
I really like this comic.
I try to read/learn something every day.
Sometimes, when I find an interesting article, I like to mark it for reading it later.
I use many forms of marking, like pin tabs, bookmarking, sending url via email, save the html page to a folder, save it to my wallabag instance, leave my browser open to this tab, send the URL QR to my phone etc etc etc.
Are all the above ways productive?
None … the time to read something is now!
I mean the first time you lay your eyes upon the article.
Not later, not when you have free time, now.
That’s the way it works with me. Perhaps with you something else is more productive.
I have a short attention span and it is better for me to drop everything and read something carefully that save it for later or some other time.
When I really have to save it for later, my preferable way is to save it to my wallabag instance. It’s perfect and you will love it.
I also have a kobo ebook (e-ink) reader. Not the android based.
From my wallabag I can save them to epub and export them to my kobo.
But I am lazy and I never do it.
My kobo reader has a pocket (getpocket) account.
So I’ve tried to save some articles but not always pocket can parse properly the content of an article. Not even wallabag always work 100%.
The superiority of wallabag (and self-hosted application) is that when a parsing problem occurs I can fix them! Open a git push request and then EVERYBODY in the community will be able to read-this article from this content provider-later. I cant do something like that with pocket or readability.
And then … there are ads !!! Lots of ads, Tons of ads !!!
There is a correct way to do ads and this is when you are not covering the article you want people to read!
The are a lot of wrong ways to do ads: inline the text, above the article, hiding some of the content, make people buy a fee, provide an article to small pages (you know that height in HTML is not a problem, right?) and then there is bandwidth issues.
When I am on my mobile, I DONT want to pay extra for bandwidth I DIDNT ask and certainly do not care about it!!!
If I read the article on my tiny mobile display DO NOT COVER the article with huge ads that I can not find the X-close button because it doesnt fit to my display !!!
So yes, there is a correct way to do ads and that is by respecting the reader and there is a wrong way to do ads.
Getting back to the article’s subject, below you will see six (6) ways to read an article on my desktop. Of course there are hundreds ways but there are the most common ones:
Article: The cyberpunk dystopia we were warned about is already here
https://versions.killscreen.com/cyberpunk-dystopia-warned-already/
Extra info:
windows width: 852
2 times zoom-out to view more text
- Original Post in Firefox 48.0.1
- Wallabag
- Reader View in Firefox
- Chromium 52.0.2743.116
- Midori 0.5.11 - WebKitGTK+ 2.4.11
Click to zoom:
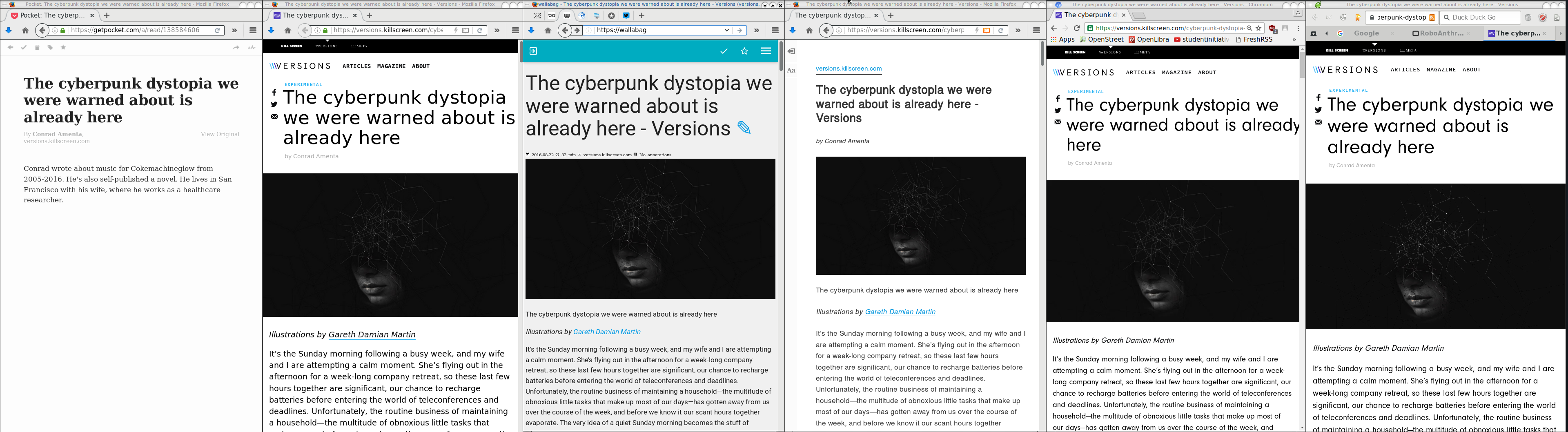
I believe that Reader View in Firefox is the winner of this test. It is clean and it is focusing on the actual article.
Impressive !
I have a compressed file of:
250.000.000 lines
Compressed the file size is: 671M
Uncompressed, it's: 6,5G
Need to extract a plethora of things and verify some others.
I dont want to use bash but something more elegant, like python or lua.
Looking through “The-Internet”, I’ve created some examples for the single purpose of educating my self.
So here are my results.
BE AWARE they are far-far-far away from perfect in code or execution.
Sorted by (less) time of execution:
pigz
# time pigz -p4 -cd 2016-08-04-06.ldif.gz &> /dev/null
real 0m9.980s
user 0m16.570s
sys 0m0.980s
gzip
gzip 1.8
# time /bin/gzip -cd 2016-08-04-06.ldif.gz &> /dev/null
real 0m23.951s
user 0m23.790s
sys 0m0.150s
zcat
zcat (gzip) 1.8
# time zcat 2016-08-04-06.ldif.gz &> /dev/null
real 0m24.202s
user 0m24.100s
sys 0m0.090s
Perl
Perl v5.24.0
code:
#!/usr/bin/perl
open (FILE, '/bin/gzip -cd 2016-08-04-06.ldif.gz |');
while (my $line = ) {
print $line;
}
close FILE;
time:
# time ./dump.pl &> /dev/null
real 0m49.942s
user 1m14.260s
sys 0m2.350s
PHP
PHP 7.0.9 (cli)
code:
#!/usr/bin/php
< ? php
$fp = gzopen("2016-08-04-06.ldif.gz", "r");
while (($buffer = fgets($fp, 4096)) !== false) {
echo $buffer;
}
gzclose($fp);
? >
time:
# time php -f dump.php &> /dev/null
real 1m19.407s
user 1m4.840s
sys 0m14.340s
PHP - Iteration #2
PHP 7.0.9 (cli)
Impressed with php results, I took the perl-approach on code:
< ? php
$fp = popen("/bin/gzip -cd 2016-08-04-06.ldif.gz", "r");
while (($buffer = fgets($fp, 4096)) !== false) {
echo $buffer;
}
pclose($fp);
? >
time:
# time php -f dump2.php &> /dev/null
real 1m6.845s
user 1m15.590s
sys 0m19.940s
not bad !
Lua
Lua 5.3.3
code:
#!/usr/bin/lua
local gzip = require 'gzip'
local filename = "2016-08-04-06.ldif.gz"
for l in gzip.lines(filename) do
print(l)
end
time:
# time ./dump.lua &> /dev/null
real 3m50.899s
user 3m35.080s
sys 0m15.780s
Lua - Iteration #2
Lua 5.3.3
I was depressed to see that php is faster than lua!!
Depressed I say !
So here is my next iteration on lua:
code:
#!/usr/bin/lua
local file = assert(io.popen('/bin/gzip -cd 2016-08-04-06.ldif.gz', 'r'))
while true do
line = file:read()
if line == nil then break end
print (line)
end
file:close()
time:
# time ./dump2.lua &> /dev/null
real 2m45.908s
user 2m54.470s
sys 0m21.360s
One minute faster than before, but still too slow !!
Lua - Zlib
Lua 5.3.3
My next iteration with lua is using zlib :
code:
#!/usr/bin/lua
local zlib = require 'zlib'
local filename = "2016-08-04-06.ldif.gz"
local block = 64
local d = zlib.inflate()
local file = assert(io.open(filename, "rb"))
while true do
bytes = file:read(block)
if not bytes then break end
print (d(bytes))
end
file:close()
time:
# time ./dump.lua &> /dev/null
real 0m41.546s
user 0m40.460s
sys 0m1.080s
Now, that's what I am talking about !!!
Playing with window_size (block) can make your code faster or slower.
Python v3
Python 3.5.2
code:
#!/usr/bin/python
import gzip
filename='2016-08-04-06.ldif.gz'
with gzip.open(filename, 'r') as f:
for line in f:
print(line,)
time:
# time ./dump.py &> /dev/null
real 13m14.460s
user 13m13.440s
sys 0m0.670s
Not enough tissues on the whole damn world!
Python v3 - Iteration #2
Python 3.5.2
but wait ... a moment ... The default mode for gzip.open is 'rb'.
(read binary)
let's try this once more with rt(read-text) mode:
code:
#!/usr/bin/python
import gzip
filename='2016-08-04-06.ldif.gz'
with gzip.open(filename, 'rt') as f:
for line in f:
print(line, end="")
time:
# time ./dump.py &> /dev/null
real 5m33.098s
user 5m32.610s
sys 0m0.410s
With only one super tiny change and run time in half!!!
But still tooo slow.
Python v3 - Iteration #3
Python 3.5.2
Let's try a third iteration with popen this time.
code:
#!/usr/bin/python
import os
cmd = "/bin/gzip -cd 2016-08-04-06.ldif.gz"
f = os.popen(cmd)
for line in f:
print(line, end="")
f.close()
time:
# time ./dump2.py &> /dev/null
real 6m45.646s
user 7m13.280s
sys 0m6.470s
Python v3 - zlib Iteration #1
Python 3.5.2
Let's try a zlib iteration this time.
code:
#!/usr/bin/python
import zlib
d = zlib.decompressobj(zlib.MAX_WBITS | 16)
filename='2016-08-04-06.ldif.gz'
with open(filename, 'rb') as f:
for line in f:
print(d.decompress(line))
time:
# time ./dump.zlib.py &> /dev/null
real 1m4.389s
user 1m3.440s
sys 0m0.410s
finally some proper values with python !!!
Specs
All the running tests occurred to this machine:
4 x Intel(R) Core(TM) i3-3220 CPU @ 3.30GHz
8G RAM
Conclusions
Ok, I Know !
The shell-pipe approach of using gzip for opening the compressed file, is not fair to all the above code snippets.
But ... who cares ?
I need something that run fast as hell and does smart things on those data.
Get in touch
As I am not a developer, I know that you people know how to do these things even better!
So I would love to hear any suggestions or even criticism on the above examples.
I will update/report everything that will pass the "I think I know what this code do" rule and ... be gently with me ;)
PLZ use my email address: evaggelos [ _at_ ] balaskas [ _dot_ ] gr
to send me any suggestions
Thanks !
[Last uptime 2020-12-25]
I need to run some ansible playbooks to a running (live) machine.
But, of-course, I cant use a production server for testing purposes !!
So here comes docker!
I have ssh access from my docker-server to this production server:
ssh livebox tar --one-file-system --sparse -C / -cf - | docker import - centos6:livebox on ubuntu 20.04
ssh livebox sudo tar -cf - --sparse --one-file-system / | docker import - centos6:livebox
Then run the new docker image:
$ docker run -t -i --rm -p 2222:22 centos6:livebox bash
[root@40b2bab2f306 /]# /usr/sbin/sshd -D
Create a new entry on your hosts inventory file, that uses ssh port 2222
or create a new separated inventory file
and test it with ansible ping module:
# ansible -m ping -i hosts.docker dockerlivebox
dockerlivebox | success >> {
"changed": false,
"ping": "pong"
}