ip" => "66.249.76.104"
}GeoIP
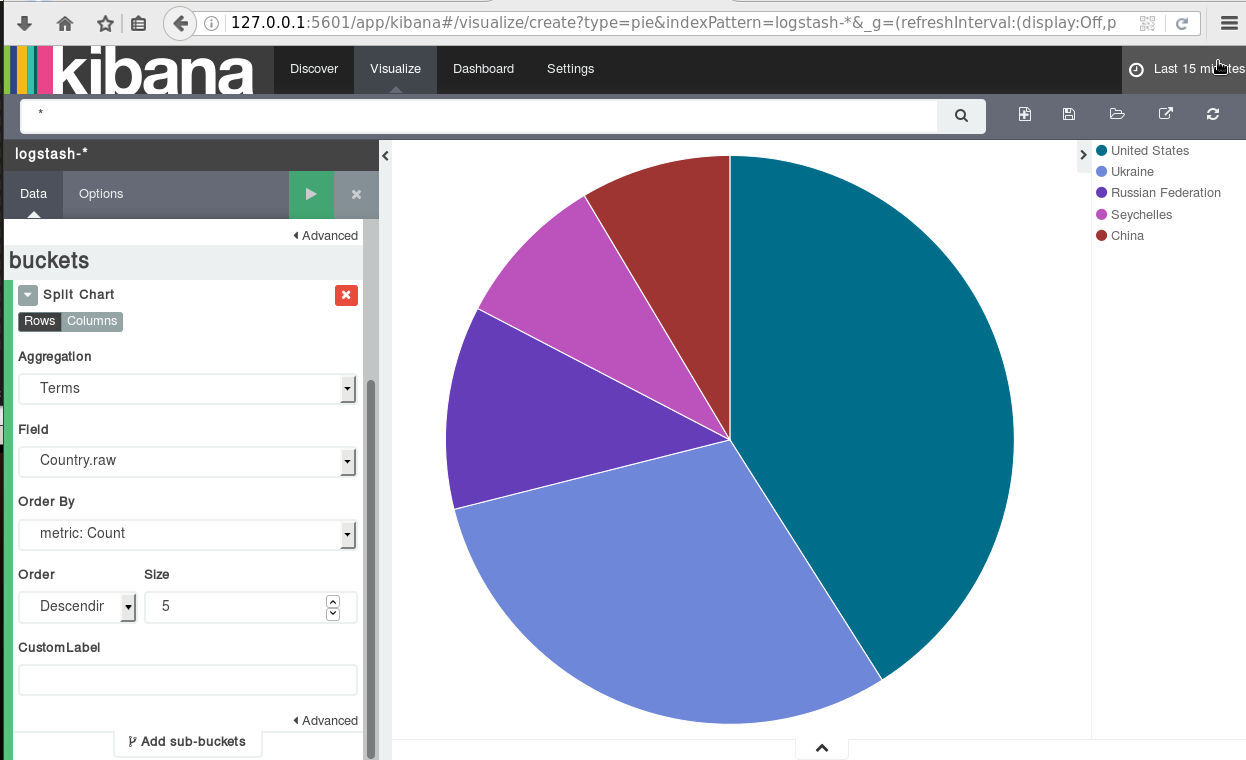
The only thing that is missing from our original goal, is the country field!
Logstash has a geoip plugin that works perfectly with MaxMind
So we need to download the GeoIP database:
# wget -N http://geolite.maxmind.com/download/geoip/database/GeoLiteCountry/GeoIP.dat.gz
The best place is to put this file (uncompressed) under your logstash directory.
Now, it’s time to add the geoip support to the logstash.conf :
# Add Country Name
# wget -N http://geolite.maxmind.com/download/geoip/database/GeoLiteCountry/GeoIP.dat.gz
geoip {
source => "ip"
target => "geoip"
fields => ["country_name"]
database => "GeoIP.dat"
# database => "/etc/logstash/GeoIP.dat"
}the above goes under the filter section of logstash conf file.
running the above configuration
# head ../fail2ban | ./bin/logstash -f logstash.confshould display something like this:
{
"date" => "2016 Sep 11 11:51:24",
"ip" => "37.49.225.180",
"geoip" => {
"country_name" => "Netherlands"
}
}
{
"date" => "2016 Sep 11 14:58:36",
"ip" => "185.40.4.126",
"geoip" => {
"country_name" => "Russian Federation"
}
}
We are now pretty close to our primary objective.
rename
It would be nice to somehow translate the geoip –> country_name to something more useful, like Country.
That’s why we are going to use the rename setting under the mutate plugin:
mutate {
rename => { "[geoip][country_name]" => "Country" }
}so let’s put all them together:
geoip {
source => "ip"
target => "geoip"
fields => ["country_name"]
database => "GeoIP.dat"
}
mutate {
rename => { "[geoip][country_name]" => "Country" }
remove_field => [ "message", "@version", "@timestamp", "host", "geoip"]
replace => { date => "%{+YYYY} %{date}" }
}
test run it and the output will show you something like that:
{
"date" => "2016 Sep 11 11:51:24",
"ip" => "37.49.225.180",
"Country" => "Netherlands"
}
{
"date" => "2016 Sep 11 14:58:36",
"ip" => "185.40.4.126",
"Country" => "Russian Federation"
}
hurray !!!
finally we have completed our primary objective.
Input - Output
Input File
Until now, you have been reading from the standard input, but it’s time to read from the file.
To do so, we must add the bellow settings under the input section:
file {
path => "/var/log/messages"
start_position => "beginning"
}Testing our configuration file (without giving input from the command line):
./bin/logstash -f logstash.conf
and the output will be something like this:
{
"path" => "/var/log/messages",
"date" => "2016 Nov 15 17:49:09",
"ip" => "66.249.76.67",
"Country" => "United States"
}
{
"path" => "/var/log/messages",
"date" => "2016 Nov 15 17:49:32",
"ip" => "66.249.76.104",
"Country" => "United States"
}so by changing the input from the standard input to a file path, we added a new extra filed.
The path
Just remove it with mutate –> remove_field as we already shown above
Output
Now it’s time to send everything to our elastic search engine:
output {
# stdout {
# codec => rubydebug
# }
elasticsearch {
}
}
Be Careful: In our above examples we have removed the timestamp field
but for the elasticsearch to work, we must enable it again:
remove_field => [ "message", "@version", "host", "geoip"]Elasticsearch
Uncompress and run elastic search engine:
# unzip elasticsearch-2.4.1.zip
# cd elasticsearch-2.4.1/
# ./bin/elasticsearchelasticsearch is running under:
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 27862/java
tcp6 0 0 127.0.0.1:9300 :::* LISTEN 27862/java
Impressive, but that’s it!
Status
Let’s find out if the elasticsearch engine is running:
$ curl 'localhost:9200/_cat/health?v'
$ curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1482421814 17:50:14 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
$ curl 'localhost:9200/_cat/nodes?v'
host ip heap.percent ram.percent load node.role master name
127.0.0.1 127.0.0.1 7 98 0.50 d * Hazmat
# curl -s -XGET 'http://localhost:9200/_cluster/health?level=indices' | jq .
logstash
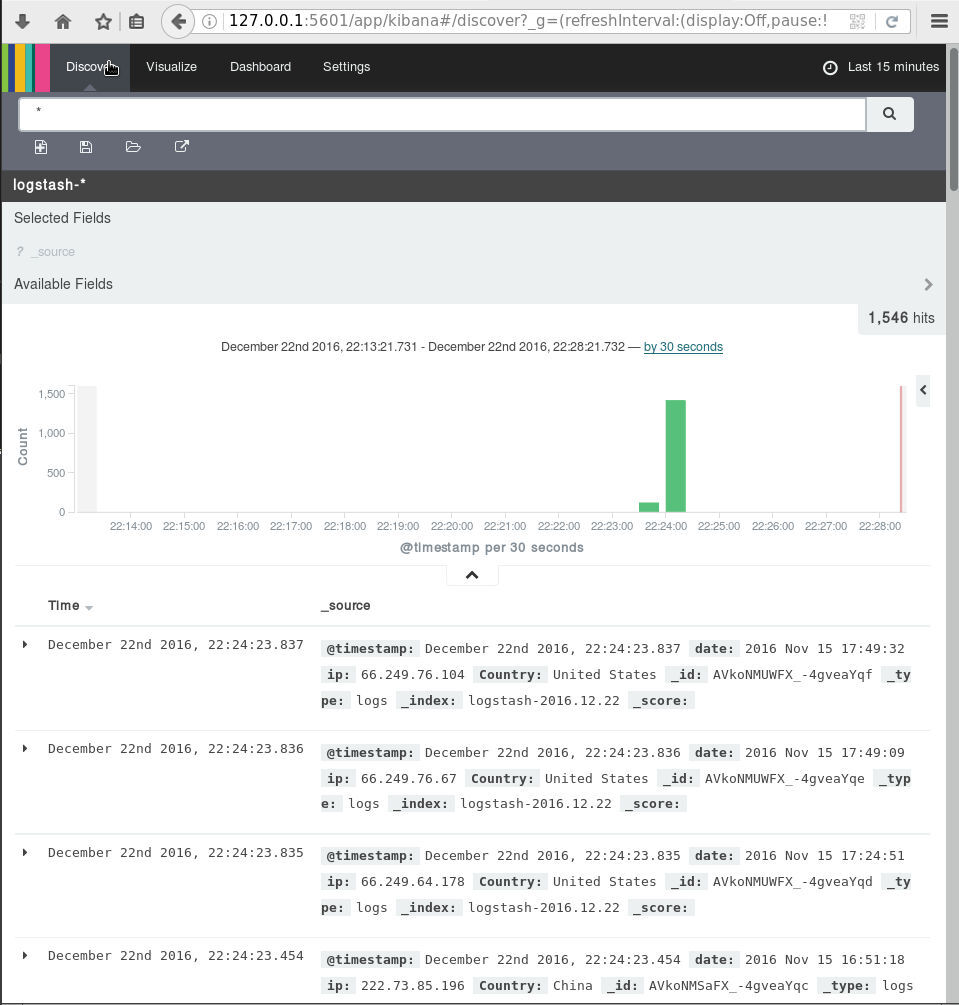
Now it’s time to send our data to our elastic search engine, running the logstash daemon with input the fail2ban file and output the elastic search.
Kibana
We are almost done. There is only one more step to our 101 course for ELK infrastructure.
And that is the kibana dashboard.
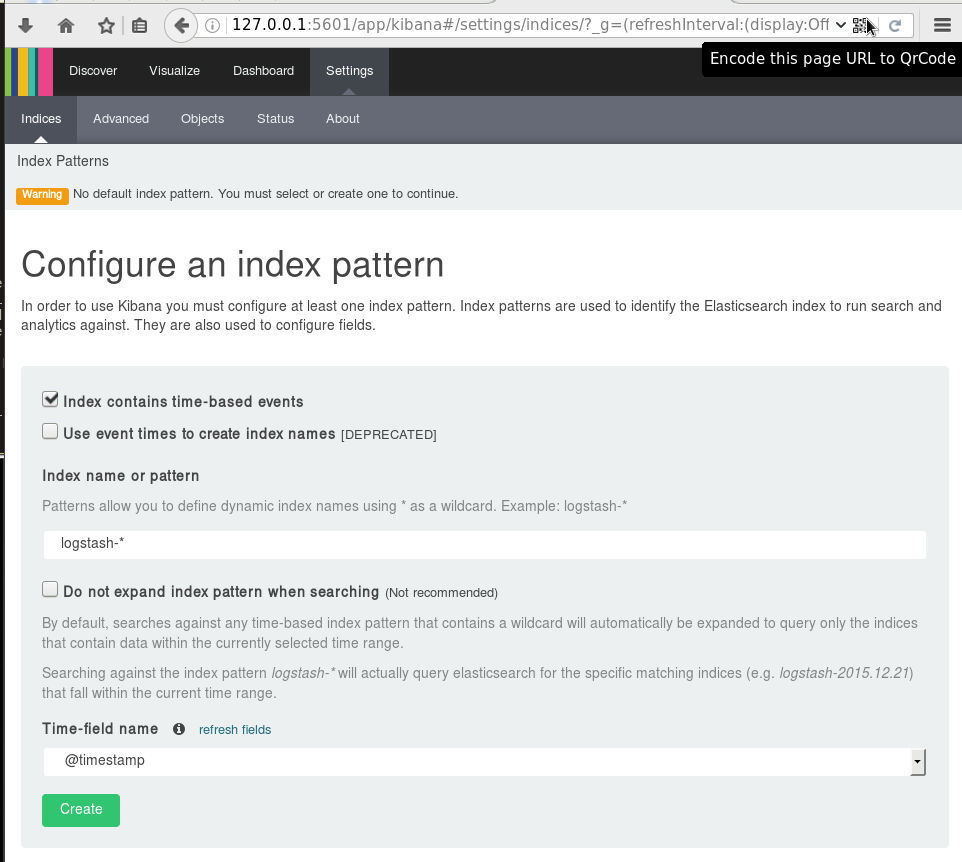
setup kibana
Uncompress and run the kibana dashboard:
tar xf kibana-4.6.3-linux-x86_64.tar.gz
./bin/kibana
dashboard
Now simply, open the kibana dashboard on:
A visual guide on how to enlarge your windows disk image aka windows extend volume
I have a windows 10 qemu-kvm virtual machine for business purposes.
Every now and then, I have to resize it’s disk image!
This is my visual guide, so next time I will not waste any time figure this out, again!
Resize Disk image
The first step is to resize the disk image from the command line:
# ls -l win10.qcow2
-rw-r--r-- 1 root root 58861813760 Nov 17 10:04 win10.qcow2
# du -h win10.qcow2
55G win10.qcow2
# qemu-img info win10.qcow2
image: win10.qcow2
file format: qcow2
virtual size: 55G (59055800320 bytes)
disk size: 55G
cluster_size: 65536
Format specific information:
compat: 1.1
lazy refcounts: false
refcount bits: 16
corrupt: false
# qemu-img resize win10.qcow2 +10G
Image resized.
# qemu-img info win10.qcow2
image: win10.qcow2
file format: qcow2
virtual size: 65G (69793218560 bytes)
disk size: 55G
cluster_size: 65536
Format specific information:
compat: 1.1
lazy refcounts: false
refcount bits: 16
corrupt: false
Windows Problem - extend volume
Windows can not extend a volume if the free partition is not next to the “need-to-be” extened volume.
So we have to move the free partition next to C: drive
System Rescue Cd
Here comes system rescue cd !
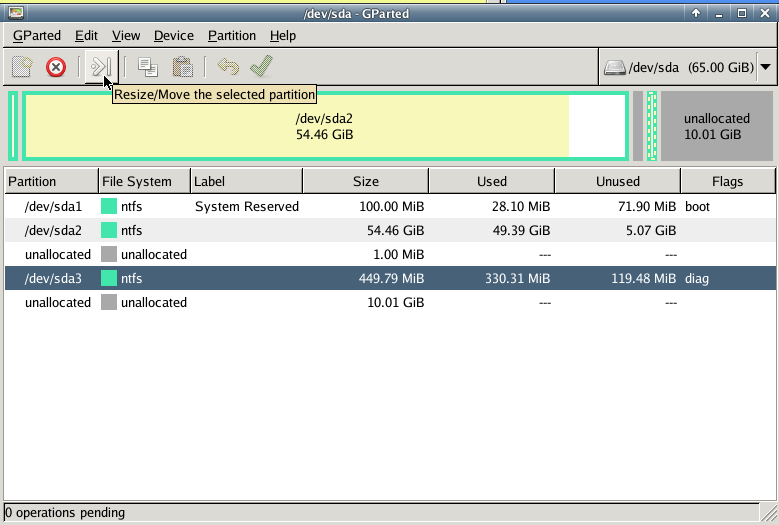
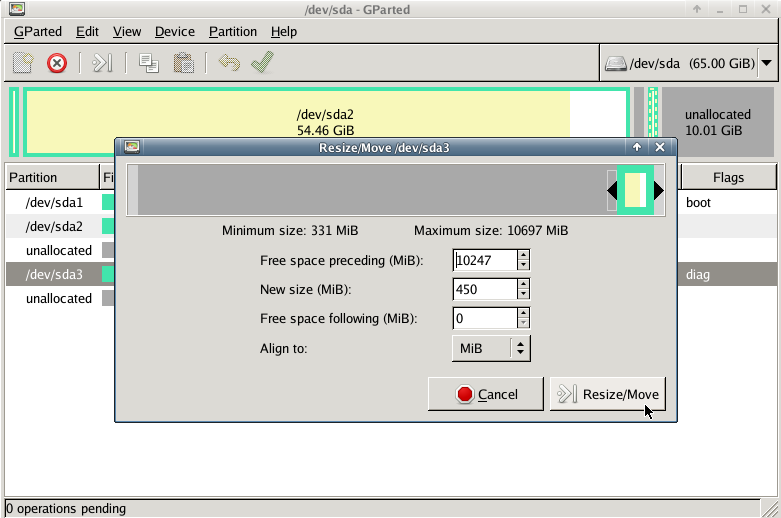
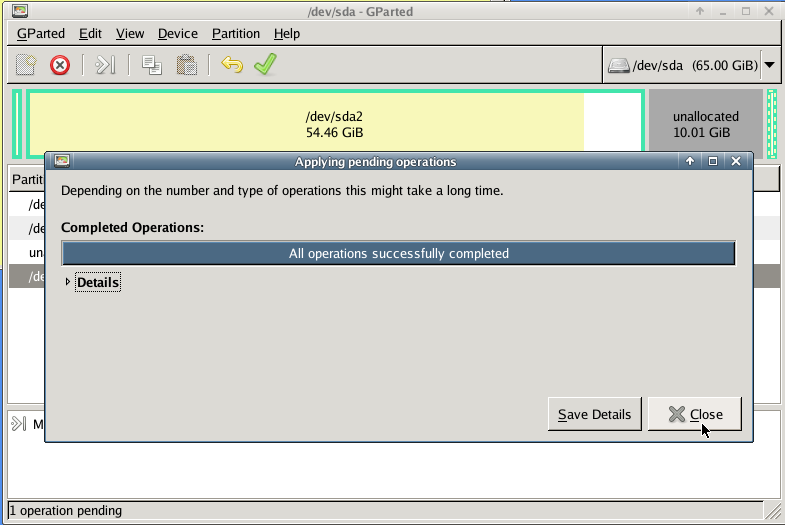
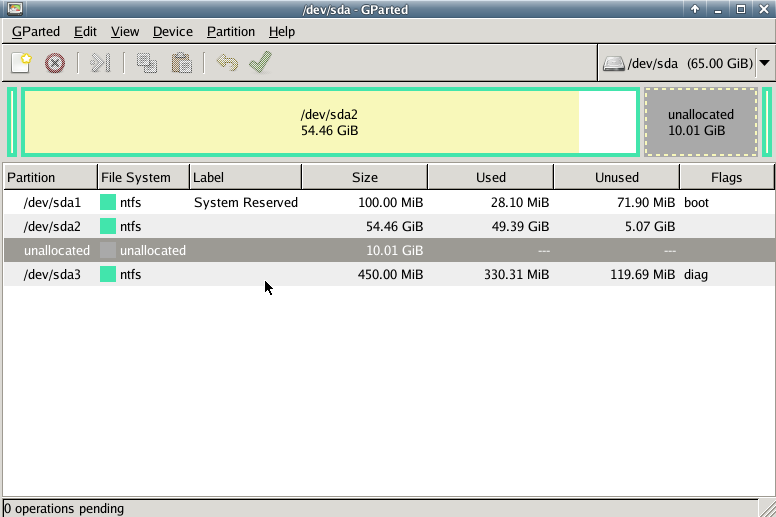
Gparted
with gparted you can move to the end of the virtual disk the ntfs recovery partition:
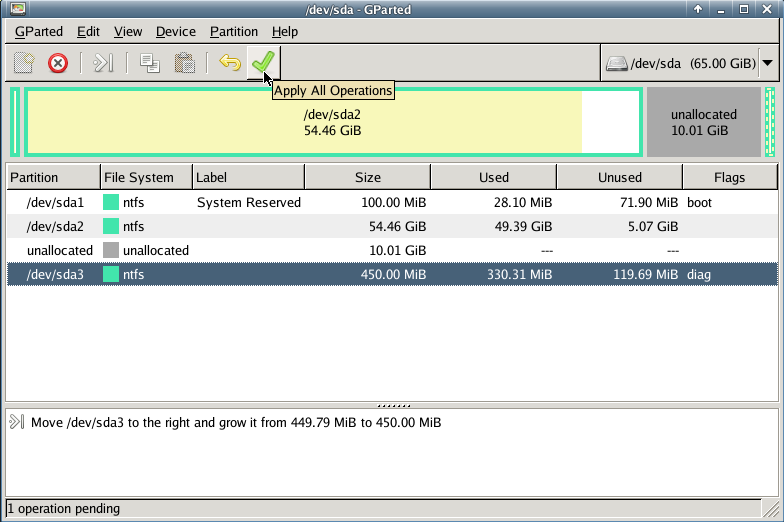
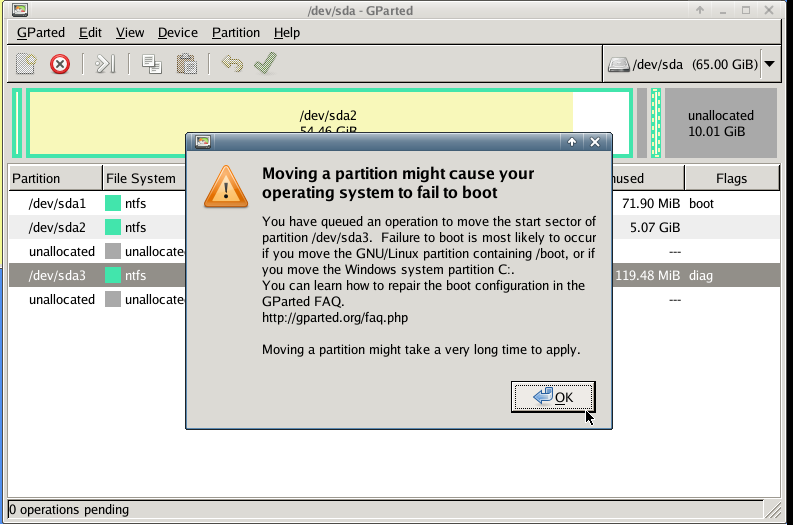
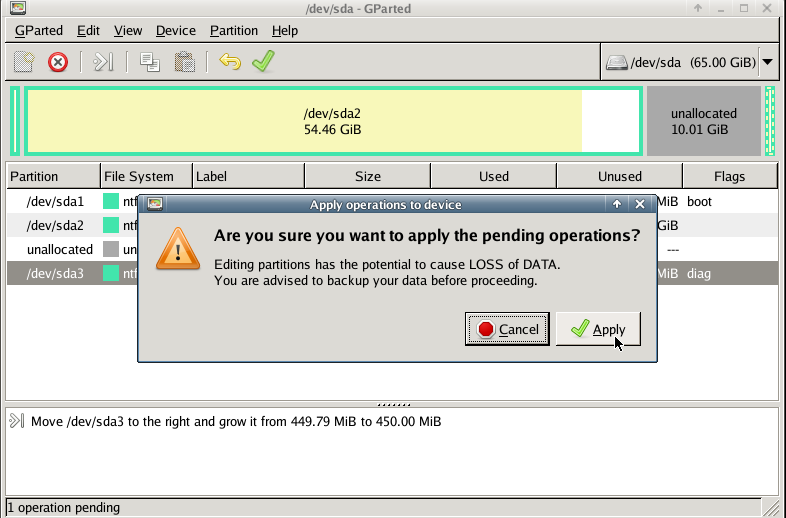
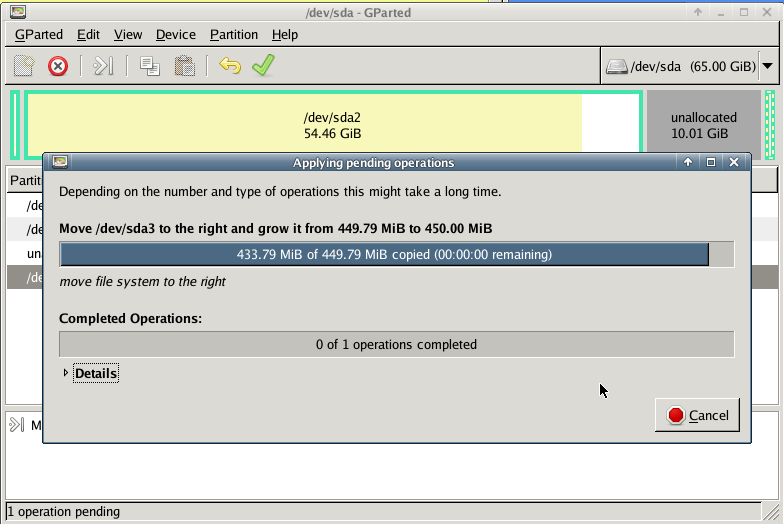
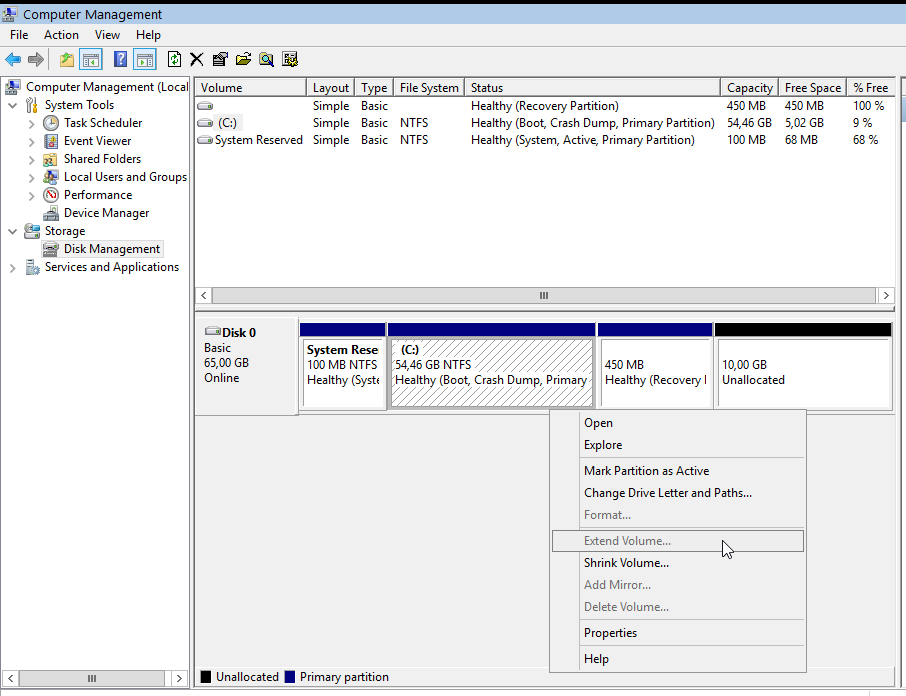
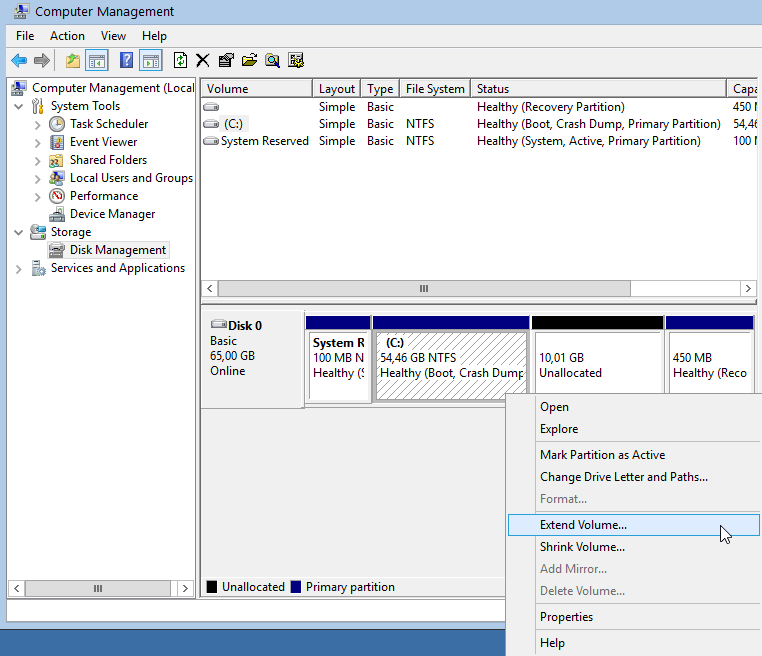
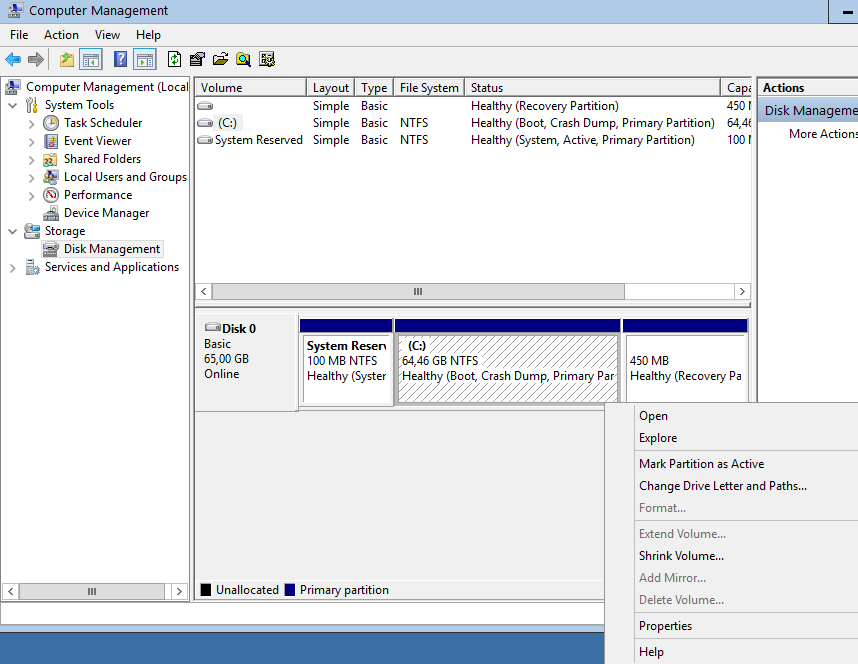
Computer Management - Disk Management
It’s time to extend our partition:
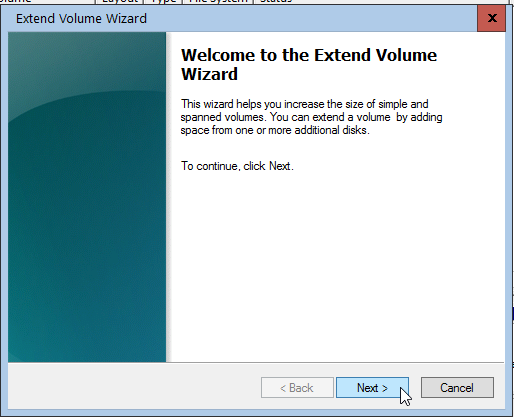
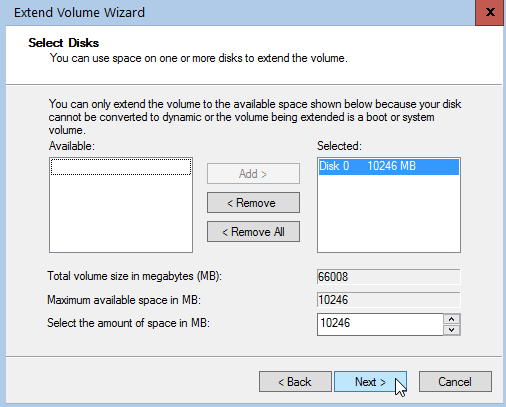
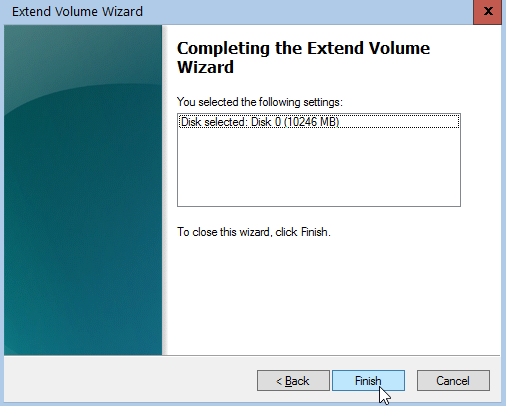
Finish
A Beginner’s Guide on How to use Thunderbird with Enigmail (Gpg4win) with their gmail account in 10 minutes on a windows machine
Thunderbird Enigmail - Gmail, Windows from vimeouser on Vimeo.
Linux Raid
This blog post is created as a mental note for future reference
Linux Raid is the de-facto way for decades in the linux-world on how to create and use a software raid. RAID stands for: Redundant Array of Independent Disks. Some people use the I for inexpensive disks, I guess that works too!
In simple terms, you can use a lot of hard disks to behave as one disk with special capabilities!
You can use your own inexpensive/independent hard disks as long as they have the same geometry and you can do almost everything. Also it’s pretty easy to learn and use linux raid. If you dont have the same geometry, then linux raid will use the smallest one from your disks. Modern methods, like LVM and BTRFS can provide an abstract layer with more capabilities to their users, but some times (or because something you have built a loooong time ago) you need to go back to basics.
And every time -EVERY time- I am searching online for all these cool commands that those cool kids are using. Cause what’s more exciting than replacing your -a decade ago- linux raid setup this typical Saturday night?
Identify your Hard Disks
% find /sys/devices/ -type f -name model -exec cat {} \;
ST1000DX001-1CM1
ST1000DX001-1CM1
ST1000DX001-1CM1
% lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 931.5G 0 disk
sdb 8:16 0 931.5G 0 disk
sdc 8:32 0 931.5G 0 disk
% lsblk -io KNAME,TYPE,SIZE,MODEL
KNAME TYPE SIZE MODEL
sda disk 931.5G ST1000DX001-1CM1
sdb disk 931.5G ST1000DX001-1CM1
sdc disk 931.5G ST1000DX001-1CM1
Create a RAID-5 with 3 Disks
Having 3 hard disks of 1T size, we are going to use the raid-5 Level . That means that we have 2T of disk usage and the third disk with keep the parity of the first two disks. Raid5 provides us with the benefit of loosing one hard disk without loosing any data from our hard disk scheme.

% mdadm -C -v /dev/md0 --level=5 --raid-devices=3 /dev/sda /dev/sdb /dev/sdc
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 512K
mdadm: sze set to 5238784K
mdadm: Defaulting to version 1.2 metadata
md/raid:md0 raid level 5 active with 2 our of 3 devices, algorithm 2
mdadm: array /dev/md0 started.
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0: active raid5 sdc[3] sdb[2] sda[1]
10477568 blocks super 1.2 level 5, 512k chink, algorith 2 [3/3] [UUU]
unused devices: <none>
running lsblk will show us our new scheme:
# lsblk -io KNAME,TYPE,SIZE,MODEL
KNAME TYPE SIZE MODEL
sda disk 931.5G ST1000DX001-1CM1
md0 raid5 1.8T
sdb disk 931.5G ST1000DX001-1CM1
md0 raid5 1.8T
sdc disk 931.5G ST1000DX001-1CM1
md0 raid5 1.8T
Save the Linux Raid configuration into a file
Software linux raid means that the raid configuration is actually ON the hard disks. You can take those 3 disks and put them to another linux box and everything will be there!! If you are keeping your operating system to another harddisk, you can also change your linux distro from one to another and your data will be on your linux raid5 and you can access them without any extra software from your new linux distro.
But it is a good idea to keep the basic conf to a specific configuration file, so if you have hardware problems your machine could understand what type of linux raid level you need to have on those broken disks!
% mdadm --detail --scan >> /etc/mdadm.conf
% cat /etc/mdadm.conf
ARRAY /dev/md0 metadata=1.2 name=MyServer:0 UUID=ef5da4df:3e53572e:c3fe1191:925b24cf
UUID - Universally Unique IDentifier
Be very careful that the above UUID is the UUID of the linux raid on your disks.
We have not yet created a filesystem over this new disk /dev/md0 and if you need to add this filesystem under your fstab file you can not use the UUID of the linux raid md0 disk.
Below there is an example on my system:
% blkid
/dev/sda: UUID="ef5da4df-3e53-572e-c3fe-1191925b24cf" UUID_SUB="f4e1da17-e4ff-74f0-b1cf-6ec86eca3df1" LABEL="MyServer:0" TYPE="linux_raid_member"
/dev/sdb: UUID="ef5da4df-3e53-572e-c3fe-1191925b24cf" UUID_SUB="ad7315e5-56ce-bd8c-75c5-0a72893a63db" LABEL="MyServer:0" TYPE="linux_raid_member"
/dev/sdc: UUID="ef5da4df-3e53-572e-c3fe-1191925b24cf" UUID_SUB="a90e317e-4384-8f30-0de1-ee77f8912610" LABEL="MyServer:0" TYPE="linux_raid_member"
/dev/md0: LABEL="data" UUID="48fc963a-2128-4d35-85fb-b79e2546dce7" TYPE="ext4"
% cat /etc/fstab
UUID=48fc963a-2128-4d35-85fb-b79e2546dce7 /backup auto defaults 0 0
Replacing a hard disk
Hard disks will fail you. This is a fact that every sysadmin knows from day one. Systems will fail at some point in the future. So be prepared and keep backups !!
Failing a disk
Now it’s time to fail (if not already) the disk we want to replace:
% mdadm --manage /dev/md0 --fail /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md0
Remove a broken disk
Here is a simple way to remove a broken disk from your linux raid configuration. Remember with raid5 level we can manage with 2 hard disks.
% mdadm --manage /dev/md0 --remove /dev/sdb
mdadm: hot removed /dev/sdb from /dev/md0
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
unused devices: <none>
dmesg shows:
% dmesg | tail
md: data-check of RAID array md0
md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for data-check.
md: using 128k window, over a total of 976631296k.
md: md0: data-check done.
md/raid:md0: Disk failure on sdb, disabling device.
md/raid:md0: Operation continuing on 2 devices.
RAID conf printout:
--- level:5 rd:3 wd:2
disk 0, o:0, dev:sda
disk 1, o:1, dev:sdb
disk 2, o:1, dev:sdc
RAID conf printout:
--- level:5 rd:3 wd:2
disk 0, o:0, dev:sda
disk 2, o:1, dev:sdc
md: unbind<sdb>
md: export_rdev(sdb)
Adding a new disk - replacing a broken one
Now it’s time to add a new and (if possible) clean hard disk. Just to be sure, I always wipe with dd the first few kilobytes of every disk with zeros.
Using mdadm to add this new disk:
# mdadm --manage /dev/md0 --add /dev/sdb
mdadm: added /dev/sdb
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb[4] sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[>....................] recovery = 0.2% (2753372/976631296) finish=189.9min speed=85436K/sec
unused devices: <none>
For a 1T Hard Disk is about 3h of recovering data. Keep that in mind on scheduling the maintenance window.
after a few minutes:
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb[4] sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[>....................] recovery = 4.8% (47825800/976631296) finish=158.3min speed=97781K/sec
unused devices: <none>
mdadm shows:
% mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Array Size : 1953262592 (1862.78 GiB 2000.14 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Mon Oct 17 21:52:05 2016
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Rebuild Status : 58% complete
Name : MyServer:0 (local to host MyServer)
UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Events : 554
Number Major Minor RaidDevice State
1 8 16 1 active sync /dev/sda
4 8 32 0 spare rebuilding /dev/sdb
3 8 48 2 active sync /dev/sdc
You can use watch command that refreshes every two seconds your terminal with the output :
# watch cat /proc/mdstat
Every 2.0s: cat /proc/mdstat Mon Oct 17 21:53:34 2016
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb[4] sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[===========>.........] recovery = 59.4% (580918844/976631296) finish=69.2min speed=95229K/sec
unused devices: <none>
Growing a Linux Raid
Even so … 2T is not a lot of disk usage these days! If you need to grow-extend your linux raid, then you need hard disks with the same geometry (or larger).
Steps on growing your linux raid are also simply:
# Umount the linux raid device:
% umount /dev/md0
# Add the new disk
% mdadm --add /dev/md0 /dev/sdd
# Check mdstat
% cat /proc/mdstat
# Grow linux raid by one device
% mdadm --grow /dev/md0 --raid-devices=4
# watch mdstat for reshaping to complete - also 3h+ something
% watch cat /proc/mdstat
# Filesystem check your linux raid device
% fsck -y /dev/md0
# Resize - Important
% resize2fs /dev/md0
But sometimes life happens …
Need 1 spare to avoid degraded array, and only have 0.
mdadm: Need 1 spare to avoid degraded array, and only have 0.
or
mdadm: Failed to initiate reshape!
Sometimes you get an error that informs you that you can not grow your linux raid device! It’s not time to panic or flee the scene. You’ve got this. You have already kept a recent backup before you started and you also reading this blog post!
You need a (an extra) backup-file !
% mdadm --grow --raid-devices=4 --backup-file=/tmp/backup.file /dev/md0
mdadm: Need to backup 3072K of critical section..
% cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sda[4] sdb[0] sdd[3] sdc[1]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[>....................] reshape = 0.0
% (66460/976631296) finish=1224.4min speed=13292K/sec
unused devices: <none>
1224.4min seems a lot !!!
dmesg shows:
% dmesg
[ 36.477638] md: Autodetecting RAID arrays.
[ 36.477649] md: Scanned 0 and added 0 devices.
[ 36.477654] md: autorun ...
[ 36.477658] md: ... autorun DONE.
[ 602.987144] md: bind<sda>
[ 603.219025] RAID conf printout:
[ 603.219036] --- level:5 rd:3 wd:3
[ 603.219044] disk 0, o:1, dev:sdb
[ 603.219050] disk 1, o:1, dev:sdc
[ 603.219055] disk 2, o:1, dev:sdd
[ 608.650884] RAID conf printout:
[ 608.650896] --- level:5 rd:3 wd:3
[ 608.650903] disk 0, o:1, dev:sdb
[ 608.650910] disk 1, o:1, dev:sdc
[ 608.650915] disk 2, o:1, dev:sdd
[ 684.308820] RAID conf printout:
[ 684.308832] --- level:5 rd:4 wd:4
[ 684.308840] disk 0, o:1, dev:sdb
[ 684.308846] disk 1, o:1, dev:sdc
[ 684.308851] disk 2, o:1, dev:sdd
[ 684.308855] disk 3, o:1, dev:sda
[ 684.309079] md: reshape of RAID array md0
[ 684.309089] md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
[ 684.309094] md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for reshape.
[ 684.309105] md: using 128k window, over a total of 976631296k.
mdstat
% cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sda[4] sdb[0] sdd[3] sdc[1]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[>....................] reshape = 0.0
% (349696/976631296) finish=697.9min speed=23313K/sec
unused devices: <none>ok it’s now 670minutes
Time to use watch:
(after a while)
% watch cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sda[4] sdb[0] sdd[3] sdc[1]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[===========>......] reshape = 66.1% (646514752/976631296) finish=157.4min speed=60171K/sec
unused devices: <none>
mdadm shows:
% mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 6 13:06:34 2014
Raid Level : raid5
Array Size : 1953262592 (1862.78 GiB 2000.14 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sat Oct 22 14:59:33 2016
State : clean, reshaping
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Reshape Status : 66% complete
Delta Devices : 1, (3->4)
Name : MyServer:0
UUID : d635095e:50457059:7e6ccdaf:7da91c9b
Events : 1536
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
3 8 48 2 active sync /dev/sdd
4 8 0 3 active sync /dev/sdabe patient and keep an aye on mdstat under proc.
So basically those are the steps, hopefuly you will find them useful.
# /bin/find /sys/devices -type f -name model -exec cat {} \;
KINGSTON SV300S3
WDC WD10EURX-63F
WDC WD10EZRX-00A
VB0250EAVER
VB0250EAVER
# udisksctl status
MODEL REVISION SERIAL DEVICE
--------------------------------------------------------------------------
KINGSTON SV300S37A120G 527ABBF0 50026B774902D7E5 sda
WDC WD10EURX-63FH1Y0 01.01A01 WD-WMC1U5525831 sdb
WDC WD10EZRX-00A8LB0 01.01A01 WD-WCC1U2715714 sdc
VB0250EAVER HPG9 Z3TLRVYK sdd
VB0250EAVER HPG9 Z3TLRRKM sde
# lsblk -io KNAME,TYPE,SIZE,MODEL
KNAME TYPE SIZE MODEL
sda disk 111,8G KINGSTON SV300S3
sdb disk 931,5G WDC WD10EURX-63F
sdc disk 931,5G WDC WD10EZRX-00A
sdd disk 232,9G VB0250EAVER
sde disk 232,9G VB0250EAVER
also
# smartctl -a -i /dev/sda
# hdparm -i /dev/sda
# lshw -class disk
# hwinfo --disk
Most people -reading this blog post- will scream in their chairs … PLZ keep in-mind that I am not a developer and perhaps the below workaround is just that, a workaround.
I have this case that I need to render (with JS) text that already has passed through the PHP parser.
The caveat is that the text output is inside a <DIV> element and has HTML code in it.
Most of you understand that HTML inside a DIV element is not something useful as the browser’s engine is rendering it to HTML on page load. That means, that we can not get the innerHTML of this DIV element, as it is already rendered by the browser.
Let me give you an example:
<div>
<!DOCTYPE html>
<html>
<body>
<p align="center">
<div> An Example </div>
</p>
</body>
</html>
</div>
If you open a test.html page with the above code, and fire up any browser, you will see only: An Example as the output of the above DIV. There is no way to get the HTML code from the above example.
You probably thinking that I need to edit the PHP parser. Actually this DIV element is been filled up with an Ajax request from the PHP API, so no luck on the server-side code.
After spending a brutal weekend with http://www.w3schools.com and reading through every stackoverflow question, nothing appeared to get me closer to my purpose.
I’ve tried jquery with .html(), .text(), getting the innerHTML, I’ve tried everything I could think of. The only way to get the HTML code from inside an HTML DOM element is if the HTML code was/is inside a TEXT element, somehow.
I needed to get a TEXT element instead of a DIV element, so that I could get the text value of the HTML element.
So here is my workaround:
I encapsulated a hidden textarea HTML element inside the DIV !
<div class="show_myclass">
<textarea class="myclass" style="display:none;">
<!DOCTYPE html>
<html>
<body>
<p align="center">
<div> An Example </div>
</p>
</body>
</html>
</ textarea>
</ div>
I can now, get the text value of the textarea and use it.
My JS code became something like this:
1. $(".myclass").each(function(i, block ) {
2. document.getElementsByClassName("show_myclass")[i].innerHTML = my_function_that_does_magic( block.value );
3. });
Let me explain a few things … for people that are nοt so much familiar with jquery or JS (like me).
Line 1: Α jquery selector by class, exactly like this getElementsByClassName() in HTML DOM but it is an iterator already with each function. For every element with classname = myclass do something. In a page with multiple DIVs-TextAreas this will be very useful.
Line 2: Get the TEXT value from the textarea ( block.value ) and run it as argument thought our magic function. Then populate the HTML result on the DIV element with the same iterator.
In conclusion, when the browser finally renders the whole page, the above javascript code will override the DIV element and will instead of -not- showing the hidden textarea, will show the output of our my_function_that_does_magic function !!!

I really like this comic.
I try to read/learn something every day.
Sometimes, when I find an interesting article, I like to mark it for reading it later.
I use many forms of marking, like pin tabs, bookmarking, sending url via email, save the html page to a folder, save it to my wallabag instance, leave my browser open to this tab, send the URL QR to my phone etc etc etc.
Are all the above ways productive?
None … the time to read something is now!
I mean the first time you lay your eyes upon the article.
Not later, not when you have free time, now.
That’s the way it works with me. Perhaps with you something else is more productive.
I have a short attention span and it is better for me to drop everything and read something carefully that save it for later or some other time.
When I really have to save it for later, my preferable way is to save it to my wallabag instance. It’s perfect and you will love it.
I also have a kobo ebook (e-ink) reader. Not the android based.
From my wallabag I can save them to epub and export them to my kobo.
But I am lazy and I never do it.
My kobo reader has a pocket (getpocket) account.
So I’ve tried to save some articles but not always pocket can parse properly the content of an article. Not even wallabag always work 100%.
The superiority of wallabag (and self-hosted application) is that when a parsing problem occurs I can fix them! Open a git push request and then EVERYBODY in the community will be able to read-this article from this content provider-later. I cant do something like that with pocket or readability.
And then … there are ads !!! Lots of ads, Tons of ads !!!
There is a correct way to do ads and this is when you are not covering the article you want people to read!
The are a lot of wrong ways to do ads: inline the text, above the article, hiding some of the content, make people buy a fee, provide an article to small pages (you know that height in HTML is not a problem, right?) and then there is bandwidth issues.
When I am on my mobile, I DONT want to pay extra for bandwidth I DIDNT ask and certainly do not care about it!!!
If I read the article on my tiny mobile display DO NOT COVER the article with huge ads that I can not find the X-close button because it doesnt fit to my display !!!
So yes, there is a correct way to do ads and that is by respecting the reader and there is a wrong way to do ads.
Getting back to the article’s subject, below you will see six (6) ways to read an article on my desktop. Of course there are hundreds ways but there are the most common ones:
Article: The cyberpunk dystopia we were warned about is already here
https://versions.killscreen.com/cyberpunk-dystopia-warned-already/
Extra info:
windows width: 852
2 times zoom-out to view more text
- Original Post in Firefox 48.0.1
- Wallabag
- Reader View in Firefox
- Chromium 52.0.2743.116
- Midori 0.5.11 - WebKitGTK+ 2.4.11
Click to zoom:
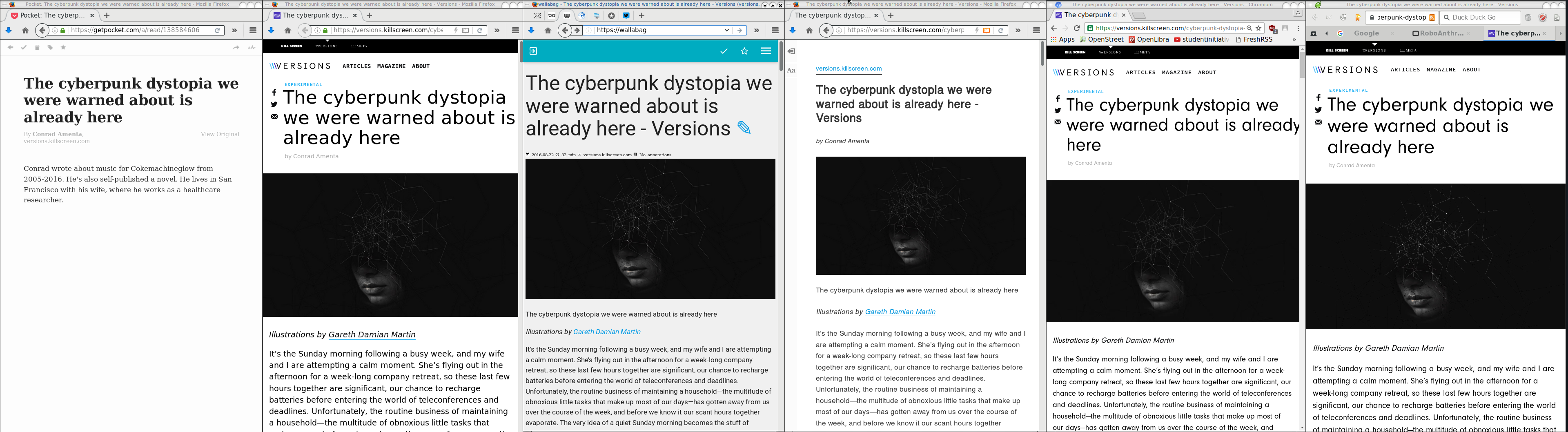
I believe that Reader View in Firefox is the winner of this test. It is clean and it is focusing on the actual article.
Impressive !
I have a compressed file of:
250.000.000 lines
Compressed the file size is: 671M
Uncompressed, it's: 6,5G
Need to extract a plethora of things and verify some others.
I dont want to use bash but something more elegant, like python or lua.
Looking through “The-Internet”, I’ve created some examples for the single purpose of educating my self.
So here are my results.
BE AWARE they are far-far-far away from perfect in code or execution.
Sorted by (less) time of execution:
pigz
# time pigz -p4 -cd 2016-08-04-06.ldif.gz &> /dev/null
real 0m9.980s
user 0m16.570s
sys 0m0.980s
gzip
gzip 1.8
# time /bin/gzip -cd 2016-08-04-06.ldif.gz &> /dev/null
real 0m23.951s
user 0m23.790s
sys 0m0.150s
zcat
zcat (gzip) 1.8
# time zcat 2016-08-04-06.ldif.gz &> /dev/null
real 0m24.202s
user 0m24.100s
sys 0m0.090s
Perl
Perl v5.24.0
code:
#!/usr/bin/perl
open (FILE, '/bin/gzip -cd 2016-08-04-06.ldif.gz |');
while (my $line = ) {
print $line;
}
close FILE;
time:
# time ./dump.pl &> /dev/null
real 0m49.942s
user 1m14.260s
sys 0m2.350s
PHP
PHP 7.0.9 (cli)
code:
#!/usr/bin/php
< ? php
$fp = gzopen("2016-08-04-06.ldif.gz", "r");
while (($buffer = fgets($fp, 4096)) !== false) {
echo $buffer;
}
gzclose($fp);
? >
time:
# time php -f dump.php &> /dev/null
real 1m19.407s
user 1m4.840s
sys 0m14.340s
PHP - Iteration #2
PHP 7.0.9 (cli)
Impressed with php results, I took the perl-approach on code:
< ? php
$fp = popen("/bin/gzip -cd 2016-08-04-06.ldif.gz", "r");
while (($buffer = fgets($fp, 4096)) !== false) {
echo $buffer;
}
pclose($fp);
? >
time:
# time php -f dump2.php &> /dev/null
real 1m6.845s
user 1m15.590s
sys 0m19.940s
not bad !
Lua
Lua 5.3.3
code:
#!/usr/bin/lua
local gzip = require 'gzip'
local filename = "2016-08-04-06.ldif.gz"
for l in gzip.lines(filename) do
print(l)
end
time:
# time ./dump.lua &> /dev/null
real 3m50.899s
user 3m35.080s
sys 0m15.780s
Lua - Iteration #2
Lua 5.3.3
I was depressed to see that php is faster than lua!!
Depressed I say !
So here is my next iteration on lua:
code:
#!/usr/bin/lua
local file = assert(io.popen('/bin/gzip -cd 2016-08-04-06.ldif.gz', 'r'))
while true do
line = file:read()
if line == nil then break end
print (line)
end
file:close()
time:
# time ./dump2.lua &> /dev/null
real 2m45.908s
user 2m54.470s
sys 0m21.360s
One minute faster than before, but still too slow !!
Lua - Zlib
Lua 5.3.3
My next iteration with lua is using zlib :
code:
#!/usr/bin/lua
local zlib = require 'zlib'
local filename = "2016-08-04-06.ldif.gz"
local block = 64
local d = zlib.inflate()
local file = assert(io.open(filename, "rb"))
while true do
bytes = file:read(block)
if not bytes then break end
print (d(bytes))
end
file:close()
time:
# time ./dump.lua &> /dev/null
real 0m41.546s
user 0m40.460s
sys 0m1.080s
Now, that's what I am talking about !!!
Playing with window_size (block) can make your code faster or slower.
Python v3
Python 3.5.2
code:
#!/usr/bin/python
import gzip
filename='2016-08-04-06.ldif.gz'
with gzip.open(filename, 'r') as f:
for line in f:
print(line,)
time:
# time ./dump.py &> /dev/null
real 13m14.460s
user 13m13.440s
sys 0m0.670s
Not enough tissues on the whole damn world!
Python v3 - Iteration #2
Python 3.5.2
but wait ... a moment ... The default mode for gzip.open is 'rb'.
(read binary)
let's try this once more with rt(read-text) mode:
code:
#!/usr/bin/python
import gzip
filename='2016-08-04-06.ldif.gz'
with gzip.open(filename, 'rt') as f:
for line in f:
print(line, end="")
time:
# time ./dump.py &> /dev/null
real 5m33.098s
user 5m32.610s
sys 0m0.410s
With only one super tiny change and run time in half!!!
But still tooo slow.
Python v3 - Iteration #3
Python 3.5.2
Let's try a third iteration with popen this time.
code:
#!/usr/bin/python
import os
cmd = "/bin/gzip -cd 2016-08-04-06.ldif.gz"
f = os.popen(cmd)
for line in f:
print(line, end="")
f.close()
time:
# time ./dump2.py &> /dev/null
real 6m45.646s
user 7m13.280s
sys 0m6.470s
Python v3 - zlib Iteration #1
Python 3.5.2
Let's try a zlib iteration this time.
code:
#!/usr/bin/python
import zlib
d = zlib.decompressobj(zlib.MAX_WBITS | 16)
filename='2016-08-04-06.ldif.gz'
with open(filename, 'rb') as f:
for line in f:
print(d.decompress(line))
time:
# time ./dump.zlib.py &> /dev/null
real 1m4.389s
user 1m3.440s
sys 0m0.410s
finally some proper values with python !!!
Specs
All the running tests occurred to this machine:
4 x Intel(R) Core(TM) i3-3220 CPU @ 3.30GHz
8G RAM
Conclusions
Ok, I Know !
The shell-pipe approach of using gzip for opening the compressed file, is not fair to all the above code snippets.
But ... who cares ?
I need something that run fast as hell and does smart things on those data.
Get in touch
As I am not a developer, I know that you people know how to do these things even better!
So I would love to hear any suggestions or even criticism on the above examples.
I will update/report everything that will pass the "I think I know what this code do" rule and ... be gently with me ;)
PLZ use my email address: evaggelos [ _at_ ] balaskas [ _dot_ ] gr
to send me any suggestions
Thanks !
[Last uptime 2020-12-25]
I need to run some ansible playbooks to a running (live) machine.
But, of-course, I cant use a production server for testing purposes !!
So here comes docker!
I have ssh access from my docker-server to this production server:
ssh livebox tar --one-file-system --sparse -C / -cf - | docker import - centos6:livebox on ubuntu 20.04
ssh livebox sudo tar -cf - --sparse --one-file-system / | docker import - centos6:livebox
Then run the new docker image:
$ docker run -t -i --rm -p 2222:22 centos6:livebox bash
[root@40b2bab2f306 /]# /usr/sbin/sshd -D
Create a new entry on your hosts inventory file, that uses ssh port 2222
or create a new separated inventory file
and test it with ansible ping module:
# ansible -m ping -i hosts.docker dockerlivebox
dockerlivebox | success >> {
"changed": false,
"ping": "pong"
}

Recently, I had the opportunity to see a presentation on the subject by Alexandros Kosiaris.
I was never fan of vagrant (or even virtualbox) but I gave it a try and below are my personal notes on the matter.
All my notes are based on Archlinux as it is my primary distribution but I think you can try them with every Gnu Linux OS.
Vagrant
So what is Vagrant ?
Vagrant is a wrapper, an abstraction layer to deal with some virtual solutions, like virtualbox, Vmware, hyper-v, docker, aws etc etc etc
With a few lines you can describe what you want to do and then use vagrant to create your enviroment of virtual boxes to work with.
Just for the fun of it, I used docker
Docker
We first need to create and build a proper Docker Image!
The Dockerfile below, is suggesting that we already have an archlinux:latest docker image.
You can use your own dockerfile or docker image.
You need to have an ssh connection to this docker image and you will need -of course- to have a ssh password or a ssh authorized key built in this image for root. If you are using sudo (then even better) dont forget to add the user to sudoers!
# vim Dockerfile
# sshd on archlinux
#
# VERSION 0.0.2
FROM archlinux:latest
MAINTAINER Evaggelos Balaskas < evaggelos _AT_ balaskas _DOT_ gr >
# Update the repositories
RUN pacman -Syy && pacman -S --noconfirm openssh python2
# Generate host keys
RUN /usr/bin/ssh-keygen -A
# Add password to root user
RUN echo 'root:roottoor' | chpasswd
# Fix sshd
RUN sed -i -e 's/^UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config && echo 'PermitRootLogin yes' >> /etc/ssh/sshd_config
# Expose tcp port
EXPOSE 22
# Run openssh daemon
CMD ["/usr/sbin/sshd", "-D"]
Again, you dont need to follow this step by the book!
It is an example to understand that you need a proper docker image that you can ssh into it.
Build the docker image:
# docker build -t archlinux:sshd .
On my PC:
# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
archlinux sshd 1b074ffe98be 7 days ago 636.2 MB
archlinux latest c0c56d24b865 7 days ago 534 MB
archlinux devel e66b5b8af509 2 weeks ago 607 MB
centos6 powerdns daf76074f848 3 months ago 893 MB
centos6 newdnsps 642462a8dfb4 3 months ago 546.6 MB
centos7 cloudstack b5e696e65c50 6 months ago 1.463 GB
centos7 latest d96affc2f996 6 months ago 500.2 MB
centos6 latest 4ba27f5a1189 6 months ago 489.8 MB
Environment
We can define docker as our default provider with:
# export VAGRANT_DEFAULT_PROVIDER=docker
It is not necessary to define the default provider, as you will see below,
but it is also a good idea - if your forget to declare your vagrant provider later
Before we start with vagrant, let us create a new folder:
# mkdir -pv vagrant
# cd vagrant
Initialization
We are ready to initialized our enviroment for vagrant:
# vagrant init
A `Vagrantfile` has been placed in this directory. You are now
ready to `vagrant up` your first virtual environment! Please read
the comments in the Vagrantfile as well as documentation on
`vagrantup.com` for more information on using Vagrant.
Initial Vagrantfile
A typical vagrant configuration file looks something like this:
# cat Vagrantfile
cat Vagrantfile
# -*- mode: ruby -*-
# vi: set ft=ruby :
# All Vagrant configuration is done below. The "2" in Vagrant.configure
# configures the configuration version (we support older styles for
# backwards compatibility). Please don't change it unless you know what
# you're doing.
Vagrant.configure("2") do |config|
# The most common configuration options are documented and commented below.
# For a complete reference, please see the online documentation at
# https://docs.vagrantup.com.
# Every Vagrant development environment requires a box. You can search for
# boxes at https://atlas.hashicorp.com/search.
config.vm.box = "base"
# Disable automatic box update checking. If you disable this, then
# boxes will only be checked for updates when the user runs
# `vagrant box outdated`. This is not recommended.
# config.vm.box_check_update = false
# Create a forwarded port mapping which allows access to a specific port
# within the machine from a port on the host machine. In the example below,
# accessing "localhost:8080" will access port 80 on the guest machine.
# config.vm.network "forwarded_port", guest: 80, host: 8080
# Create a private network, which allows host-only access to the machine
# using a specific IP.
# config.vm.network "private_network", ip: "192.168.33.10"
# Create a public network, which generally matched to bridged network.
# Bridged networks make the machine appear as another physical device on
# your network.
# config.vm.network "public_network"
# Share an additional folder to the guest VM. The first argument is
# the path on the host to the actual folder. The second argument is
# the path on the guest to mount the folder. And the optional third
# argument is a set of non-required options.
# config.vm.synced_folder "../data", "/vagrant_data"
# Provider-specific configuration so you can fine-tune various
# backing providers for Vagrant. These expose provider-specific options.
# Example for VirtualBox:
#
# config.vm.provider "virtualbox" do |vb|
# # Display the VirtualBox GUI when booting the machine
# vb.gui = true
#
# # Customize the amount of memory on the VM:
# vb.memory = "1024"
# end
#
# View the documentation for the provider you are using for more
# information on available options.
# Define a Vagrant Push strategy for pushing to Atlas. Other push strategies
# such as FTP and Heroku are also available. See the documentation at
# https://docs.vagrantup.com/v2/push/atlas.html for more information.
# config.push.define "atlas" do |push|
# push.app = "YOUR_ATLAS_USERNAME/YOUR_APPLICATION_NAME"
# end
# Enable provisioning with a shell script. Additional provisioners such as
# Puppet, Chef, Ansible, Salt, and Docker are also available. Please see the
# documentation for more information about their specific syntax and use.
# config.vm.provision "shell", inline: <<-SHELL
# apt-get update
# apt-get install -y apache2
# SHELL
end
If you try to run this Vagrant configuration file with docker provider,
it will try to boot up base image (Vagrant Default box):
# vagrant up --provider=docker
Bringing machine 'default' up with 'docker' provider...
==> default: Box 'base' could not be found. Attempting to find and install...
default: Box Provider: docker
default: Box Version: >= 0
==> default: Box file was not detected as metadata. Adding it directly...
==> default: Adding box 'base' (v0) for provider: docker
default: Downloading: base
An error occurred while downloading the remote file. The error
message, if any, is reproduced below. Please fix this error and try
again.
Couldn't open file /ebal/Desktop/vagrant/base
Vagrantfile
Put the initial vagrantfile aside and create the below Vagrant configuration file:
Vagrant.configure("2") do |config|
config.vm.provider "docker" do |d|
d.image = "archlinux:sshd"
end
end
That translate to :
Vagrant Provider: docker
Docker Image: archlinux:sshd
Basic commands
Run vagrant to create our virtual box:
# vagrant up
Bringing machine 'default' up with 'docker' provider...
==> default: Creating the container...
default: Name: vagrant_default_1466368592
default: Image: archlinux:sshd
default: Volume: /home/ebal/Desktop/vagrant:/vagrant
default:
default: Container created: 4cf4649b47615469
==> default: Starting container...
==> default: Provisioners will not be run since container doesn't support SSH.
ok, we havent yet configured vagrant to use ssh
but we have a running docker instance:
# vagrant status
Current machine states:
default running (docker)
The container is created and running. You can stop it using
`vagrant halt`, see logs with `vagrant docker-logs`, and
kill/destroy it with `vagrant destroy`.
that we can verify with docker ps:
# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4cf4649b4761 archlinux:sshd "/usr/sbin/sshd -D" About a minute ago Up About a minute 22/tcp vagrant_default_1466368592
Destroy
We need to destroy this instance:
# vagrant destroy
default: Are you sure you want to destroy the 'default' VM? [y/N] y
==> default: Stopping container...
==> default: Deleting the container...
Vagrant ssh
We need to edit Vagrantfile to add ssh support to our docker :
# vim Vagrantfile
Vagrant.configure("2") do |config|
config.vm.provider "docker" do |d|
d.image = "archlinux:sshd"
d.has_ssh = true
end
end
and re-up our vagrant box:
# vagrant up
Bringing machine 'default' up with 'docker' provider...
==> default: Creating the container...
default: Name: vagrant_default_1466368917
default: Image: archlinux:sshd
default: Volume: /home/ebal/Desktop/vagrant:/vagrant
default: Port: 127.0.0.1:2222:22
default:
default: Container created: b4fce563a9f9042c
==> default: Starting container...
==> default: Waiting for machine to boot. This may take a few minutes...
default: SSH address: 172.17.0.2:22
default: SSH username: vagrant
default: SSH auth method: private key
default: Warning: Authentication failure. Retrying...
default: Warning: Authentication failure. Retrying...
Vagrant will try to connect to our docker instance with the user: vagrant and a key.
But our docker image only have a root user and a root password !!
# vagrant status
Current machine states:
default running (docker)
The container is created and running. You can stop it using
`vagrant halt`, see logs with `vagrant docker-logs`, and
kill/destroy it with `vagrant destroy`.
# vagrant destroy
default: Are you sure you want to destroy the 'default' VM? [y/N] y
==> default: Stopping container...
==> default: Deleting the container...
Vagrant ssh - the Correct way !
We need to edit the Vagrantfile, properly:
# vim Vagrantfile
Vagrant.configure("2") do |config|
config.ssh.username = 'root'
config.ssh.password = 'roottoor'
config.vm.provider "docker" do |d|
d.image = "archlinux:sshd"
d.has_ssh = true
end
end
# vagrant up
Bringing machine 'default' up with 'docker' provider...
==> default: Creating the container...
default: Name: vagrant_default_1466369126
default: Image: archlinux:sshd
default: Volume: /home/ebal/Desktop/vagrant:/vagrant
default: Port: 127.0.0.1:2222:22
default:
default: Container created: 7fef0efc8905bb3a
==> default: Starting container...
==> default: Waiting for machine to boot. This may take a few minutes...
default: SSH address: 172.17.0.2:22
default: SSH username: root
default: SSH auth method: password
default: Warning: Connection refused. Retrying...
default:
default: Inserting generated public key within guest...
default: Removing insecure key from the guest if it's present...
default: Key inserted! Disconnecting and reconnecting using new SSH key...
==> default: Machine booted and ready!
# vagrant status
Current machine states:
default running (docker)
The container is created and running. You can stop it using
`vagrant halt`, see logs with `vagrant docker-logs`, and
kill/destroy it with `vagrant destroy`.
# vagrant ssh-config
Host default
HostName 172.17.0.2
User root
Port 22
UserKnownHostsFile /dev/null
StrictHostKeyChecking no
PasswordAuthentication no
IdentityFile /tmp/vagrant/.vagrant/machines/default/docker/private_key
IdentitiesOnly yes
LogLevel FATAL
# vagrant ssh
[root@7fef0efc8905 ~]# uptime
20:45:48 up 11:33, 0 users, load average: 0.53, 0.42, 0.28
[root@7fef0efc8905 ~]#
[root@7fef0efc8905 ~]#
[root@7fef0efc8905 ~]#
[root@7fef0efc8905 ~]# exit
logout
Connection to 172.17.0.2 closed.
Ansible
It is time to add ansible to the mix!
Ansible Playbook
We need to create a basic ansible playbook:
# cat playbook.yml
---
- hosts: all
vars:
ansible_python_interpreter: "/usr/bin/env python2"
gather_facts: no
tasks:
# Install package vim
- pacman: name=vim state=present
The above playbook, is going to install vim, via pacman (archlinux PACkage MANager)!
Archlinux comes by default with python3 and with ansible_python_interpreter you are declaring to use python2!
Vagrantfile with Ansible
# cat Vagrantfile
Vagrant.configure("2") do |config|
config.ssh.username = 'root'
config.ssh.password = 'roottoor'
config.vm.provider "docker" do |d|
d.image = "archlinux:sshd"
d.has_ssh = true
end
config.vm.provision "ansible" do |ansible|
ansible.verbose = "v"
ansible.playbook = "playbook.yml"
end
end
Vagrant Docker Ansible
# vagrant up
Bringing machine 'default' up with 'docker' provider...
==> default: Creating the container...
default: Name: vagrant_default_1466370194
default: Image: archlinux:sshd
default: Volume: /home/ebal/Desktop/vagrant:/vagrant
default: Port: 127.0.0.1:2222:22
default:
default: Container created: 8909eee7007b8d4f
==> default: Starting container...
==> default: Waiting for machine to boot. This may take a few minutes...
default: SSH address: 172.17.0.2:22
default: SSH username: root
default: SSH auth method: password
default: Warning: Connection refused. Retrying...
default:
default: Inserting generated public key within guest...
default: Removing insecure key from the guest if it's present...
default: Key inserted! Disconnecting and reconnecting using new SSH key...
==> default: Machine booted and ready!
==> default: Running provisioner: ansible...
default: Running ansible-playbook...
PYTHONUNBUFFERED=1 ANSIBLE_FORCE_COLOR=true ANSIBLE_HOST_KEY_CHECKING=false ANSIBLE_SSH_ARGS='-o UserKnownHostsFile=/dev/null -o IdentitiesOnly=yes -o ControlMaster=auto -o ControlPersist=60s' ansible-playbook --connection=ssh --timeout=30 --limit="default" --inventory-file=/mnt/VB0250EAVER/home/ebal/Desktop/vagrant/.vagrant/provisioners/ansible/inventory -v playbook.yml
Using /etc/ansible/ansible.cfg as config file
PLAY [all] *********************************************************************
TASK [pacman] ******************************************************************
changed: [default] => {"changed": true, "msg": "installed 1 package(s). "}
PLAY RECAP *********************************************************************
default : ok=1 changed=1 unreachable=0 failed=0
# vagrant status
Current machine states:
default running (docker)
The container is created and running. You can stop it using
`vagrant halt`, see logs with `vagrant docker-logs`, and
kill/destroy it with `vagrant destroy`.
# vagrant ssh
[root@8909eee7007b ~]# vim --version
VIM - Vi IMproved 7.4 (2013 Aug 10, compiled Jun 9 2016 09:35:16)
Included patches: 1-1910
Compiled by Arch Linux
Vagrant Provisioning
The ansible-step is called: provisioning as you may already noticed.
If you make a few changes on this playbook, just type:
# vagrant provision
and it will re-run the ansible part on this vagrant box !
Personal Notes on this blog post.
[work in progress]
Why ?
Γιατί docker ?
To docker είναι ένα management εργαλείο για διαχείριση containers.
Εάν κι αρχικά βασίστηκε σε lxc, πλέον είναι αυτοτελές.
Containers είναι ένα isolated περιβάλλον, κάτι περισσότερο από
chroot(jail) κάτι λιγότερο από virtual machines.
Μπορούμε να σηκώσουμε αρκετά linux λειτουργικά, αλλά της ίδιας αρχιτεκτονικής.
Χρησιμοποιούνται κυρίως για development αλλά πλέον τρέχει μεγάλη
production υποδομή σε μεγάλα projects.
Κερδίζει γιατί το docker image που έχω στο PC μου, μπορεί να τρέξει αυτούσιο
σε οποιοδήποτε linux λειτουργικό (centos/fedora/debian/archlinux/whatever)
και προσφέρει isolation μεταξύ της εφαρμογής που τρέχει και του λειτουργικού.
Οι επιδόσεις -πλέον- είναι πολύ κοντά σε αυτές του συστήματος.
Σε production κυρίως χρησιμοποιείτε για continuous deployment,
καθώς τα images μπορεί να τα παράγουν developers, vendors ή whatever,
και θα παίξει σε commodity server με οποιοδήποτε λειτουργικό σύστημα!
Οπότε πλέον το “Σε εμένα παίζει” με το docker μεταφράζεται σε
“Και σε εμένα παίζει” !! στην παραγωγή.
Info
Εάν δεν τρέχει το docker:
# systemctl restart docker
basic info on CentOS7 με devicemapper
# docker info
Containers: 0
Images: 4
Server Version: 1.9.1
Storage Driver: devicemapper
Pool Name: docker-8:1-10617750-pool
Pool Blocksize: 65.54 kB
Base Device Size: 107.4 GB
Backing Filesystem:
Data file: /dev/loop0
Metadata file: /dev/loop1
Data Space Used: 1.654 GB
Data Space Total: 107.4 GB
Data Space Available: 105.7 GB
Metadata Space Used: 1.642 MB
Metadata Space Total: 2.147 GB
Metadata Space Available: 2.146 GB
Udev Sync Supported: true
Deferred Removal Enabled: false
Deferred Deletion Enabled: false
Deferred Deleted Device Count: 0
Data loop file: /var/lib/docker/devicemapper/devicemapper/data
Metadata loop file: /var/lib/docker/devicemapper/devicemapper/metadata
Library Version: 1.02.107-RHEL7 (2015-12-01)
Execution Driver: native-0.2
Logging Driver: json-file
Kernel Version: 3.10.0-327.13.1.el7.x86_64
Operating System: CentOS Linux 7 (Core)
CPUs: 16
Total Memory: 15.66 GiB
Name: myserverpc
ID: DCO7:RO56:3EWH:ESM3:257C:TCA3:JPLD:QFLU:EHKL:QXKU:GJYI:SHY5
basic info σε archlinux με btrfs :
# docker info
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 8
Server Version: 1.11.1
Storage Driver: btrfs
Build Version: Btrfs v4.5.1
Library Version: 101
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: null host bridge
Kernel Version: 4.4.11-1-lts
Operating System: Arch Linux
OSType: linux
Architecture: x86_64
CPUs: 4
Total Memory: 7.68 GiB
Name: myhomepc
ID: MSCX:LLTD:YKZS:E7UN:NIA4:QW3F:SRGC:RQTH:RKE2:26VS:GFB5:Y7CS
Docker Root Dir: /var/lib/docker/
Debug mode (client): false
Debug mode (server): false
Registry: https://index.docker.io/v1/
Images
# docker images -a
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
centos6 rpmbuild ccb144691075 11 days ago 1.092 GB
< none > < none > 6d8ff86f2749 11 days ago 1.092 GB
< none > < none > af92904a92b4 11 days ago 811.8 MB
< none > < none > 8e429b38312b 11 days ago 392.7 MB
Τα none:none είναι built parent images που χρησιμοποιούνται από τα named docker images
αλλά δεν τα αποθηκεύσαμε σωστά.
Understanding Images
Ανάλογα με το back-end του docker, το docker κρατά σε delta-layers τις διαφορές
ανάμεσα στα parent/child docker images.
Αυτό μας διευκολύνει, γιατί μπορούμε στο production να έχουμε μεγάλες μήτρες από docker images
και να στέλνουμε μικρά delta-child docker images με το production service που θέλουμε να τρέξουμε.
Επίσης βοηθά και στο update.
Σε έξι μήνες, από την αρχική μας εικόνα, φτιάχνουμε το update image και πάνω σε αυτό
ξαναφορτώνουμε την εφαρμογή ή service που θέλουμε να τρέξει.
Έτσι μπορούμε να στέλνουμε μικρά σε μέγεθος docker images και να γίνονται build
τα διάφορα services μας πάνω σε αυτά.
Στο myserverpc μέσω του docker info είδαμε πως τρέχει σε:
Storage Driver: devicemapper
και χρησιμοποιεί το παρακάτω αρχείο για να κρατά τα images :
Data loop file: /var/lib/docker/devicemapper/devicemapper/data
Το οποίο στην πραγματικότητα είναι:
# file data
data: SGI XFS filesystem data (blksz 4096, inosz 256, v2 dirs)
Τα πιο δημοφιλή storage drivers είναι τα UFS & btrfs.
Προσωπικά (ebal) χρησιμοποιώ btrfs γιατί χρησιμοποιεί subvolumes
(σαν να λέμε ξεχωριστά cow volumes) για κάθε docker image
(parent ή child).
# ls /var/lib/docker/btrfs/subvolumes
070dd70b48c86828463a7341609a7ee4924decd4d7fdd527e9fbaa70f7a0caf8
1fb7e53272a8f01801d9e413c823cbb8cbc83bfe1218436bdb9e658ea2e8b755
632cceadcc05f28dda37b39b8a9111bb004a9bdaeca59c0300196863ee44ad0a
8bfbbf03c00863bc19f46aa994d1458c0b5454529ad6af1203fb6e2599a35e91
93bb08f5730368de14719109142232249dc6b3a0571a0157b2a043d7fc94117a
a174a1b850ae50dfaf1c13ede7fe37cc0cb574498a2faa4b0e80a49194d0e115
d0e92b9a33b207c679e8a05da56ef3bf9a750bddb124955291967e0af33336fc
e9904ddda15030a210c7d741701cca55a44b89fd320e2253cfcb6e4a3f905669
Processes
Τι docker process τρέχουν:
# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ενώ όταν τρέχει κάποιο:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
62ef0ed8bc95 centos6:rpmbuild "bash" 10 seconds ago Up 9 seconds drunk_mietner
Δώστε σημασία στο NAMES
To docker δίνει randomly δύο ονόματα για ευκολότερη διαχείριση,
αλλιώς θα πρέπει να χρησιμοποιούμε το πλήρες hashed named.
Στο παραπάνω παράδειγμα:
62ef0ed8bc952d501f241dbc4ecda25d3a629880d27fbb7344b5429a44af985f
Inspect
Πως παίρνουμε πληροφορίες από ένα docker process:
# docker inspect drunk_mietner
[
{
"Id": "62ef0ed8bc952d501f241dbc4ecda25d3a629880d27fbb7344b5429a44af985f",
"Created": "2016-06-05T07:41:18.821123985Z",
"Path": "bash",
"Args": [],
"State": {
"Status": "running",
"Running": true,
"Paused": false,
"Restarting": false,
"OOMKilled": false,
"Dead": false,
"Pid": 23664,
"ExitCode": 0,
"Error": "",
"StartedAt": "2016-06-05T07:41:19.558616976Z",
"FinishedAt": "0001-01-01T00:00:00Z"
},
"Image": "ccb1446910754d6572976a6d36e5d0c8d1d029e4dc72133211670b28cf2f1d8f",
"ResolvConfPath": "/var/lib/docker/containers/62ef0ed8bc952d501f241dbc4ecda25d3a629880d27fbb7344b5429a44af985f/resolv.conf",
"HostnamePath": "/var/lib/docker/containers/62ef0ed8bc952d501f241dbc4ecda25d3a629880d27fbb7344b5429a44af985f/hostname",
"HostsPath": "/var/lib/docker/containers/62ef0ed8bc952d501f241dbc4ecda25d3a629880d27fbb7344b5429a44af985f/hosts",
"LogPath": "/var/lib/docker/containers/62ef0ed8bc952d501f241dbc4ecda25d3a629880d27fbb7344b5429a44af985f/62ef0ed8bc952d501f241dbc4ecda25d3a629880d27fbb7344b5429a44af985f-json.log",
"Name": "/drunk_mietner",
"RestartCount": 0,
"Driver": "devicemapper",
"ExecDriver": "native-0.2",
"MountLabel": "system_u:object_r:svirt_sandbox_file_t:s0:c344,c750",
"ProcessLabel": "system_u:system_r:svirt_lxc_net_t:s0:c344,c750",
"AppArmorProfile": "",
"ExecIDs": null,
"HostConfig": {
"Binds": null,
"ContainerIDFile": "",
"LxcConf": [],
"Memory": 0,
"MemoryReservation": 0,
"MemorySwap": 0,
"KernelMemory": 0,
"CpuShares": 0,
"CpuPeriod": 0,
"CpusetCpus": "",
"CpusetMems": "",
"CpuQuota": 0,
"BlkioWeight": 0,
"OomKillDisable": false,
"MemorySwappiness": -1,
"Privileged": false,
"PortBindings": {},
"Links": null,
"PublishAllPorts": false,
"Dns": [],
"DnsOptions": [],
"DnsSearch": [],
"ExtraHosts": null,
"VolumesFrom": null,
"Devices": [],
"NetworkMode": "default",
"IpcMode": "",
"PidMode": "",
"UTSMode": "",
"CapAdd": null,
"CapDrop": null,
"GroupAdd": null,
"RestartPolicy": {
"Name": "no",
"MaximumRetryCount": 0
},
"SecurityOpt": null,
"ReadonlyRootfs": false,
"Ulimits": null,
"Sysctls": {},
"LogConfig": {
"Type": "json-file",
"Config": {}
},
"CgroupParent": "",
"ConsoleSize": [
0,
0
],
"VolumeDriver": "",
"ShmSize": 67108864
},
"GraphDriver": {
"Name": "devicemapper",
"Data": {
"DeviceId": "13",
"DeviceName": "docker-8:1-10617750-62ef0ed8bc952d501f241dbc4ecda25d3a629880d27fbb7344b5429a44af985f",
"DeviceSize": "107374182400"
}
},
"Mounts": [],
"Config": {
"Hostname": "62ef0ed8bc95",
"Domainname": "",
"User": "",
"AttachStdin": true,
"AttachStdout": true,
"AttachStderr": true,
"Tty": true,
"OpenStdin": true,
"StdinOnce": true,
"Env": null,
"Cmd": [
"bash"
],
"Image": "centos6:rpmbuild",
"Volumes": null,
"WorkingDir": "",
"Entrypoint": null,
"OnBuild": null,
"Labels": {},
"StopSignal": "SIGTERM"
},
"NetworkSettings": {
"Bridge": "",
"SandboxID": "992cf9db43c309484b8261904f46915a15eff3190026749841b93072847a14bc",
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"Ports": {},
"SandboxKey": "/var/run/docker/netns/992cf9db43c3",
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "17b09b362d3b2be7d9c48377969049ac07cb821c482a9644970567fd5bb772f1",
"Gateway": "172.17.0.1",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"MacAddress": "02:42:ac:11:00:02",
"Networks": {
"bridge": {
"EndpointID": "17b09b362d3b2be7d9c48377969049ac07cb821c482a9644970567fd5bb772f1",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:02"
}
}
}
}
]
output σε json, που σημαίνει εύκολο provisioning !!!
Import
Ο πιο εύκολος τρόπος είναι να έχουμε ένα tar archive
από το σύστημα που θέλουμε και να το κάνουμε import:
# docker import - centos6:latest < a.tar
Run
Πως σηκώνουμε ένα docker image:
# docker run -t -i --rm centos6:latest bash
Αυτό σημαίνει πως θα μας δώσει interactive process με entry-point το bash.
Τέλος, μόλις κλείσουμε το docker image θα εξαφανιστούν ΟΛΕΣ οι αλλαγές που έχουμε κάνει.
Χρειάζεται να τα διαγράφουμε, για να μην γεμίσουμε με images που έχουν μεταξύ τους μικρές αλλαγές
Μπορούμε να έχουμε docker processes χωρίς entry-point.
Αυτά είναι τα service oriented containers που το entry-point
είναι TCP port (συνήθως) και τρέχουν τα διάφορα services που θέλουμε.
Όλα αυτά αργότερα.
Inside
Μέσα σε ένα docker image:
[root@62ef0ed8bc95 /]# hostname
62ef0ed8bc95
# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
11: eth0@if12: mtu 1500 qdisc noqueue state UP
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe11:2/64 scope link
valid_lft forever preferred_lft forever
# ip r
default via 172.17.0.1 dev eth0
172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.2
private network 172.x.x.x
το οποίο έχει δημιουργηθεί από το myserverpc:
10: docker0: mtu 1500 qdisc noqueue state UP
link/ether 02:42:24:5c:42:f6 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:24ff:fe5c:42f6/64 scope link
valid_lft forever preferred_lft forever
12: veth524ea1d@if11: mtu 1500 qdisc noqueue master docker0 state UP
link/ether 6e:39:ae:aa:ec:65 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet6 fe80::6c39:aeff:feaa:ec65/64 scope link
valid_lft forever preferred_lft forever
# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.0242245c42f6 no veth524ea1d
virbr0 8000.525400990c9d yes virbr0-nic
Commit
ok, έχουμε κάνει τις αλλαγές μας ή έχουμε στήσει μια μήτρα ενός docker image
που θέλουμε να κρατήσουμε. Πως το κάνουμε commit ?
Από το myserverpc (κι όχι μέσα από το docker process):
# docker commit -p -m "centos6 rpmbuild test image" drunk_mietner centos6:rpmbuildtest
Το βλέπουμε πως έχει δημιουργηθεί:
# docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
centos6 rpmbuildtest 95246c3b7b8b 3 seconds ago 1.092 GB
centos6 rpmbuild ccb144691075 11 days ago 1.092 GB
Remove
και δεν το χρειαζόμαστε πλέον, θέλουμε να κρατήσουμε μόνο το centos6:rpmbuild
Εάν δεν έχει child docker images και δεν τρέχει κάποιο docker process βασισμένο σε αυτό το docker:
# docker rmi centos6:rpmbuildtest
Untagged: centos6:rpmbuildtest
Deleted: 95246c3b7b8b77e9f5c70f2fd7b8ea2c8ec1f72e846897c87cd60722f6caabef
# docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
centos6 rpmbuild ccb144691075 11 days ago 1.092 GB
< none > < none > 6d8ff86f2749 11 days ago 1.092 GB
Export
οκ, έχουμε φτιάξει στον υπολογιστή μας το τέλειο docker image
και θέλουμε να το κάνουμε export για να το φορτώσουμε κάπου αλλού:
# docker export drunk_mietner > CentOS68_rpmbuild.tar
These are my personal notes on upgrading wallabag to it’s latest version (2.0.8):
Create a backup
# cd /var/www/html/
# mv wallabag wallabag_bak
Download latest version
# wget -c http://wllbg.org/latest-v2-package -qO - | tar -xz
# mv release-2.0.8 wallabag
Restore Settings
# cp -f wallabag_bak/app/config/parameters.yml wallabag/app/config/parameters.yml
# rsync -r wallabag_bak/data/ wallabag/data/
[h3] Permissions [h3]
Don’t forget to fix the permissions on wallabag according to your web server settings:
# chown -R apache:apache wallabag
and …. that’s it !
Let’s Encrypt client: certbot is been written in python and as it’s predecessor needs at least Python 2.7.
But (still) in CentOS series 6 (currently 6.8) there is no natively support for python27.
So I did this thing below, quick & dirty:
# cd /usr/local/src/
# wget -c https://www.python.org/ftp/python/2.7.11/Python-2.7.11.tgz
# tar xf Python-2.7.11.tgz
# cd Python-2.7.11
# ./configure
# make
# make install
and these are my notes for renew certificates :
# ln -s /opt/Python-2.7/bin/python2.7 /usr/local/bin/python2
[root@1 certbot]# source venv/bin/activate
(venv)[root@1 certbot]#
# cd venv/bin/
# ./certbot renew --dry-run
# ./certbot renew
# rm /usr/local/bin/python2
Domain-based Message Authentication, Reporting and Conformance
What is dmarc in a nutshell:
An authentication Protocol that combines SPF & DKIM to reduce spoofed emails.
Depends on DNS so DANE would be great here!
notes on centos6:
You need to already have implemented SPF & DKIM
Outgoing Mail Servers
DNS
in your zone file, add something like this:
_dmarc IN TXT "v=DMARC1; p=none; rua=mailto:postmaster@example.org"
increase the serial number of the zone and check it:
# dig +short txt _dmarc.example.org
"v=DMARC1; p=none; rua=mailto:postmaster@example.org"
dmarc tags
DMARC requires only two tags.
v: version
p: policy
version
Version is DMARC1 for the time being
policy
p=none
p=quarantine
p=reject
We start from policy=none and trying to investigate mail logs
reports
rua declares where the mail servers will send the reports regarding dmarc failures.
Incoming Mail Servers
installation
# yum search opendmarc
# yum -y install opendmarc.x86_64
check process:
# netstat -ntlp|grep dmarc
tcp 0 0 127.0.0.1:8893 0.0.0.0:* LISTEN 14538/opendmarc
postfix
Add another milter:
# opendkim & opendmarc
non_smtpd_milters=inet:127.0.0.1:8891,inet:127.0.0.1:8893
smtpd_milters=inet:127.0.0.1:8891,inet:127.0.0.1:8893
configuration
# grep -Ev '#|^$' /etc/opendmarc.conf
Socket inet:8893@localhost
SoftwareHeader true
SPFIgnoreResults true
SPFSelfValidate true
Syslog true
UMask 007
UserID opendmarc:mail
AuthservID example.org
MilterDebug 1
service
# /etc/init.d/opendmarc restart
# chkconfig opendmarc on
DMARC Inspector
The last couple months, I get over 400 unknown user errors on my imap (dovecot) server.
FYI this is the report:
dovecot: auth: ldap(aaaaaa,193.189.117.147): unknown user:
dovecot: auth: ldap(accountant,193.189.117.147): unknown user:
dovecot: auth: ldap(acosta,193.189.117.147): unknown user:
dovecot: auth: ldap(admin@balaskas.gr,89.248.162.175): unknown user:
dovecot: auth: ldap(adrian,193.189.117.152): unknown user:
dovecot: auth: ldap(alarm,193.189.117.152): unknown user:
dovecot: auth: ldap(alcala,185.125.4.192): unknown user:
dovecot: auth: ldap(alena,193.189.117.148): unknown user:
dovecot: auth: ldap(alfaro,185.125.4.192): unknown user:
dovecot: auth: ldap(alias,193.189.117.152): unknown user:
dovecot: auth: ldap(ally,185.125.4.192): unknown user:
dovecot: auth: ldap(almeida,185.125.4.192): unknown user:
dovecot: auth: ldap(alya,185.125.4.192): unknown user:
dovecot: auth: ldap(amara,185.125.4.192): unknown user:
dovecot: auth: ldap(amigo,185.125.4.192): unknown user:
dovecot: auth: ldap(amina,185.125.4.192): unknown user:
dovecot: auth: ldap(amity,185.125.4.192): unknown user:
dovecot: auth: ldap(analysis,185.125.4.192): unknown user:
dovecot: auth: ldap(analyst,185.125.4.192): unknown user:
dovecot: auth: ldap(anderson,185.125.4.192): unknown user:
dovecot: auth: ldap(andrade,185.125.4.192): unknown user:
dovecot: auth: ldap(andreea,185.125.4.192): unknown user:
dovecot: auth: ldap(andria,185.125.4.192): unknown user:
dovecot: auth: ldap(annalisa,185.125.4.192): unknown user:
dovecot: auth: ldap(annika,193.189.117.148): unknown user:
dovecot: auth: ldap(anon,185.125.4.192): unknown user:
dovecot: auth: ldap(anonymous,193.189.117.148): unknown user:
dovecot: auth: ldap(area,185.125.4.192): unknown user:
dovecot: auth: ldap(aris,185.125.4.192): unknown user:
dovecot: auth: ldap(arriaga,185.125.4.192): unknown user:
dovecot: auth: ldap(ashley,185.125.4.192): unknown user:
dovecot: auth: ldap(assistance,185.125.4.192): unknown user:
dovecot: auth: ldap(aya,185.125.4.192): unknown user:
dovecot: auth: ldap(azerty,185.125.4.192): unknown user:
dovecot: auth: ldap(baby,185.125.4.192): unknown user:
dovecot: auth: ldap(bad,185.125.4.192): unknown user:
dovecot: auth: ldap(ballesteros,185.125.4.192): unknown user:
dovecot: auth: ldap(banana,193.189.117.147): unknown user:
dovecot: auth: ldap(band,185.125.4.192): unknown user:
dovecot: auth: ldap(bank,193.189.117.149): unknown user:
dovecot: auth: ldap(barbara,193.189.117.147): unknown user:
dovecot: auth: ldap(barcode,193.189.117.147): unknown user:
dovecot: auth: ldap(barney,185.125.4.192): unknown user:
dovecot: auth: ldap(barrie,185.125.4.192): unknown user:
dovecot: auth: ldap(basil,185.125.4.192): unknown user:
dovecot: auth: ldap(bob,193.189.117.148): unknown user:
dovecot: auth: ldap(camp,155.133.82.65): unknown user:
dovecot: auth: ldap(campos,155.133.82.65): unknown user:
dovecot: auth: ldap(candi,155.133.82.65): unknown user:
dovecot: auth: ldap(carlo,193.189.117.147): unknown user:
dovecot: auth: ldap(carolina,193.189.117.147): unknown user:
dovecot: auth: ldap(cashier,193.189.117.148): unknown user:
dovecot: auth: ldap(casper,155.133.82.65): unknown user:
dovecot: auth: ldap(chad,155.133.82.65): unknown user:
dovecot: auth: ldap(challenge,155.133.82.65): unknown user:
dovecot: auth: ldap(chantal,155.133.82.65): unknown user:
dovecot: auth: ldap(charly,155.133.82.65): unknown user:
dovecot: auth: ldap(cher,155.133.82.65): unknown user:
dovecot: auth: ldap(cheryl,155.133.82.65): unknown user:
dovecot: auth: ldap(clare,155.133.82.65): unknown user:
dovecot: auth: ldap(classic,155.133.82.65): unknown user:
dovecot: auth: ldap(claudia,193.189.117.149): unknown user:
dovecot: auth: ldap(clock,155.133.82.65): unknown user:
dovecot: auth: ldap(consola,155.133.82.65): unknown user:
dovecot: auth: ldap(contactus,193.189.117.149): unknown user:
dovecot: auth: ldap(contract,155.133.82.65): unknown user:
dovecot: auth: ldap(craig,155.133.82.65): unknown user:
dovecot: auth: ldap(cuenta,155.133.82.65): unknown user:
dovecot: auth: ldap(cuentas,155.133.82.65): unknown user:
dovecot: auth: ldap(culture,155.133.82.65): unknown user:
dovecot: auth: ldap(dale,155.133.82.65): unknown user:
dovecot: auth: ldap(danielle,193.189.117.149): unknown user:
dovecot: auth: ldap(dante,155.133.82.65): unknown user:
dovecot: auth: ldap(davis,155.133.82.65): unknown user:
dovecot: auth: ldap(day,155.133.82.65): unknown user:
dovecot: auth: ldap(denis,193.189.117.149): unknown user:
dovecot: auth: ldap(dentrix,185.125.4.194): unknown user:
dovecot: auth: ldap(deposit,185.125.4.194): unknown user:
dovecot: auth: ldap(designer,185.125.4.194): unknown user:
dovecot: auth: ldap(desmond,155.133.82.65): unknown user:
dovecot: auth: ldap(devel,185.125.4.194): unknown user:
dovecot: auth: ldap(device,185.125.4.194): unknown user:
dovecot: auth: ldap(devin,185.125.4.194): unknown user:
dovecot: auth: ldap(diamante,185.125.4.194): unknown user:
dovecot: auth: ldap(digital,193.189.117.151): unknown user:
dovecot: auth: ldap(dimas,155.133.82.65): unknown user:
dovecot: auth: ldap(direktor,155.133.82.65): unknown user:
dovecot: auth: ldap(discount,185.125.4.194): unknown user:
dovecot: auth: ldap(discussion,185.125.4.194): unknown user:
dovecot: auth: ldap(disk,155.133.82.65): unknown user:
dovecot: auth: ldap(display,193.189.117.149): unknown user:
dovecot: auth: ldap(doctor,193.189.117.148): unknown user:
dovecot: auth: ldap(document,193.189.117.148): unknown user:
dovecot: auth: ldap(dolores,185.125.4.194): unknown user:
dovecot: auth: ldap(domingo,185.125.4.194): unknown user:
dovecot: auth: ldap(dominio,185.125.4.194): unknown user:
dovecot: auth: ldap(donald,185.125.4.194): unknown user:
dovecot: auth: ldap(donna,193.189.117.149): unknown user:
dovecot: auth: ldap(dorado,185.125.4.194): unknown user:
dovecot: auth: ldap(doreen,155.133.82.65): unknown user:
dovecot: auth: ldap(doris,155.133.82.65): unknown user:
dovecot: auth: ldap(dot,185.125.4.194): unknown user:
dovecot: auth: ldap(dovecot,193.189.117.151): unknown user:
dovecot: auth: ldap(draft,185.125.4.194): unknown user:
dovecot: auth: ldap(dragon,155.133.82.65): unknown user:
dovecot: auth: ldap(drama,155.133.82.65): unknown user:
dovecot: auth: ldap(drawing,185.125.4.194): unknown user:
dovecot: auth: ldap(dream,185.125.4.194): unknown user:
dovecot: auth: ldap(dundee,185.125.4.194): unknown user:
dovecot: auth: ldap(eagle,185.125.4.194): unknown user:
dovecot: auth: ldap(ear,185.125.4.194): unknown user:
dovecot: auth: ldap(easy,193.189.117.148): unknown user:
dovecot: auth: ldap(econom,185.125.4.194): unknown user:
dovecot: auth: ldap(eddy,185.125.4.194): unknown user:
dovecot: auth: ldap(edita,185.125.4.194): unknown user:
dovecot: auth: ldap(edu,185.125.4.194): unknown user:
dovecot: auth: ldap(education,193.189.117.151): unknown user:
dovecot: auth: ldap(eldon,185.125.4.194): unknown user:
dovecot: auth: ldap(elfa,185.125.4.194): unknown user:
dovecot: auth: ldap(eliza,185.125.4.194): unknown user:
dovecot: auth: ldap(elizabeth,193.189.117.151): unknown user:
dovecot: auth: ldap(ellen,185.125.4.194): unknown user:
dovecot: auth: ldap(elsie,185.125.4.194): unknown user:
dovecot: auth: ldap(elvin,185.125.4.194): unknown user:
dovecot: auth: ldap(emmanuel,193.189.117.151): unknown user:
dovecot: auth: ldap(empleos,193.189.117.149): unknown user:
dovecot: auth: ldap(enrique,193.189.117.151): unknown user:
dovecot: auth: ldap(envio,193.189.117.148): unknown user:
dovecot: auth: ldap(erin,193.189.117.151): unknown user:
dovecot: auth: ldap(estel,193.189.117.151): unknown user:
dovecot: auth: ldap(fax@balaskas.gr,212.67.127.105): unknown user:
dovecot: auth: ldap(felipe,193.189.117.149): unknown user:
dovecot: auth: ldap(fischer,193.189.117.151): unknown user:
dovecot: auth: ldap(florence,193.189.117.149): unknown user:
dovecot: auth: ldap(forum,193.189.117.148): unknown user:
dovecot: auth: ldap(fred,193.189.117.149): unknown user:
dovecot: auth: ldap(giuseppe,193.189.117.149): unknown user:
dovecot: auth: ldap(golden,193.189.117.151): unknown user:
dovecot: auth: ldap(hannah,193.189.117.149): unknown user:
dovecot: auth: ldap(henry,193.189.117.148): unknown user:
dovecot: auth: ldap(home,193.189.117.148): unknown user:
dovecot: auth: ldap(howard,193.189.117.151): unknown user:
dovecot: auth: ldap(hudson,193.189.117.149): unknown user:
dovecot: auth: ldap(ian,193.189.117.149): unknown user:
dovecot: auth: ldap(info@balaskas.gr,89.248.162.175): unknown user:
dovecot: auth: ldap(ingrid,193.189.117.151): unknown user:
dovecot: auth: ldap(inspector,193.189.117.151): unknown user:
dovecot: auth: ldap(installer,193.189.117.147): unknown user:
dovecot: auth: ldap(invite,193.189.117.149): unknown user:
dovecot: auth: ldap(irena,193.189.117.151): unknown user:
dovecot: auth: ldap(irene,193.189.117.147): unknown user:
dovecot: auth: ldap(isabel,193.189.117.151): unknown user:
dovecot: auth: ldap(ivan,193.189.117.148): unknown user:
dovecot: auth: ldap(jackie,193.189.117.149): unknown user:
dovecot: auth: ldap(jaime,193.189.117.151): unknown user:
dovecot: auth: ldap(jane,193.189.117.148): unknown user:
dovecot: auth: ldap(jerry,193.189.117.149): unknown user:
dovecot: auth: ldap(jo,193.189.117.151): unknown user:
dovecot: auth: ldap(joanna,193.189.117.148): unknown user:
dovecot: auth: ldap(joaquin,193.189.117.151): unknown user:
dovecot: auth: ldap(job,193.189.117.149): unknown user:
dovecot: auth: ldap(joline,185.125.4.196): unknown user:
dovecot: auth: ldap(jon,193.189.117.147): unknown user:
dovecot: auth: ldap(jose,193.189.117.147): unknown user:
dovecot: auth: ldap(joy,185.125.4.196): unknown user:
dovecot: auth: ldap(js,193.189.117.148): unknown user:
dovecot: auth: ldap(juanita,185.125.4.196): unknown user:
dovecot: auth: ldap(jule,185.125.4.196): unknown user:
dovecot: auth: ldap(julian,193.189.117.149): unknown user:
dovecot: auth: ldap(julieta,185.125.4.196): unknown user:
dovecot: auth: ldap(justin,193.189.117.147): unknown user:
dovecot: auth: ldap(kai,185.125.4.196): unknown user:
dovecot: auth: ldap(karan,185.125.4.196): unknown user:
dovecot: auth: ldap(karina,193.189.117.151): unknown user:
dovecot: auth: ldap(kathy,193.189.117.149): unknown user:
dovecot: auth: ldap(keith,193.189.117.149): unknown user:
dovecot: auth: ldap(keller,185.125.4.196): unknown user:
dovecot: auth: ldap(kelvin,185.125.4.196): unknown user:
dovecot: auth: ldap(kennedy,185.125.4.196): unknown user:
dovecot: auth: ldap(kernel,185.125.4.196): unknown user:
dovecot: auth: ldap(kid,185.125.4.196): unknown user:
dovecot: auth: ldap(kiki,193.189.117.149): unknown user:
dovecot: auth: ldap(kim,193.189.117.147): unknown user:
dovecot: auth: ldap(kimberley,185.125.4.196): unknown user:
dovecot: auth: ldap(kind,185.125.4.196): unknown user:
dovecot: auth: ldap(king,193.189.117.149): unknown user:
dovecot: auth: ldap(kiosk,193.189.117.147): unknown user:
dovecot: auth: ldap(kip,193.189.117.151): unknown user:
dovecot: auth: ldap(kira,193.189.117.151): unknown user:
dovecot: auth: ldap(kirk,185.125.4.196): unknown user:
dovecot: auth: ldap(kirsten,185.125.4.196): unknown user:
dovecot: auth: ldap(kitty,193.189.117.149): unknown user:
dovecot: auth: ldap(knife,185.125.4.196): unknown user:
dovecot: auth: ldap(koko,185.125.4.196): unknown user:
dovecot: auth: ldap(kraft,185.125.4.196): unknown user:
dovecot: auth: ldap(kris,185.125.4.196): unknown user:
dovecot: auth: ldap(kym,185.125.4.196): unknown user:
dovecot: auth: ldap(kyra,185.125.4.196): unknown user:
dovecot: auth: ldap(lane,185.125.4.196): unknown user:
dovecot: auth: ldap(language,185.125.4.196): unknown user:
dovecot: auth: ldap(larkin,185.125.4.196): unknown user:
dovecot: auth: ldap(laurie,185.125.4.196): unknown user:
dovecot: auth: ldap(leadership,193.189.117.156): unknown user:
dovecot: auth: ldap(lenny,185.125.4.196): unknown user:
dovecot: auth: ldap(lenovo,193.189.117.156): unknown user:
dovecot: auth: ldap(leslie,193.189.117.156): unknown user:
dovecot: auth: ldap(level,185.125.4.196): unknown user:
dovecot: auth: ldap(levi,185.125.4.196): unknown user:
dovecot: auth: ldap(libby,185.125.4.196): unknown user:
dovecot: auth: ldap(liliana,193.189.117.156): unknown user:
dovecot: auth: ldap(lina,193.189.117.147): unknown user:
dovecot: auth: ldap(linda,193.189.117.147): unknown user:
dovecot: auth: ldap(lisette,185.125.4.196): unknown user:
dovecot: auth: ldap(local,193.189.117.156): unknown user:
dovecot: auth: ldap(log,193.189.117.151): unknown user:
dovecot: auth: ldap(logs,193.189.117.148): unknown user:
dovecot: auth: ldap(lori,193.189.117.156): unknown user:
dovecot: auth: ldap(louis,193.189.117.156): unknown user:
dovecot: auth: ldap(luciano,193.189.117.148): unknown user:
dovecot: auth: ldap(magdalena,193.189.117.151): unknown user:
dovecot: auth: ldap(maggie,193.189.117.156): unknown user:
dovecot: auth: ldap(main,193.189.117.149): unknown user:
dovecot: auth: ldap(maint,193.189.117.151): unknown user:
dovecot: auth: ldap(management,193.189.117.156): unknown user:
dovecot: auth: ldap(manolo,193.189.117.156): unknown user:
dovecot: auth: ldap(manzanares,193.189.117.156): unknown user:
dovecot: auth: ldap(marcos,193.189.117.151): unknown user:
dovecot: auth: ldap(mariana,193.189.117.149): unknown user:
dovecot: auth: ldap(marion,193.189.117.156): unknown user:
dovecot: auth: ldap(marisa,193.189.117.151): unknown user:
dovecot: auth: ldap(marna,193.189.117.147): unknown user:
dovecot: auth: ldap(martina,193.189.117.156): unknown user:
dovecot: auth: ldap(mat,193.189.117.149): unknown user:
dovecot: auth: ldap(matt,193.189.117.147): unknown user:
dovecot: auth: ldap(mauricio,193.189.117.151): unknown user:
dovecot: auth: ldap(mauro,193.189.117.151): unknown user:
dovecot: auth: ldap(max,193.189.117.151): unknown user:
dovecot: auth: ldap(maximo,193.189.117.156): unknown user:
dovecot: auth: ldap(may,193.189.117.147): unknown user:
dovecot: auth: ldap(mendoza,193.189.117.151): unknown user:
dovecot: auth: ldap(mercadeo,193.189.117.148): unknown user:
dovecot: auth: ldap(mercado,193.189.117.156): unknown user:
dovecot: auth: ldap(meridian,193.189.117.156): unknown user:
dovecot: auth: ldap(message,193.189.117.156): unknown user:
dovecot: auth: ldap(mexico,193.189.117.156): unknown user:
dovecot: auth: ldap(michelle,193.189.117.149): unknown user:
dovecot: auth: ldap(miguel,193.189.117.148): unknown user:
dovecot: auth: ldap(mimi,193.189.117.156): unknown user:
dovecot: auth: ldap(mirella,193.189.117.156): unknown user:
dovecot: auth: ldap(modem,193.189.117.156): unknown user:
dovecot: auth: ldap(montero,185.125.4.191): unknown user:
dovecot: auth: ldap(morales,185.125.4.191): unknown user:
dovecot: auth: ldap(moreno,193.189.117.156): unknown user:
dovecot: auth: ldap(muriel,193.189.117.156): unknown user:
dovecot: auth: ldap(mysql,193.189.117.149): unknown user:
dovecot: auth: ldap(nadia,185.125.4.191): unknown user:
dovecot: auth: ldap(nandi,185.125.4.191): unknown user:
dovecot: auth: ldap(naranjo,193.189.117.156): unknown user:
dovecot: auth: ldap(nathalie,193.189.117.149): unknown user:
dovecot: auth: ldap(nathan,185.125.4.191): unknown user:
dovecot: auth: ldap(nava,185.125.4.191): unknown user:
dovecot: auth: ldap(neil,185.125.4.191): unknown user:
dovecot: auth: ldap(neptune,185.125.4.191): unknown user:
dovecot: auth: ldap(network,193.189.117.156): unknown user:
dovecot: auth: ldap(new,193.189.117.148): unknown user:
dovecot: auth: ldap(newton,185.125.4.191): unknown user:
dovecot: auth: ldap(nicholas,185.125.4.191): unknown user:
dovecot: auth: ldap(nichole,193.189.117.156): unknown user:
dovecot: auth: ldap(nicole,193.189.117.148): unknown user:
dovecot: auth: ldap(nikki,193.189.117.156): unknown user:
dovecot: auth: ldap(nina,193.189.117.149): unknown user:
dovecot: auth: ldap(noc,193.189.117.148): unknown user:
dovecot: auth: ldap(norma,193.189.117.156): unknown user:
dovecot: auth: ldap(norton,193.189.117.156): unknown user:
dovecot: auth: ldap(oleg,193.189.117.156): unknown user:
dovecot: auth: ldap(orlando,185.125.4.191): unknown user:
dovecot: auth: ldap(pablo,193.189.117.148): unknown user:
dovecot: auth: ldap(paige,185.125.4.191): unknown user:
dovecot: auth: ldap(paolo,193.189.117.152): unknown user:
dovecot: auth: ldap(password,185.125.4.191): unknown user:
dovecot: auth: ldap(pat,193.189.117.152): unknown user:
dovecot: auth: ldap(patricia,185.125.4.191): unknown user:
dovecot: auth: ldap(patty,185.125.4.191): unknown user:
dovecot: auth: ldap(payment,185.125.4.191): unknown user:
dovecot: auth: ldap(paz,185.125.4.191): unknown user:
dovecot: auth: ldap(pc03,193.189.117.152): unknown user:
dovecot: auth: ldap(pereira,185.125.4.197): unknown user:
dovecot: auth: ldap(perfil,193.189.117.152): unknown user:
dovecot: auth: ldap(perl,185.125.4.197): unknown user:
dovecot: auth: ldap(perry,185.125.4.191): unknown user:
dovecot: auth: ldap(pharmacy,185.125.4.191): unknown user:
dovecot: auth: ldap(philip,193.189.117.152): unknown user:
dovecot: auth: ldap(phoenix,193.189.117.152): unknown user:
dovecot: auth: ldap(physics,185.125.4.197): unknown user:
dovecot: auth: ldap(pics,185.125.4.197): unknown user:
dovecot: auth: ldap(pie,185.125.4.197): unknown user:
dovecot: auth: ldap(pina,185.125.4.197): unknown user:
dovecot: auth: ldap(place,185.125.4.191): unknown user:
dovecot: auth: ldap(plant,185.125.4.191): unknown user:
dovecot: auth: ldap(point,185.125.4.197): unknown user:
dovecot: auth: ldap(police,185.125.4.191): unknown user:
dovecot: auth: ldap(politics,185.125.4.191): unknown user:
dovecot: auth: ldap(polly,185.125.4.197): unknown user:
dovecot: auth: ldap(pool,185.125.4.191): unknown user:
dovecot: auth: ldap(pop3,185.125.4.197): unknown user:
dovecot: auth: ldap(portatil,193.189.117.148): unknown user:
dovecot: auth: ldap(poster,185.125.4.191): unknown user:
dovecot: auth: ldap(pot,185.125.4.197): unknown user:
dovecot: auth: ldap(potato,185.125.4.197): unknown user:
dovecot: auth: ldap(power,185.125.4.191): unknown user:
dovecot: auth: ldap(practice,185.125.4.197): unknown user:
dovecot: auth: ldap(praise,185.125.4.197): unknown user:
dovecot: auth: ldap(president,185.125.4.197): unknown user:
dovecot: auth: ldap(prince,185.125.4.191): unknown user:
dovecot: auth: ldap(priority,185.125.4.197): unknown user:
dovecot: auth: ldap(process,185.125.4.197): unknown user:
dovecot: auth: ldap(profesor,185.125.4.191): unknown user:
dovecot: auth: ldap(professional,185.125.4.197): unknown user:
dovecot: auth: ldap(professor,193.189.117.154): unknown user:
dovecot: auth: ldap(profile,193.189.117.152): unknown user:
dovecot: auth: ldap(promise,185.125.4.197): unknown user:
dovecot: auth: ldap(protocol,185.125.4.197): unknown user:
dovecot: auth: ldap(proyecto,193.189.117.152): unknown user:
dovecot: auth: ldap(ps,193.189.117.147): unknown user:
dovecot: auth: ldap(puertas,185.125.4.191): unknown user:
dovecot: auth: ldap(python,185.125.4.197): unknown user:
dovecot: auth: ldap(qtss,193.189.117.154): unknown user:
dovecot: auth: ldap(rabia,185.125.4.197): unknown user:
dovecot: auth: ldap(rack,185.125.4.197): unknown user:
dovecot: auth: ldap(rae,185.125.4.197): unknown user:
dovecot: auth: ldap(ralph,185.125.4.191): unknown user:
dovecot: auth: ldap(ram,185.125.4.191): unknown user:
dovecot: auth: ldap(ramiro,193.189.117.154): unknown user:
dovecot: auth: ldap(raquel,185.125.4.197): unknown user:
dovecot: auth: ldap(ray,193.189.117.152): unknown user:
dovecot: auth: ldap(read,185.125.4.197): unknown user:
dovecot: auth: ldap(reality,185.125.4.197): unknown user:
dovecot: auth: ldap(rebecca,193.189.117.154): unknown user:
dovecot: auth: ldap(rechnung,193.189.117.154): unknown user:
dovecot: auth: ldap(recording,185.125.4.197): unknown user:
dovecot: auth: ldap(recover,185.125.4.197): unknown user:
dovecot: auth: ldap(red,193.189.117.154): unknown user:
dovecot: auth: ldap(reed,185.125.4.197): unknown user:
dovecot: auth: ldap(reference,185.125.4.197): unknown user:
dovecot: auth: ldap(register,193.189.117.154): unknown user:
dovecot: auth: ldap(registro,193.189.117.147): unknown user:
dovecot: auth: ldap(remoto,193.189.117.152): unknown user:
dovecot: auth: ldap(ricky,193.189.117.148): unknown user:
dovecot: auth: ldap(robin,193.189.117.147): unknown user:
dovecot: auth: ldap(rocio,193.189.117.154): unknown user:
dovecot: auth: ldap(roger,193.189.117.148): unknown user:
dovecot: auth: ldap(roman,193.189.117.154): unknown user:
dovecot: auth: ldap(rosario,193.189.117.154): unknown user:
dovecot: auth: ldap(ruben,193.189.117.147): unknown user:
dovecot: auth: ldap(sales1,193.189.117.152): unknown user:
dovecot: auth: ldap(sally,193.189.117.152): unknown user:
dovecot: auth: ldap(sam,193.189.117.148): unknown user:
dovecot: auth: ldap(samantha,193.189.117.154): unknown user:
dovecot: auth: ldap(sandi,193.189.117.154): unknown user:
dovecot: auth: ldap(sandra,193.189.117.148): unknown user:
dovecot: auth: ldap(sandy,193.189.117.148): unknown user:
dovecot: auth: ldap(sarah,193.189.117.147): unknown user:
dovecot: auth: ldap(schmidt,193.189.117.152): unknown user:
dovecot: auth: ldap(sean,193.189.117.152): unknown user:
dovecot: auth: ldap(sensor,193.189.117.154): unknown user:
dovecot: auth: ldap(seo,193.189.117.148): unknown user:
dovecot: auth: ldap(share,193.189.117.147): unknown user:
dovecot: auth: ldap(sharon,193.189.117.152): unknown user:
dovecot: auth: ldap(ship,193.189.117.152): unknown user:
dovecot: auth: ldap(simon,193.189.117.147): unknown user:
dovecot: auth: ldap(smile,193.189.117.154): unknown user:
dovecot: auth: ldap(spam,81.168.60.61): unknown user:
dovecot: auth: ldap(spam@balaskas.gr,81.168.60.61): unknown user:
dovecot: auth: ldap(spectrum,193.189.117.147): unknown user:
dovecot: auth: ldap(sql,193.189.117.147): unknown user:
dovecot: auth: ldap(sqlservice,193.189.117.147): unknown user:
dovecot: auth: ldap(staging,193.189.117.152): unknown user:
dovecot: auth: ldap(standard,193.189.117.154): unknown user:
dovecot: auth: ldap(studio,193.189.117.154): unknown user:
dovecot: auth: ldap(summer,193.189.117.152): unknown user:
dovecot: auth: ldap(sunny,193.189.117.152): unknown user:
dovecot: auth: ldap(sync,193.189.117.154): unknown user:
dovecot: auth: ldap(tania,193.189.117.147): unknown user:
dovecot: auth: ldap(tatiana,193.189.117.154): unknown user:
dovecot: auth: ldap(tax,193.189.117.152): unknown user:
dovecot: auth: ldap(telecomunicaciones,193.189.117.152): unknown user:
dovecot: auth: ldap(test@balaskas.gr,89.248.162.175): unknown user:
dovecot: auth: ldap(testpc,193.189.117.154): unknown user:
dovecot: auth: ldap(tools,193.189.117.152): unknown user:
dovecot: auth: ldap(touch,185.125.4.198): unknown user:
dovecot: auth: ldap(tower,185.125.4.198): unknown user:
dovecot: auth: ldap(traci,185.125.4.198): unknown user:
dovecot: auth: ldap(tracy,193.189.117.154): unknown user:
dovecot: auth: ldap(trade,185.125.4.198): unknown user:
dovecot: auth: ldap(traffic,185.125.4.198): unknown user:
dovecot: auth: ldap(train,193.189.117.152): unknown user:
dovecot: auth: ldap(treasure,185.125.4.198): unknown user:
dovecot: auth: ldap(tristan,185.125.4.198): unknown user:
dovecot: auth: ldap(troy,193.189.117.154): unknown user:
dovecot: auth: ldap(trujillo,185.125.4.198): unknown user:
dovecot: auth: ldap(truman,185.125.4.198): unknown user:
dovecot: auth: ldap(ts,193.189.117.154): unknown user:
dovecot: auth: ldap(tucker,185.125.4.198): unknown user:
dovecot: auth: ldap(tyler,185.125.4.198): unknown user:
dovecot: auth: ldap(type,185.125.4.198): unknown user:
dovecot: auth: ldap(ubuntu,193.189.117.154): unknown user:
dovecot: auth: ldap(unicorn,193.189.117.154): unknown user:
dovecot: auth: ldap(union,185.125.4.198): unknown user:
dovecot: auth: ldap(upgrade,193.189.117.154): unknown user:
dovecot: auth: ldap(usuarioprueba,185.125.4.198): unknown user:
dovecot: auth: ldap(uucp,185.125.4.198): unknown user:
dovecot: auth: ldap(val,185.125.4.198): unknown user:
dovecot: auth: ldap(valenzuela,185.125.4.198): unknown user:
dovecot: auth: ldap(valeria,185.125.4.198): unknown user:
dovecot: auth: ldap(valerie,193.189.117.154): unknown user:
dovecot: auth: ldap(valerio,185.125.4.198): unknown user:
dovecot: auth: ldap(value,185.125.4.198): unknown user:
dovecot: auth: ldap(vanessa,193.189.117.152): unknown user:
dovecot: auth: ldap(vector,185.125.4.198): unknown user:
dovecot: auth: ldap(venta,193.189.117.154): unknown user:
dovecot: auth: ldap(ventas2,193.189.117.154): unknown user:
dovecot: auth: ldap(vente,185.125.4.198): unknown user:
dovecot: auth: ldap(verhaal,185.125.4.198): unknown user:
dovecot: auth: ldap(veronique,185.125.4.198): unknown user:
dovecot: auth: ldap(vincenzo,185.125.4.198): unknown user:
dovecot: auth: ldap(virgil,185.125.4.198): unknown user:
dovecot: auth: ldap(vnc,193.189.117.152): unknown user:
dovecot: auth: ldap(voice,185.125.4.198): unknown user:
dovecot: auth: ldap(wall,185.125.4.198): unknown user:
dovecot: auth: ldap(walter,193.189.117.152): unknown user:
dovecot: auth: ldap(watch,185.125.4.198): unknown user:
dovecot: auth: ldap(water,193.189.117.154): unknown user:
dovecot: auth: ldap(wave,185.125.4.198): unknown user:
dovecot: auth: ldap(webmaster,104.160.176.218): unknown user:
dovecot: auth: ldap(webmaster@balaskas.gr,104.160.176.218): unknown user:
dovecot: auth: ldap(william,193.189.117.154): unknown user:
dovecot: auth: ldap(x,193.189.117.152): unknown user:
Reading through “Smart Girl’s Guide to Privacy - Practical Tips for Staying Safe Online by Violet Blue” (totally recommend it), there is a great tip in the first few pages:
- Use different email addresses for different online accounts.
… but is it possible ?
Different Passwords
We already know that we need to use a different password for every site. So we use lastpass or password managers for keeping our different passwords safe. We are nowadays used to create/generate complex passwords for every site, but is it absolutely necessary to also have a different email address for every single one ?
Different Email Addresses
Let me be as clear as I can: There is no obvious answer.
If you value your online privacy and your security threat model is set really high, then Yes you also need a different email address.
But it depends entirely on you and how you use your online identity. Perhaps in social media sites (like facebook or twitter) you dont need to give your personal email address, but perhaps on linkedin you want to use your well-known email-identity. So again, it depends on your security thread model.
Another crucial tip: DO NOT cross-connect your online personas from different social medias.
Disposable Email Server
In this blog post, I will try to describe the simple steps you need to take, to create your own personal disposable email server. In simple words, that means that you can dynamically create and use a unique/specific-site-only email address that you can use for sign-up or register to a new site. Using a different email address & a different passwords for every site online, you are making it really difficult for someone to hack you.
Even if someone can get access to this specific website or -somehow- can retrieve your online account (sites are been hacked every day), you are sure that none of your other online accounts/identities can not be accessed too.
DOMAIN
To do that you will need a disposable domain. It does not have to be something clever or even useful. It needs to be something easy to write & remember. In my opinion, just get a cheap domain. If your registar support WHOIS Privacy, then even better. If dont, then try to find a registar that supports WHOIS Privacy but it isnt a blocking issue.
For this blog post I will use: example.org
Catch-All
In theory, we will create a “catch-all” domain/mail server, that will catch and forward all these emails to our current/primary email address.
DNS
So nice, you have a disposable domain. What next ?
You need to setup a new domain dns zone for your disposable domain.
And then add a MX record, like the notes below:
example.org. 86400 IN MX 0 mail.example.org.
mail.example.org. 86400 IN A 1.2.3.4
replace 1.2.3.4 with the server’s IP !!
Mail Server
Just install postfix !
My “notable” settings are these below:
# postconf -n
inet_interfaces = all
inet_protocols = all
message_size_limit = 35651584
smtp_address_preference = ipv6
smtpd_banner = The sky above the port was the color of television, tuned to a dead channel
virtual_alias_domains = example.org
virtual_alias_maps = hash:/etc/postfix/virtual
In my /etc/postfix/virtual I have these lines:
@example.org my_email_address@example.net
(dont forget to postmap and reload)
# postmap /etc/postfix/virtual
# postfix reload
…. and …. that is it, actually !!!
a. Be aware the my disposable email server is dual stack.
b. If you need to create an emailing list, try something like this:
list@example.org my_email_address@example.net, my_other_email_address@gmail.com
dont forget to:
# postmap /etc/postfix/virtual
and reload postfix:
# postfix reload
How to use it
From now on, whenever you need to type an email address somewhere, just type a new (random or not) email address with this new disposable domain.
The catch-all setting will FWD any email to your primary email address.
I like to use the below specific pattern: When you need to sign-up to a new site, use the sites url as your new email address.
eg. twitter.com
twittercom@example.org
It’s now obvious that next time you get SPAM, you will know which one to blame (I am not suggesting that twitter is sending spam, it is just an example!).
You can also change your email address from all the sites that you have already subscribe (github, mailing lists, etc etc).
Hope this post has been helpful and easy enough for everyone.
Google Reader was -of general acceptance- the best RSS feed reader.
Yahoo had it’s own “perfect” project to parse feeds: Yahoo! Pipes
What did both projects have in common?
They both were cloud projects
that are now discontinued
cause their companies could not profit from them !!!
FreshRSS
So a lot of people started to look up on self-hosted RSS readers to overcome this issue.
Below are my notes on FreshRSS , a free, self-hostable aggregator…
First, download the latest version of FreshRSS:
Download and Setup
# wget -c https://github.com/FreshRSS/FreshRSS/archive/master.zip
# unzip master.zip
# mv FreshRSS-master/ FreshRSS
# chown -R apache:apache FreshRSS
apache
Create a new Virtual Host on apache and use Let’s Encrypt to create a new SSL certificate:
< VirtualHost *:443 >
ServerName FreshRSS.example.com
# SSL Support
SSLEngine on
SSLProtocol ALL -SSLv2 -SSLv3
SSLHonorCipherOrder on
SSLCipherSuite HIGH:!aNULL:!MD5
SSLCertificateFile /etc/letsencrypt/live/FreshRSS.example.com/cert.pem
SSLCertificateKeyFile /etc/letsencrypt/live/FreshRSS.example.com/privkey.pem
SSLCertificateChainFile /etc/letsencrypt/live/FreshRSS.example.com/chain.pem
# Logs
CustomLog logs/FreshRSS.access.log combined
ErrorLog logs/FreshRSS.error.log
DocumentRoot /var/www/html/FreshRSS/
< Directory /var/www/html/FreshRSS/ >
Order allow,deny
Allow from all
< /Directory >
< /VirtualHost >
reload your apache and after that, open your browser to begin the installation process.
Installation



SQLite Backend
I prefer to use SQLite for my backend self-hosted projects, cause the backup process is a lot easier than with mysql.
At this point you have a fresh FreshRSS installation (self-hosted) on your server!
If you just want to use it through your browser, you are done.
OPML
If you already have a OPML (Outline Processor Markup Language) file with your rss/atom feeds, then you can upload it (import) through the Subscription Manager:
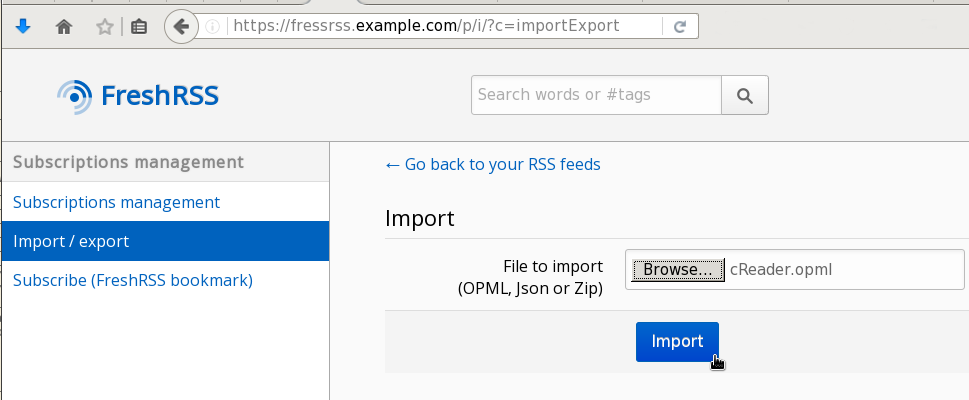
Feeds - Automated Updates
So conclude our FreshRSS setup, we need to automate the update of our feeds. To do that, we just need to add a cron script.
# vim /etc/crontab
*/15 * * * * apache /usr/bin/php /var/www/html/FreshRSS//app/actualize_script.php &> /tmp/fresh.log
EasyRSS
What about your android device (smart phone or tablet) ?
You can use EasyRSS !
Just install it from Fdroid and run it:

FreshRSS - API
To use EasyRSS with FreshRSS, you need to enable the API support from FreshRSS.
The EasyRSS then, will use the api through a token, so to keep things simple enough, we will also change our password to the token ID.
So go to Settings —> Authentication and enable:
Allow API access (required for mobile apps)
Then go to Settings –> Profile and change your password too:
After that, you can now type your settings on your EasyRSS app:
https://freshrss.example.com/p/api/greader.php


Below is my setup to enable Forward secrecy
Generate DH parameters:
# openssl dhparam -out /etc/pki/tls/dh-2048.pem 2048
and then configure your prosody with Let’s Encrypt certificates
VirtualHost "balaskas.gr"
ssl = {
key = "/etc/letsencrypt/live/balaskas.gr/privkey.pem";
certificate = "/etc/letsencrypt/live/balaskas.gr/fullchain.pem";
cafile = "/etc/pki/tls/certs/ca-bundle.crt";
# enable strong encryption
ciphers="EECDH+ECDSA+AESGCM:EECDH+aRSA+AESGCM:EECDH+ECDSA+SHA384:EECDH+ECDSA+SHA256:EECDH+aRSA+SHA384:EECDH+aRSA+SHA256:EECDH+aRSA+RC4:EECDH:EDH+aRSA:!aNULL:!eNULL:!LOW:!3DES:!MD5:!EXP:!PSK:!SRP:!DSS:!RC4";
dhparam = "/etc/pki/tls/dh-2048.pem";
}
if you only want to accept TLS connection from clients and servers, change your settings to these:
c2s_require_encryption = true
s2s_secure_auth = true
Check your setup
or check your certificates with openssl:
Server: # openssl s_client -connect balaskas.gr:5269 -starttls xmpp < /dev/null
Client: # openssl s_client -connect balaskas.gr:5222 -starttls xmpp < /dev/null
Top Ten Linux Distributions and https
A/A | Distro | URL | Verified by | Begin | End | Key
01. | ArchLinux | https://www.archlinux.org/ | Let's Encrypt | 02/24/2016 | 05/24/2016 | 2048
02. | Linux Mint | https://linuxmint.com/ | COMODO CA Limited | 02/24/2016 | 02/24/2017 | 2048
03. | Debian | https://www.debian.org/ | Gandi | 12/11/2015 | 01/21/2017 | 3072
04. | Ubuntu | http://www.ubuntu.com | - | - | - | -
05. | openSUSE | https://www.opensuse.org/ | DigiCert Inc | 02/17/2015 | 04/23/2018 | 2048
06. | Fedora | https://getfedora.org/ | DigiCert Inc | 11/24/2014 | 11/28/2017 | 4096
07. | CentOS | https://www.centos.org/ | DigiCert Inc | 07/29/2014 | 08/02/2017 | 2048
08. | Manjaro | https://manjaro.github.io/ | DigiCert Inc | 01/20/2016 | 04/06/2017 | 2048
09. | Mageia | https://www.mageia.org/ | Gandi | 03/01/2016 | 02/07/2018 | 2048
10. | Kali | https://www.kali.org/ | GeoTrust Inc | 11/09/2014 | 11/12/2018 | 2048