Hi! I’m writing this article as a mini-HOWTO on how to setup a btrfs-raid1 volume on encrypted disks (luks). This page servers as my personal guide/documentation, althought you can use it with little intervention.
Disclaimer: Be very careful! This is a mini-HOWTO article, do not copy/paste commands. Modify them to fit your environment.
$ date -R
Thu, 03 Dec 2020 07:58:49 +0200

Prologue
I had to replace one of my existing data/media setup (btrfs-raid0) due to some random hardware errors in one of the disks. The existing disks are 7.1y WD 1TB and the new disks are WD Purple 4TB.
Western Digital Green 1TB, about 70€ each, SATA III (6 Gbit/s), 7200 RPM, 64 MB Cache
Western Digital Purple 4TB, about 100€ each, SATA III (6 Gbit/s), 5400 RPM, 64 MB CacheThis will give me about 3.64T (from 1.86T). I had concerns with the slower RPM but in the end of this article, you will see some related stats.
My primarly daily use is streaming media (video/audio/images) via minidlna instead of cifs/nfs (samba), although the service is still up & running.
Disks
It is important to use disks with the exact same size and speed. Usually for Raid 1 purposes, I prefer using the same model. One can argue that diversity of models and manufactures to reduce possible firmware issues of a specific series should be preferable. When working with Raid 1, the most important things to consider are:
- Geometry (size)
- RPM (speed)
and all the disks should have the same specs, otherwise size and speed will downgraded to the smaller and slower disk.
Identify Disks
the two (2) Western Digital Purple 4TB are manufacture model: WDC WD40PURZ
The system sees them as:
$ sudo find /sys/devices -type f -name model -exec cat {} +
WDC WD40PURZ-85A
WDC WD40PURZ-85T
try to identify them from the kernel with list block devices:
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdc 8:32 0 3.6T 0 disk
sde 8:64 0 3.6T 0 disk
verify it with hwinfo
$ hwinfo --short --disk
disk:
/dev/sde WDC WD40PURZ-85A
/dev/sdc WDC WD40PURZ-85T
$ hwinfo --block --short
/dev/sde WDC WD40PURZ-85A
/dev/sdc WDC WD40PURZ-85T
with list hardware:
$ sudo lshw -short | grep disk
/0/100/1f.5/0 /dev/sdc disk 4TB WDC WD40PURZ-85T
/0/100/1f.5/1 /dev/sde disk 4TB WDC WD40PURZ-85A
$ sudo lshw -class disk -json | jq -r .[].product
WDC WD40PURZ-85T
WDC WD40PURZ-85A
Luks
Create Random Encrypted keys
I prefer to use random generated keys for the disk encryption. This is also useful for automated scripts (encrypt/decrypt disks) instead of typing a pass phrase.
Create a folder to save the encrypted keys:
$ sudo mkdir -pv /etc/crypttab.keys/
create keys with dd against urandom:
WD40PURZ-85A
$ sudo dd if=/dev/urandom of=/etc/crypttab.keys/WD40PURZ-85A bs=4096 count=1
1+0 records in
1+0 records out
4096 bytes (4.1 kB, 4.0 KiB) copied, 0.00015914 s, 25.7 MB/s
WD40PURZ-85T
$ sudo dd if=/dev/urandom of=/etc/crypttab.keys/WD40PURZ-85T bs=4096 count=1
1+0 records in
1+0 records out
4096 bytes (4.1 kB, 4.0 KiB) copied, 0.000135452 s, 30.2 MB/s
verify two (2) 4k size random keys, exist on the above directory with list files:
$ sudo ls -l /etc/crypttab.keys/WD40PURZ-85*
-rw-r--r-- 1 root root 4096 Dec 3 08:00 /etc/crypttab.keys/WD40PURZ-85A
-rw-r--r-- 1 root root 4096 Dec 3 08:00 /etc/crypttab.keys/WD40PURZ-85T
Format & Encrypt Hard Disks
It is time to format and encrypt the hard disks with Luks
Be very careful, choose the correct disk, type uppercase YES to confirm.
$ sudo cryptsetup luksFormat /dev/sde --key-file /etc/crypttab.keys/WD40PURZ-85A
WARNING!
========
This will overwrite data on /dev/sde irrevocably.
Are you sure? (Type 'yes' in capital letters): YES
$ sudo cryptsetup luksFormat /dev/sdc --key-file /etc/crypttab.keys/WD40PURZ-85T
WARNING!
========
This will overwrite data on /dev/sdc irrevocably.
Are you sure? (Type 'yes' in capital letters): YES
Verify Encrypted Disks
print block device attributes:
$ sudo blkid | tail -2
/dev/sde: UUID="d5800c02-2840-4ba9-9177-4d8c35edffac" TYPE="crypto_LUKS"
/dev/sdc: UUID="2ffb6115-09fb-4385-a3c9-404df3a9d3bd" TYPE="crypto_LUKS"
Open and Decrypt
opening encrypted disks with luks
- WD40PURZ-85A
$ sudo cryptsetup luksOpen /dev/disk/by-uuid/d5800c02-2840-4ba9-9177-4d8c35edffac WD40PURZ-85A -d /etc/crypttab.keys/WD40PURZ-85A
- WD40PURZ-85T
$ sudo cryptsetup luksOpen /dev/disk/by-uuid/2ffb6115-09fb-4385-a3c9-404df3a9d3bd WD40PURZ-85T -d /etc/crypttab.keys/WD40PURZ-85T
Verify Status
- WD40PURZ-85A
$ sudo cryptsetup status /dev/mapper/WD40PURZ-85A
/dev/mapper/WD40PURZ-85A is active.
type: LUKS2
cipher: aes-xts-plain64
keysize: 512 bits
key location: keyring
device: /dev/sde
sector size: 512
offset: 32768 sectors
size: 7814004400 sectors
mode: read/write
- WD40PURZ-85T
$ sudo cryptsetup status /dev/mapper/WD40PURZ-85T
/dev/mapper/WD40PURZ-85T is active.
type: LUKS2
cipher: aes-xts-plain64
keysize: 512 bits
key location: keyring
device: /dev/sdc
sector size: 512
offset: 32768 sectors
size: 7814004400 sectors
mode: read/write
BTRFS
Current disks
$sudo btrfs device stats /mnt/data/
[/dev/mapper/western1T].write_io_errs 28632
[/dev/mapper/western1T].read_io_errs 916948985
[/dev/mapper/western1T].flush_io_errs 0
[/dev/mapper/western1T].corruption_errs 0
[/dev/mapper/western1T].generation_errs 0
[/dev/mapper/western1Tb].write_io_errs 0
[/dev/mapper/western1Tb].read_io_errs 0
[/dev/mapper/western1Tb].flush_io_errs 0
[/dev/mapper/western1Tb].corruption_errs 0
[/dev/mapper/western1Tb].generation_errs 0
There are a lot of write/read errors :(
btrfs version
$ sudo btrfs --version
btrfs-progs v5.9
$ sudo mkfs.btrfs --version
mkfs.btrfs, part of btrfs-progs v5.9
Create BTRFS Raid 1 Filesystem
by using mkfs, selecting a disk label, choosing raid1 metadata and data to be on both disks (mirror):
$ sudo mkfs.btrfs
-L WD40PURZ
-m raid1
-d raid1
/dev/mapper/WD40PURZ-85A
/dev/mapper/WD40PURZ-85T
or in one-liner (as-root):
mkfs.btrfs -L WD40PURZ -m raid1 -d raid1 /dev/mapper/WD40PURZ-85A /dev/mapper/WD40PURZ-85T
format output
btrfs-progs v5.9
See http://btrfs.wiki.kernel.org for more information.
Label: WD40PURZ
UUID: 095d3b5c-58dc-4893-a79a-98d56a84d75d
Node size: 16384
Sector size: 4096
Filesystem size: 7.28TiB
Block group profiles:
Data: RAID1 1.00GiB
Metadata: RAID1 1.00GiB
System: RAID1 8.00MiB
SSD detected: no
Incompat features: extref, skinny-metadata
Runtime features:
Checksum: crc32c
Number of devices: 2
Devices:
ID SIZE PATH
1 3.64TiB /dev/mapper/WD40PURZ-85A
2 3.64TiB /dev/mapper/WD40PURZ-85T
Notice that both disks have the same UUID (Universal Unique IDentifier) number:
UUID: 095d3b5c-58dc-4893-a79a-98d56a84d75dVerify block device
$ blkid | tail -2
/dev/mapper/WD40PURZ-85A: LABEL="WD40PURZ" UUID="095d3b5c-58dc-4893-a79a-98d56a84d75d" UUID_SUB="75c9e028-2793-4e74-9301-2b443d922c40" BLOCK_SIZE="4096" TYPE="btrfs"
/dev/mapper/WD40PURZ-85T: LABEL="WD40PURZ" UUID="095d3b5c-58dc-4893-a79a-98d56a84d75d" UUID_SUB="2ee4ec50-f221-44a7-aeac-aa75de8cdd86" BLOCK_SIZE="4096" TYPE="btrfs"once more, be aware of the same UUID: 095d3b5c-58dc-4893-a79a-98d56a84d75d on both disks!
Mount new block disk
create a new mount point
$ sudo mkdir -pv /mnt/WD40PURZ
mkdir: created directory '/mnt/WD40PURZ'
append the below entry in /etc/fstab (as-root)
echo 'UUID=095d3b5c-58dc-4893-a79a-98d56a84d75d /mnt/WD40PURZ auto defaults,noauto,user,exec 0 0' >> /etc/fstab
and finally, mount it!
$ sudo mount /mnt/WD40PURZ
$ mount | grep WD
/dev/mapper/WD40PURZ-85A on /mnt/WD40PURZ type btrfs (rw,nosuid,nodev,relatime,space_cache,subvolid=5,subvol=/)
Disk Usage
check disk usage and free space for the new encrypted mount point
$ df -h /mnt/WD40PURZ/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/WD40PURZ-85A 3.7T 3.4M 3.7T 1% /mnt/WD40PURZ
btrfs filesystem disk usage
$ btrfs filesystem df /mnt/WD40PURZ | column -t
Data, RAID1: total=1.00GiB, used=512.00KiB
System, RAID1: total=8.00MiB, used=16.00KiB
Metadata, RAID1: total=1.00GiB, used=112.00KiB
GlobalReserve, single: total=3.25MiB, used=0.00B
btrfs filesystem show
$ sudo btrfs filesystem show /mnt/WD40PURZ
Label: 'WD40PURZ' uuid: 095d3b5c-58dc-4893-a79a-98d56a84d75d
Total devices 2 FS bytes used 640.00KiB
devid 1 size 3.64TiB used 2.01GiB path /dev/mapper/WD40PURZ-85A
devid 2 size 3.64TiB used 2.01GiB path /dev/mapper/WD40PURZ-85T
stats
$ sudo btrfs device stats /mnt/WD40PURZ/
[/dev/mapper/WD40PURZ-85A].write_io_errs 0
[/dev/mapper/WD40PURZ-85A].read_io_errs 0
[/dev/mapper/WD40PURZ-85A].flush_io_errs 0
[/dev/mapper/WD40PURZ-85A].corruption_errs 0
[/dev/mapper/WD40PURZ-85A].generation_errs 0
[/dev/mapper/WD40PURZ-85T].write_io_errs 0
[/dev/mapper/WD40PURZ-85T].read_io_errs 0
[/dev/mapper/WD40PURZ-85T].flush_io_errs 0
[/dev/mapper/WD40PURZ-85T].corruption_errs 0
[/dev/mapper/WD40PURZ-85T].generation_errs 0
btrfs fi disk usage
btrfs filesystem disk usage
$ sudo btrfs filesystem usage /mnt/WD40PURZ
Overall:
Device size: 7.28TiB
Device allocated: 4.02GiB
Device unallocated: 7.27TiB
Device missing: 0.00B
Used: 1.25MiB
Free (estimated): 3.64TiB (min: 3.64TiB)
Data ratio: 2.00
Metadata ratio: 2.00
Global reserve: 3.25MiB (used: 0.00B)
Multiple profiles: no
Data,RAID1: Size:1.00GiB, Used:512.00KiB (0.05%)
/dev/mapper/WD40PURZ-85A 1.00GiB
/dev/mapper/WD40PURZ-85T 1.00GiB
Metadata,RAID1: Size:1.00GiB, Used:112.00KiB (0.01%)
/dev/mapper/WD40PURZ-85A 1.00GiB
/dev/mapper/WD40PURZ-85T 1.00GiB
System,RAID1: Size:8.00MiB, Used:16.00KiB (0.20%)
/dev/mapper/WD40PURZ-85A 8.00MiB
/dev/mapper/WD40PURZ-85T 8.00MiB
Unallocated:
/dev/mapper/WD40PURZ-85A 3.64TiB
/dev/mapper/WD40PURZ-85T 3.64TiBSpeed
Using hdparm to test/get some speed stats
$ sudo hdparm -tT /dev/sde
/dev/sde:
Timing cached reads: 25224 MB in 1.99 seconds = 12662.08 MB/sec
Timing buffered disk reads: 544 MB in 3.01 seconds = 181.02 MB/sec
$ sudo hdparm -tT /dev/sdc
/dev/sdc:
Timing cached reads: 24852 MB in 1.99 seconds = 12474.20 MB/sec
Timing buffered disk reads: 534 MB in 3.00 seconds = 177.85 MB/sec
$ sudo hdparm -tT /dev/disk/by-uuid/095d3b5c-58dc-4893-a79a-98d56a84d75d
/dev/disk/by-uuid/095d3b5c-58dc-4893-a79a-98d56a84d75d:
Timing cached reads: 25058 MB in 1.99 seconds = 12577.91 MB/sec
HDIO_DRIVE_CMD(identify) failed: Inappropriate ioctl for device
Timing buffered disk reads: 530 MB in 3.00 seconds = 176.56 MB/sec
These are the new disks with 5400 rpm, let’s see what the old 7200 rpm disk shows here:
/dev/sdb:
Timing cached reads: 26052 MB in 1.99 seconds = 13077.22 MB/sec
Timing buffered disk reads: 446 MB in 3.01 seconds = 148.40 MB/sec
/dev/sdd:
Timing cached reads: 25602 MB in 1.99 seconds = 12851.19 MB/sec
Timing buffered disk reads: 420 MB in 3.01 seconds = 139.69 MB/sec
So even that these new disks are 5400 seems to be faster than the old ones !!
Also, I have mounted as read-only the problematic Raid-0 setup.
Rsync
I am now moving some data to measure time
- Folder-A
du -sh /mnt/data/Folder-A/
795G /mnt/data/Folder-A/
time rsync -P -rax /mnt/data/Folder-A/ Folder-A/
sending incremental file list
created directory Folder-A
./
...
real 163m27.531s
user 8m35.252s
sys 20m56.649s- Folder-B
du -sh /mnt/data/Folder-B/
464G /mnt/data/Folder-B/time rsync -P -rax /mnt/data/Folder-B/ Folder-B/
sending incremental file list
created directory Folder-B
./
...
real 102m1.808s
user 7m30.923s
sys 18m24.981s
Control and Monitor Utility for SMART Disks
Last but not least, some smart info with smartmontools
$sudo smartctl -t short /dev/sdc
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.79-1-lts] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Short self-test routine immediately in off-line mode".
Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 2 minutes for test to complete.
Test will complete after Thu Dec 3 08:58:06 2020 EET
Use smartctl -X to abort test.
result :
$sudo smartctl -l selftest /dev/sdc
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.79-1-lts] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 1 -details
$sudo smartctl -A /dev/sdc
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.79-1-lts] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 100 253 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 100 253 021 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 1
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 1
10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 1
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 0
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 1
194 Temperature_Celsius 0x0022 119 119 000 Old_age Always - 31
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 100 253 000 Old_age Offline - 0Second disk
$sudo smartctl -t short /dev/sde
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.79-1-lts] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION ===
Sending command: "Execute SMART Short self-test routine immediately in off-line mode".
Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful.
Testing has begun.
Please wait 2 minutes for test to complete.
Test will complete after Thu Dec 3 09:00:56 2020 EET
Use smartctl -X to abort test.selftest results
$sudo smartctl -l selftest /dev/sde
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.79-1-lts] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 1 -
details
$sudo smartctl -A /dev/sde
smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.79-1-lts] (local build)
Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 100 253 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 100 253 021 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 1
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 100 253 000 Old_age Always - 0
9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 1
10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 1
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 0
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 1
194 Temperature_Celsius 0x0022 116 116 000 Old_age Always - 34
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 100 253 000 Old_age Offline - 0that’s it !
-ebal
Hardware Details
HP ProLiant MicroServer
AMD Turion(tm) II Neo N54L Dual-Core Processor
Memory Size: 2 GB - DIMM Speed: 1333 MT/s
Maximum Capacity: 8 GBRunning 24×7 from 23/08/2010, so nine years!

Prologue
The above server started it’s life on CentOS 5 and ext3. Re-formatting to run CentOS 6.x with ext4 on 4 x 1TB OEM Hard Disks with mdadm raid-5. That provided 3 TB storage with Fault tolerance 1-drive failure. And believe me, I used that setup to zeroing broken disks or replacing faulty disks.
As we are reaching the end of CentOS 6.x and there is no official dist-upgrade path for CentOS, and still waiting for CentOS 8.x, I made decision to switch to Ubuntu 18.04 LTS. At that point this would be the 3rd official OS re-installation of this server. I chose ubuntu so that I can dist-upgrade from LTS to LTS.
This is a backup server, no need for huge RAM, but for a reliable system. On that storage I have 2m files that in retrospect are not very big. So with the re-installation I chose to use xfs instead of ext4 filesystem.
I am also running an internal snapshot mechanism to have delta for every day and that pushed the storage usage to 87% of the 3Tb. If you do the math, 2m is about 1.2Tb usage, we need a full initial backup, so 2.4Tb (80%) and then the daily (rotate) incremental backups are ~210Mb per day. That gave me space for five (5) daily snapshots aka a work-week.
To remove this impediment, I also replaced the disks with WD Red Pro 6TB 7200rpm disks, and use raid-1 instead of raid-5. Usage is now ~45%
Problem
Frozen System
From time to time, this very new, very clean, very reliable system froze to death!
When attached monitor & keyboard no output. Strange enough I can ping the network interfaces but I can not ssh to the server or even telnet (nc) to ssh port. Awkward! Okay - hardware cold reboot then.
As this system is remote … in random times, I need to ask from someone to cold-reboot this machine. Awkward again.
Kernel Panic
If that was not enough, this machine also has random kernel panics.

Errors
Let’s start troubleshooting this system
# journalctl -p 3 -x
Important Errors
ERST: Failed to get Error Log Address Range.
APEI: Can not request [mem 0x7dfab650-0x7dfab6a3] for APEI BERT registers
ipmi_si dmi-ipmi-si.0: Could not set up I/O spaceand more important Errors:
INFO: task kswapd0:40 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task xfsaild/dm-0:761 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/u9:2:3612 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/1:0:5327 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task rm:5901 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/u9:1:5902 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/0:0:5906 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kswapd0:40 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task xfsaild/dm-0:761 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
INFO: task kworker/u9:2:3612 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
First impressions ?

BootOptions
After a few (hours) of internet research the suggestion is to disable
- ACPI stands for Advanced Configuration and Power Interface.
- APIC stands for Advanced Programmable Interrupt Controller.
This site is very helpful for ubuntu, although Red Hat still has a huge advanced on describing kernel options better than canonical.
Grub
# vim /etc/default/grub
GRUB_CMDLINE_LINUX="noapic acpi=off"then
# update-grub
Sourcing file `/etc/default/grub'
Sourcing file `/etc/default/grub.d/50-curtin-settings.cfg'
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-4.15.0-54-generic
Found initrd image: /boot/initrd.img-4.15.0-54-generic
Found linux image: /boot/vmlinuz-4.15.0-52-generic
Found initrd image: /boot/initrd.img-4.15.0-52-generic
doneVerify
# grep noapic /boot/grub/grub.cfg | head -1
linux /boot/vmlinuz-4.15.0-54-generic root=UUID=0c686739-e859-4da5-87a2-dfd5fcccde3d ro noapic acpi=off maybe-ubiquityreboot and check again:
# journalctl -p 3 -xb
-- Logs begin at Thu 2019-03-14 19:26:12 EET, end at Wed 2019-07-03 21:31:08 EEST. --
Jul 03 21:30:49 servertwo kernel: ipmi_si dmi-ipmi-si.0: Could not set up I/O spaceokay !!!
ipmi_si
Unfortunately I could not find anything useful regarding
# dmesg | grep -i ipm
[ 10.977914] ipmi message handler version 39.2
[ 11.188484] ipmi device interface
[ 11.203630] IPMI System Interface driver.
[ 11.203662] ipmi_si dmi-ipmi-si.0: ipmi_platform: probing via SMBIOS
[ 11.203665] ipmi_si: SMBIOS: mem 0x0 regsize 1 spacing 1 irq 0
[ 11.203667] ipmi_si: Adding SMBIOS-specified kcs state machine
[ 11.203729] ipmi_si: Trying SMBIOS-specified kcs state machine at mem address 0x0, slave address 0x20, irq 0
[ 11.203732] ipmi_si dmi-ipmi-si.0: Could not set up I/O space
# ipmitool list
Could not open device at /dev/ipmi0 or /dev/ipmi/0 or /dev/ipmidev/0: No such file or directory
# lsmod | grep -i ipmi
ipmi_si 61440 0
ipmi_devintf 20480 0
ipmi_msghandler 53248 2 ipmi_devintf,ipmi_si
blocked for more than 120 seconds.
But let’s try to fix the timeout warnings:
INFO: task kswapd0:40 blocked for more than 120 seconds.
Not tainted 4.15.0-54-generic #58-Ubuntu
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this messageif you search online the above message, most of the sites will suggest to tweak dirty pages for your system.
This is the most common response across different sites:
This is a know bug. By default Linux uses up to 40% of the available memory for file system caching. After this mark has been reached the file system flushes all outstanding data to disk causing all following IOs going synchronous. For flushing out this data to disk this there is a time limit of 120 seconds by default. In the case here the IO subsystem is not fast enough to flush the data withing 120 seconds. This especially happens on systems with a lot of memory.
Okay this may be the problem but we do not have a lot of memory, only 2GB RAM and 2GB Swap. But even then, our vm.dirty_ratio = 20 setting is 20% instead of 40%.
But I have the ability to cross-check ubuntu 18.04 with CentOS 6.10 to compare notes:
ubuntu 18.04
# uname -r
4.15.0-54-generic
# sysctl -a | egrep -i 'swap|dirty|raid'|sort
dev.raid.speed_limit_max = 200000
dev.raid.speed_limit_min = 1000
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
vm.dirtytime_expire_seconds = 43200
vm.dirty_writeback_centisecs = 500
vm.swappiness = 60
CentOS 6.11
# uname -r
2.6.32-754.15.3.el6.centos.plus.x86_64
# sysctl -a | egrep -i 'swap|dirty|raid'|sort
dev.raid.speed_limit_max = 200000
dev.raid.speed_limit_min = 1000
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
vm.dirty_writeback_centisecs = 500
vm.swappiness = 60
Scheduler for Raid
This is the best online documentation on the
optimize raid
Comparing notes we see that both systems have the same settings, even when the kernel version is a lot different, 2.6.32 Vs 4.15.0 !!!
Researching on raid optimization there is a note of kernel scheduler.
Ubuntu 18.04
# for drive in {a..c}; do cat /sys/block/sd${drive}/queue/scheduler; done
noop deadline [cfq]
noop deadline [cfq]
noop deadline [cfq]
CentOS 6.11
# for drive in {a..d}; do cat /sys/block/sd${drive}/queue/scheduler; done
noop anticipatory deadline [cfq]
noop anticipatory deadline [cfq]
noop anticipatory deadline [cfq]
noop anticipatory deadline [cfq]
Anticipatory scheduling
CentOS supports Anticipatory scheduling on the hard disks but nowadays anticipatory scheduler is not supported in modern kernel versions.
That said, from the above output we can verify that both systems are running the default scheduler cfq.
Disks
Ubuntu 18.04
- Western Digital Red Pro WDC WD6003FFBX-6
# for i in sd{b..c} ; do hdparm -Tt /dev/$i; done
/dev/sdb:
Timing cached reads: 2344 MB in 2.00 seconds = 1171.76 MB/sec
Timing buffered disk reads: 738 MB in 3.00 seconds = 245.81 MB/sec
/dev/sdc:
Timing cached reads: 2264 MB in 2.00 seconds = 1131.40 MB/sec
Timing buffered disk reads: 774 MB in 3.00 seconds = 257.70 MB/secCentOS 6.11
- Seagate ST1000DX001
/dev/sdb:
Timing cached reads: 2490 MB in 2.00 seconds = 1244.86 MB/sec
Timing buffered disk reads: 536 MB in 3.01 seconds = 178.31 MB/sec
/dev/sdc:
Timing cached reads: 2524 MB in 2.00 seconds = 1262.21 MB/sec
Timing buffered disk reads: 538 MB in 3.00 seconds = 179.15 MB/sec
/dev/sdd:
Timing cached reads: 2452 MB in 2.00 seconds = 1226.15 MB/sec
Timing buffered disk reads: 546 MB in 3.01 seconds = 181.64 MB/sec
So what I am missing ?
My initial personal feeling was the low memory. But after running a manual rsync I’ve realized that:
cpu
was load average: 0.87, 0.46, 0.19
mem
was (on high load), when hit 40% of RAM, started to use swap.
KiB Mem : 2008464 total, 77528 free, 635900 used, 1295036 buff/cache
KiB Swap: 2097148 total, 2096624 free, 524 used. 1184220 avail Mem So I tweaked a bit the swapiness and reduce it from 60% to 40%
and run a local snapshot (that is a bit heavy on the disks) and doing an upgrade and trying to increase CPU load. Still everything is fine !
I will keep an eye on this story.

I use Linux Software RAID for years now. It is reliable and stable (as long as your hard disks are reliable) with very few problems. One recent issue -that the daily cron raid-check was reporting- was this:
WARNING: mismatch_cnt is not 0 on /dev/md0
Raid Environment
A few details on this specific raid setup:
RAID 5 with 4 Drives
with 4 x 1TB hard disks and according the online raid calculator:
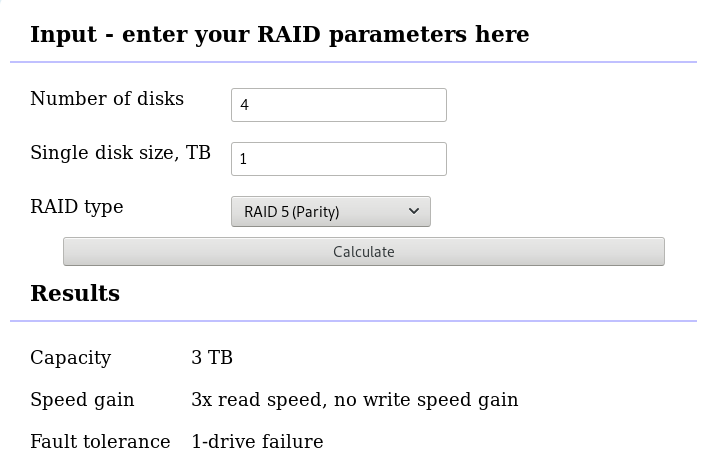
that means this setup is fault tolerant and cheap but not fast.
Raid Details
# /sbin/mdadm --detail /dev/md0
raid configuration is valid
/dev/md0:
Version : 1.2
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sat Oct 27 04:38:04 2018
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : ServerTwo:0 (local to host ServerTwo)
UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Events : 60352
Number Major Minor RaidDevice State
4 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
6 8 48 2 active sync /dev/sdd
5 8 0 3 active sync /dev/sda
Examine Verbose Scan
with a more detailed output:
# mdadm -Evvvvs
there are a few Bad Blocks, although it is perfectly normal for a two (2) year disks to have some. smartctl is a tool you need to use from time to time.
/dev/sdd:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Name : ServerTwo:0 (local to host ServerTwo)
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 1953266096 (931.39 GiB 1000.07 GB)
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 1953262592 (931.39 GiB 1000.07 GB)
Data Offset : 259072 sectors
Super Offset : 8 sectors
Unused Space : before=258984 sectors, after=3504 sectors
State : clean
Device UUID : bdd41067:b5b243c6:a9b523c4:bc4d4a80
Update Time : Sun Oct 28 09:04:01 2018
Bad Block Log : 512 entries available at offset 72 sectors
Checksum : 6baa02c9 - correct
Events : 60355
Layout : left-symmetric
Chunk Size : 512K
Device Role : Active device 2
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)
/dev/sde:
MBR Magic : aa55
Partition[0] : 8388608 sectors at 2048 (type 82)
Partition[1] : 226050048 sectors at 8390656 (type 83)
/dev/sdc:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Name : ServerTwo:0 (local to host ServerTwo)
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 1953263024 (931.39 GiB 1000.07 GB)
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 1953262592 (931.39 GiB 1000.07 GB)
Data Offset : 259072 sectors
Super Offset : 8 sectors
Unused Space : before=258992 sectors, after=3504 sectors
State : clean
Device UUID : a90e317e:43848f30:0de1ee77:f8912610
Update Time : Sun Oct 28 09:04:01 2018
Checksum : 30b57195 - correct
Events : 60355
Layout : left-symmetric
Chunk Size : 512K
Device Role : Active device 1
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)
/dev/sdb:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Name : ServerTwo:0 (local to host ServerTwo)
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 1953263024 (931.39 GiB 1000.07 GB)
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 1953262592 (931.39 GiB 1000.07 GB)
Data Offset : 259072 sectors
Super Offset : 8 sectors
Unused Space : before=258984 sectors, after=3504 sectors
State : clean
Device UUID : ad7315e5:56cebd8c:75c50a72:893a63db
Update Time : Sun Oct 28 09:04:01 2018
Bad Block Log : 512 entries available at offset 72 sectors
Checksum : b928adf1 - correct
Events : 60355
Layout : left-symmetric
Chunk Size : 512K
Device Role : Active device 0
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)
/dev/sda:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Name : ServerTwo:0 (local to host ServerTwo)
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 1953263024 (931.39 GiB 1000.07 GB)
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 1953262592 (931.39 GiB 1000.07 GB)
Data Offset : 259072 sectors
Super Offset : 8 sectors
Unused Space : before=258984 sectors, after=3504 sectors
State : clean
Device UUID : f4e1da17:e4ff74f0:b1cf6ec8:6eca3df1
Update Time : Sun Oct 28 09:04:01 2018
Bad Block Log : 512 entries available at offset 72 sectors
Checksum : bbe3e7e8 - correct
Events : 60355
Layout : left-symmetric
Chunk Size : 512K
Device Role : Active device 3
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)
MisMatch Warning
WARNING: mismatch_cnt is not 0 on /dev/md0
So this is not a critical error, rather tells us that there are a few blocks that are “Not Synced Yet” across all disks.
Status
Checking the Multiple Device (md) driver status:
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]We verify that none job is running on the raid.
Repair
We can run a manual repair job:
# echo repair >/sys/block/md0/md/sync_action
now status looks like:
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[=========>...........] resync = 45.6% (445779112/976631296) finish=54.0min speed=163543K/sec
unused devices: <none>
Progress
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[============>........] resync = 63.4% (619673060/976631296) finish=38.2min speed=155300K/sec
unused devices: <none>Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[================>....] resync = 81.9% (800492148/976631296) finish=21.6min speed=135627K/sec
unused devices: <none>
Finally
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
unused devices: <none>
Check
After repair is it useful to check again the status of our software raid:
# echo check >/sys/block/md0/md/sync_action
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[=>...................] check = 9.5% (92965776/976631296) finish=91.0min speed=161680K/sec
unused devices: <none>and finally
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
unused devices: <none>Linux Raid
This blog post is created as a mental note for future reference
Linux Raid is the de-facto way for decades in the linux-world on how to create and use a software raid. RAID stands for: Redundant Array of Independent Disks. Some people use the I for inexpensive disks, I guess that works too!
In simple terms, you can use a lot of hard disks to behave as one disk with special capabilities!
You can use your own inexpensive/independent hard disks as long as they have the same geometry and you can do almost everything. Also it’s pretty easy to learn and use linux raid. If you dont have the same geometry, then linux raid will use the smallest one from your disks. Modern methods, like LVM and BTRFS can provide an abstract layer with more capabilities to their users, but some times (or because something you have built a loooong time ago) you need to go back to basics.
And every time -EVERY time- I am searching online for all these cool commands that those cool kids are using. Cause what’s more exciting than replacing your -a decade ago- linux raid setup this typical Saturday night?
Identify your Hard Disks
% find /sys/devices/ -type f -name model -exec cat {} \;
ST1000DX001-1CM1
ST1000DX001-1CM1
ST1000DX001-1CM1
% lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 931.5G 0 disk
sdb 8:16 0 931.5G 0 disk
sdc 8:32 0 931.5G 0 disk
% lsblk -io KNAME,TYPE,SIZE,MODEL
KNAME TYPE SIZE MODEL
sda disk 931.5G ST1000DX001-1CM1
sdb disk 931.5G ST1000DX001-1CM1
sdc disk 931.5G ST1000DX001-1CM1
Create a RAID-5 with 3 Disks
Having 3 hard disks of 1T size, we are going to use the raid-5 Level . That means that we have 2T of disk usage and the third disk with keep the parity of the first two disks. Raid5 provides us with the benefit of loosing one hard disk without loosing any data from our hard disk scheme.

% mdadm -C -v /dev/md0 --level=5 --raid-devices=3 /dev/sda /dev/sdb /dev/sdc
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 512K
mdadm: sze set to 5238784K
mdadm: Defaulting to version 1.2 metadata
md/raid:md0 raid level 5 active with 2 our of 3 devices, algorithm 2
mdadm: array /dev/md0 started.
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0: active raid5 sdc[3] sdb[2] sda[1]
10477568 blocks super 1.2 level 5, 512k chink, algorith 2 [3/3] [UUU]
unused devices: <none>
running lsblk will show us our new scheme:
# lsblk -io KNAME,TYPE,SIZE,MODEL
KNAME TYPE SIZE MODEL
sda disk 931.5G ST1000DX001-1CM1
md0 raid5 1.8T
sdb disk 931.5G ST1000DX001-1CM1
md0 raid5 1.8T
sdc disk 931.5G ST1000DX001-1CM1
md0 raid5 1.8T
Save the Linux Raid configuration into a file
Software linux raid means that the raid configuration is actually ON the hard disks. You can take those 3 disks and put them to another linux box and everything will be there!! If you are keeping your operating system to another harddisk, you can also change your linux distro from one to another and your data will be on your linux raid5 and you can access them without any extra software from your new linux distro.
But it is a good idea to keep the basic conf to a specific configuration file, so if you have hardware problems your machine could understand what type of linux raid level you need to have on those broken disks!
% mdadm --detail --scan >> /etc/mdadm.conf
% cat /etc/mdadm.conf
ARRAY /dev/md0 metadata=1.2 name=MyServer:0 UUID=ef5da4df:3e53572e:c3fe1191:925b24cf
UUID - Universally Unique IDentifier
Be very careful that the above UUID is the UUID of the linux raid on your disks.
We have not yet created a filesystem over this new disk /dev/md0 and if you need to add this filesystem under your fstab file you can not use the UUID of the linux raid md0 disk.
Below there is an example on my system:
% blkid
/dev/sda: UUID="ef5da4df-3e53-572e-c3fe-1191925b24cf" UUID_SUB="f4e1da17-e4ff-74f0-b1cf-6ec86eca3df1" LABEL="MyServer:0" TYPE="linux_raid_member"
/dev/sdb: UUID="ef5da4df-3e53-572e-c3fe-1191925b24cf" UUID_SUB="ad7315e5-56ce-bd8c-75c5-0a72893a63db" LABEL="MyServer:0" TYPE="linux_raid_member"
/dev/sdc: UUID="ef5da4df-3e53-572e-c3fe-1191925b24cf" UUID_SUB="a90e317e-4384-8f30-0de1-ee77f8912610" LABEL="MyServer:0" TYPE="linux_raid_member"
/dev/md0: LABEL="data" UUID="48fc963a-2128-4d35-85fb-b79e2546dce7" TYPE="ext4"
% cat /etc/fstab
UUID=48fc963a-2128-4d35-85fb-b79e2546dce7 /backup auto defaults 0 0
Replacing a hard disk
Hard disks will fail you. This is a fact that every sysadmin knows from day one. Systems will fail at some point in the future. So be prepared and keep backups !!
Failing a disk
Now it’s time to fail (if not already) the disk we want to replace:
% mdadm --manage /dev/md0 --fail /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md0
Remove a broken disk
Here is a simple way to remove a broken disk from your linux raid configuration. Remember with raid5 level we can manage with 2 hard disks.
% mdadm --manage /dev/md0 --remove /dev/sdb
mdadm: hot removed /dev/sdb from /dev/md0
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
unused devices: <none>
dmesg shows:
% dmesg | tail
md: data-check of RAID array md0
md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for data-check.
md: using 128k window, over a total of 976631296k.
md: md0: data-check done.
md/raid:md0: Disk failure on sdb, disabling device.
md/raid:md0: Operation continuing on 2 devices.
RAID conf printout:
--- level:5 rd:3 wd:2
disk 0, o:0, dev:sda
disk 1, o:1, dev:sdb
disk 2, o:1, dev:sdc
RAID conf printout:
--- level:5 rd:3 wd:2
disk 0, o:0, dev:sda
disk 2, o:1, dev:sdc
md: unbind<sdb>
md: export_rdev(sdb)
Adding a new disk - replacing a broken one
Now it’s time to add a new and (if possible) clean hard disk. Just to be sure, I always wipe with dd the first few kilobytes of every disk with zeros.
Using mdadm to add this new disk:
# mdadm --manage /dev/md0 --add /dev/sdb
mdadm: added /dev/sdb
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb[4] sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[>....................] recovery = 0.2% (2753372/976631296) finish=189.9min speed=85436K/sec
unused devices: <none>
For a 1T Hard Disk is about 3h of recovering data. Keep that in mind on scheduling the maintenance window.
after a few minutes:
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb[4] sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[>....................] recovery = 4.8% (47825800/976631296) finish=158.3min speed=97781K/sec
unused devices: <none>
mdadm shows:
% mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Array Size : 1953262592 (1862.78 GiB 2000.14 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Mon Oct 17 21:52:05 2016
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Rebuild Status : 58% complete
Name : MyServer:0 (local to host MyServer)
UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Events : 554
Number Major Minor RaidDevice State
1 8 16 1 active sync /dev/sda
4 8 32 0 spare rebuilding /dev/sdb
3 8 48 2 active sync /dev/sdc
You can use watch command that refreshes every two seconds your terminal with the output :
# watch cat /proc/mdstat
Every 2.0s: cat /proc/mdstat Mon Oct 17 21:53:34 2016
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb[4] sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[===========>.........] recovery = 59.4% (580918844/976631296) finish=69.2min speed=95229K/sec
unused devices: <none>
Growing a Linux Raid
Even so … 2T is not a lot of disk usage these days! If you need to grow-extend your linux raid, then you need hard disks with the same geometry (or larger).
Steps on growing your linux raid are also simply:
# Umount the linux raid device:
% umount /dev/md0
# Add the new disk
% mdadm --add /dev/md0 /dev/sdd
# Check mdstat
% cat /proc/mdstat
# Grow linux raid by one device
% mdadm --grow /dev/md0 --raid-devices=4
# watch mdstat for reshaping to complete - also 3h+ something
% watch cat /proc/mdstat
# Filesystem check your linux raid device
% fsck -y /dev/md0
# Resize - Important
% resize2fs /dev/md0
But sometimes life happens …
Need 1 spare to avoid degraded array, and only have 0.
mdadm: Need 1 spare to avoid degraded array, and only have 0.
or
mdadm: Failed to initiate reshape!
Sometimes you get an error that informs you that you can not grow your linux raid device! It’s not time to panic or flee the scene. You’ve got this. You have already kept a recent backup before you started and you also reading this blog post!
You need a (an extra) backup-file !
% mdadm --grow --raid-devices=4 --backup-file=/tmp/backup.file /dev/md0
mdadm: Need to backup 3072K of critical section..
% cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sda[4] sdb[0] sdd[3] sdc[1]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[>....................] reshape = 0.0
% (66460/976631296) finish=1224.4min speed=13292K/sec
unused devices: <none>
1224.4min seems a lot !!!
dmesg shows:
% dmesg
[ 36.477638] md: Autodetecting RAID arrays.
[ 36.477649] md: Scanned 0 and added 0 devices.
[ 36.477654] md: autorun ...
[ 36.477658] md: ... autorun DONE.
[ 602.987144] md: bind<sda>
[ 603.219025] RAID conf printout:
[ 603.219036] --- level:5 rd:3 wd:3
[ 603.219044] disk 0, o:1, dev:sdb
[ 603.219050] disk 1, o:1, dev:sdc
[ 603.219055] disk 2, o:1, dev:sdd
[ 608.650884] RAID conf printout:
[ 608.650896] --- level:5 rd:3 wd:3
[ 608.650903] disk 0, o:1, dev:sdb
[ 608.650910] disk 1, o:1, dev:sdc
[ 608.650915] disk 2, o:1, dev:sdd
[ 684.308820] RAID conf printout:
[ 684.308832] --- level:5 rd:4 wd:4
[ 684.308840] disk 0, o:1, dev:sdb
[ 684.308846] disk 1, o:1, dev:sdc
[ 684.308851] disk 2, o:1, dev:sdd
[ 684.308855] disk 3, o:1, dev:sda
[ 684.309079] md: reshape of RAID array md0
[ 684.309089] md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
[ 684.309094] md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for reshape.
[ 684.309105] md: using 128k window, over a total of 976631296k.
mdstat
% cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sda[4] sdb[0] sdd[3] sdc[1]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[>....................] reshape = 0.0
% (349696/976631296) finish=697.9min speed=23313K/sec
unused devices: <none>ok it’s now 670minutes
Time to use watch:
(after a while)
% watch cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sda[4] sdb[0] sdd[3] sdc[1]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[===========>......] reshape = 66.1% (646514752/976631296) finish=157.4min speed=60171K/sec
unused devices: <none>
mdadm shows:
% mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 6 13:06:34 2014
Raid Level : raid5
Array Size : 1953262592 (1862.78 GiB 2000.14 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sat Oct 22 14:59:33 2016
State : clean, reshaping
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Reshape Status : 66% complete
Delta Devices : 1, (3->4)
Name : MyServer:0
UUID : d635095e:50457059:7e6ccdaf:7da91c9b
Events : 1536
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
3 8 48 2 active sync /dev/sdd
4 8 0 3 active sync /dev/sdabe patient and keep an aye on mdstat under proc.
So basically those are the steps, hopefuly you will find them useful.