I’ve been using btrfs for a decade now (yes, than means 10y) on my setup (btw I use ArchLinux). I am using subvolumes and read-only snapshots with btrfs, but I have never created a script to automate my backups.
I KNOW, WHAT WAS I DOING ALL THESE YEARS!!A few days ago, a dear friend asked me something about btrfs snapshots, and that question gave me the nudge to think about my btrfs subvolume snapshots and more specific how to automate them. A day later, I wrote a simple (I think so) script to do automate my backups.
The script as a gist
The script is online as a gist here: BTRFS: Automatic Snapshots Script . In this blog post, I’ll try to describe the requirements and what is my thinking. I waited a couple weeks so the cron (or systemd timer) script run itself and verify that everything works fine. Seems that it does (at least for now) and the behaviour is as expected. I will keep a static copy of my script in this blog post but any future changes should be done in the above gist.
Improvements
The script can be improved by many,many ways (check available space before run, measure the time of running, remove sudo, check if root is running the script, verify the partitions are on btrfs, better debugging, better reporting, etc etc). These are some of the ways of improving the script, I am sure you can think a million more - feel free to sent me your proposals. If I see something I like, I will incorporate them and attribute of-course. But be reminded that I am not driven by smart code, I prefer to have clear and simple code, something that everybody can easily read and understand.
Mount Points
To be completely transparent, I encrypt all my disks (usually with a random keyfile). I use btrfs raid1 on the disks and create many subvolumes on them. Everything exists outside of my primary ssd rootfs disk. So I use a small but fast ssd for my operating system and btrfs-raid1 for my “spinning rust” disks.
BTRFS subvolumes can be mounted as normal partitions and that is exactly what I’ve done with my home and opt. I keep everything that I’ve install outside of my distribution under opt.
This setup is very flexible as I can easy replace the disks when the storage is full by removing one by one of the disks from btrfs-raid1, remove-add the new larger disk, repair-restore raid, then remove the other disk, install the second and (re)balance the entire raid1 on them!
Although this is out of scope, I use a stub archlinux UEFI kernel so I do not have grub and my entire rootfs is also encrypted and btrfs!
mount -o subvolid=10701 LABEL="ST1000DX002" /home
mount -o subvolid=10657 LABEL="ST1000DX002" /opt
Declare variables
# paths MUST end with '/'
btrfs_paths=("/" "/home/" "/opt/")
timestamp=$(date +%Y%m%d_%H%M%S)
keep_snapshots=3
yymmdd="$(date +%Y/%m/%d)"
logfile="/var/log/btrfsSnapshot/${yymmdd}/btrfsSnapshot.log"
The first variable in the script is actually a bash array
btrfs_paths=("/" "/home/" "/opt/")
and all three (3) paths (rootfs, home & opt) are different mount points on different encrypted disks.
MUST end with / (forward slash), either-wise something catastrophic will occur to your system. Be very careful. Please, be very careful!
Next variable is the timestamp we will use, that will create something like
partition_YYYYMMDD_HHMMSS
After that is how many snapshots we would like to keep to our system. You can increase it to whatever you like. But be careful of the storage.
keep_snapshots=3
I like using shortcuts in shell scripts to reduce the long one-liners that some people think that it is alright. I dont, so
yymmdd="$(date +%Y/%m/%d)"
is one of these shortcuts !
Last, I like to have a logfile to review at a later time and see what happened.
logfile="/var/log/btrfsSnapshot/${yymmdd}/btrfsSnapshot.log"
Log Directory
for older dudes -like me- you know that you can not have all your logs under one directory but you need to structure them. The above yymmdd shortcut can help here. As I am too lazy to check if the directory already exist, I just (re)create the log directory that the script will use.
sudo mkdir -p "/var/log/btrfsSnapshot/${yymmdd}/"
For - Loop
We enter to the crucial part of the script. We are going to iterate our btrfs commands in a bash for-loop structure so we can run the same commands for all our partitions (variable: btrfs_paths)
for btrfs_path in "${btrfs_paths[@]}"; do
<some commands>
done
Snapshot Directory
We need to have our snapshots in a specific location. So I chose .Snapshot/ under each partition. And I am silently (re)creating this directory -again I am lazy, someone should check if the directory/path already exist- just to be sure that the directory exist.
sudo mkdir -p "${btrfs_path}".Snapshot/
I am also using very frequently mlocate (updatedb) so to avoid having multiple (duplicates) in your index, do not forget to update updatedb.conf to exclude the snapshot directories.
PRUNENAMES = ".Snapshot"How many snapshots are there?
Yes, how many ?
In order to learn this, we need to count them. I will try to skip every other subvolume that exist under the path and count only the read-only, snapshots under each partition.
sudo btrfs subvolume list -o -r -s "${btrfs_path}" | grep -c ".Snapshot/"
Delete Previous snapshots
At this point in the script, we are ready to delete all previous snapshots and only keep the latest or to be exact whatever the keep_snapshots variables says we should keep.
To do that, we are going to iterate via a while-loop (this is a nested loop inside the above for-loop)
while [ "${keep_snapshots}" -le "${list_btrfs_snap}" ]
do
<some commands>
done
considering that the keep_snapshots is an integer, we iterate the delete command less or equal from the list of already btrfs existing snapshots.
Delete Command
To avoid mistakes, we delete by subvolume id and not by the name of the snapshot, under the btrfs path we listed above.
btrfs subvolume delete --subvolid "${prev_btrfs_snap}" "${btrfs_path}"and we log the output of the command into our log
Delete subvolume (no-commit): '//.Snapshot/20221107_091028'
Create a new subvolume snapshot
And now we are going to create a new read-only snapshot under our btrfs subvolume.
btrfs subvolume snapshot -r "${btrfs_path}" "${btrfs_path}.Snapshot/${timestamp}"
the log entry will have something like:
Create a readonly snapshot of '/' in '/.Snapshot/20221111_000001'
That’s it !
Output
Log Directory Structure and output
sudo tree /var/log/btrfsSnapshot/2022/11/
/var/log/btrfsSnapshot/2022/11/
├── 07
│ └── btrfsSnapshot.log
├── 10
│ └── btrfsSnapshot.log
├── 11
│ └── btrfsSnapshot.log
└── 18
└── btrfsSnapshot.log
4 directories, 4 files
sudo cat /var/log/btrfsSnapshot/2022/11/18/btrfsSnapshot.log
######## Fri, 18 Nov 2022 00:00:01 +0200 ########
Delete subvolume (no-commit): '//.Snapshot/20221107_091040'
Create a readonly snapshot of '/' in '/.Snapshot/20221118_000001'
Delete subvolume (no-commit): '/home//home/.Snapshot/20221107_091040'
Create a readonly snapshot of '/home/' in '/home/.Snapshot/20221118_000001'
Delete subvolume (no-commit): '/opt//opt/.Snapshot/20221107_091040'
Create a readonly snapshot of '/opt/' in '/opt/.Snapshot/20221118_000001'
Mount a read-only subvolume
As something extra for this article, I will mount a read-only subvolume, so you can see how it is done.
$ sudo btrfs subvolume list -o -r -s /
ID 462 gen 5809766 cgen 5809765 top level 5 otime 2022-11-10 18:11:20 path .Snapshot/20221110_181120
ID 463 gen 5810106 cgen 5810105 top level 5 otime 2022-11-11 00:00:01 path .Snapshot/20221111_000001
ID 464 gen 5819886 cgen 5819885 top level 5 otime 2022-11-18 00:00:01 path .Snapshot/20221118_000001
$ sudo mount -o subvolid=462 /media/
mount: /media/: can't find in /etc/fstab.
$ sudo mount -o subvolid=462 LABEL=rootfs /media/
$ df -HP /media/
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/ssd 112G 9.1G 102G 9% /media
$ sudo touch /media/etc/ebal
touch: cannot touch '/media/etc/ebal': Read-only file system
$ sudo diff /etc/pacman.d/mirrorlist /media/etc/pacman.d/mirrorlist
294c294
< Server = http://ftp.ntua.gr/pub/linux/archlinux/$repo/os/$arch
---
> #Server = http://ftp.ntua.gr/pub/linux/archlinux/$repo/os/$arch
$ sudo umount /media
The Script
Last, but not least, the full script as was the date of this article.
#!/bin/bash
set -e
# ebal, Mon, 07 Nov 2022 08:49:37 +0200
## 0 0 * * Fri /usr/local/bin/btrfsSnapshot.sh
# paths MUST end with '/'
btrfs_paths=("/" "/home/" "/opt/")
timestamp=$(date +%Y%m%d_%H%M%S)
keep_snapshots=3
yymmdd="$(date +%Y/%m/%d)"
logfile="/var/log/btrfsSnapshot/${yymmdd}/btrfsSnapshot.log"
sudo mkdir -p "/var/log/btrfsSnapshot/${yymmdd}/"
echo "######## $(date -R) ########" | sudo tee -a "${logfile}"
echo "" | sudo tee -a "${logfile}"
for btrfs_path in "${btrfs_paths[@]}"; do
## Create Snapshot directory
sudo mkdir -p "${btrfs_path}".Snapshot/
## How many Snapshots are there ?
list_btrfs_snap=$(sudo btrfs subvolume list -o -r -s "${btrfs_path}" | grep -c ".Snapshot/")
## Get oldest rootfs btrfs snapshot
while [ "${keep_snapshots}" -le "${list_btrfs_snap}" ]
do
prev_btrfs_snap=$(sudo btrfs subvolume list -o -r -s "${btrfs_path}" | grep ".Snapshot/" | sort | head -1 | awk '{print $2}')
## Delete a btrfs snapshot by their subvolume id
sudo btrfs subvolume delete --subvolid "${prev_btrfs_snap}" "${btrfs_path}" | sudo tee -a "${logfile}"
list_btrfs_snap=$(sudo btrfs subvolume list -o -r -s "${btrfs_path}" | grep -c ".Snapshot/")
done
## Create a new read-only btrfs snapshot
sudo btrfs subvolume snapshot -r "${btrfs_path}" "${btrfs_path}.Snapshot/${timestamp}" | sudo tee -a "${logfile}"
echo "" | sudo tee -a "${logfile}"
done
When creating a new Cloud Virtual Machine the cloud provider is copying a virtual disk as the base image (we called it mí̱tra or matrix) and starts your virtual machine from another virtual disk (or volume cloud disk) that in fact is a snapshot of the base image.
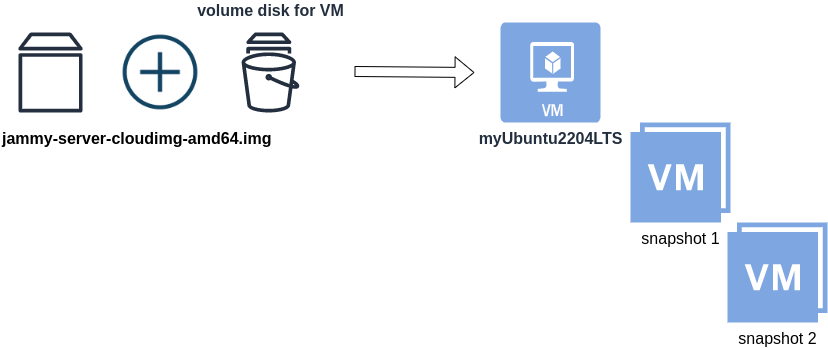
Just for the sake of this example, let us say that the base cloud image is the
jammy-server-cloudimg-amd64.imgWhen creating a new Libvirt (qemu/kvm) virtual machine, you can use this base image to start your VM instead of using an iso to install ubuntu 22.04 LTS. When choosing this image, then all changes will occur to that image and if you want to spawn another virtual machine, you need to (re)download it.
So instead of doing that, the best practice is to copy this image as base and start from a snapshot aka a baking file from that image. It is best because you can always quickly revert all your changes and (re)spawn the VM from the fresh/clean base image. Or you can always create another snapshot and revert if needed.
inspect images
To see how that works here is a local example from my linux machine.
qemu-img info /var/lib/libvirt/images/lEvXLA_tf-base.qcow2
image: /var/lib/libvirt/images/lEvXLA_tf-base.qcow2
file format: qcow2
virtual size: 2.2 GiB (2361393152 bytes)
disk size: 636 MiB
cluster_size: 65536
Format specific information:
compat: 0.10
compression type: zlib
refcount bits: 16the most important attributes to inspect are
virtual size: 2.2 GiB
disk size: 636 MiB
and the volume disk of my virtual machine
qemu-img info /var/lib/libvirt/images/lEvXLA_tf-vol.qcow2
image: /var/lib/libvirt/images/lEvXLA_tf-vol.qcow2
file format: qcow2
virtual size: 10 GiB (10737418240 bytes)
disk size: 1.6 GiB
cluster_size: 65536
backing file: /var/lib/libvirt/images/lEvXLA_tf-base.qcow2
backing file format: qcow2
Format specific information:
compat: 0.10
compression type: zlib
refcount bits: 16
We see here
virtual size: 10 GiB
disk size: 1.6 GiB
cause I have extended the volume disk size to 10G from 2.2G , doing some updates and install some packages.
Now here is a problem.
I would like to use my own cloud image as base for some projects. It will help me speed things up and also do some common things I am usually doing in every setup.
If I copy the volume disk, then I will copy 1.6G of the snapshot disk. I can not use this as a base image. The volume disk contains only the delta from the base image!
baking file
Let’s first understand a bit better what is happening here
qemu-img info –backing-chain /var/lib/libvirt/images/lEvXLA_tf-vol.qcow2
image: /var/lib/libvirt/images/lEvXLA_tf-vol.qcow2
file format: qcow2
virtual size: 10 GiB (10737418240 bytes)
disk size: 1.6 GiB
cluster_size: 65536
backing file: /var/lib/libvirt/images/lEvXLA_tf-base.qcow2
backing file format: qcow2
Format specific information:
compat: 0.10
compression type: zlib
refcount bits: 16
image: /var/lib/libvirt/images/lEvXLA_tf-base.qcow2
file format: qcow2
virtual size: 2.2 GiB (2361393152 bytes)
disk size: 636 MiB
cluster_size: 65536
Format specific information:
compat: 0.10
compression type: zlib
refcount bits: 16
By inspecting the volume disk, we see that this image is chained to our base image.
disk size: 1.6 GiB
disk size: 636 MiB
Commit Volume
If we want to commit our volume changes to our base images, we need to commit them.
sudo qemu-img commit /var/lib/libvirt/images/lEvXLA_tf-vol.qcow2
Image committed.
Be aware, we commit our changes the volume disk => so our base will get the updates !!
Base Image
We need to see our base image grow we our changes
disk size: 1.6 GiB
+ disk size: 636 MiB
=
disk size: 2.11 GiBand we can verify that by getting the image info (details)
qemu-img info /var/lib/libvirt/images/lEvXLA_tf-base.qcow2
image: /var/lib/libvirt/images/lEvXLA_tf-base.qcow2
file format: qcow2
virtual size: 10 GiB (10737418240 bytes)
disk size: 2.11 GiB
cluster_size: 65536
Format specific information:
compat: 0.10
compression type: zlib
refcount bits: 16
That’s it !
Using Terraform for personal projects, is a good way to create your lab in a reproducible manner. Wherever your lab is, either in the “cloud” aka other’s people computers or in a self-hosted environment, you can run your Infrastructure as code (IaC) instead of performing manual tasks each time.
My preferable way is to use QEMU/KVM (Kernel Virtual Machine) on my libvirt (self-hosted) lab. You can quickly build a k8s cluster or test a few virtual machines with different software, without paying extra money to cloud providers.
Terraform uses a state file to store your entire infra in json format. This file will be the source of truth for your infrastructure. Any changes you make in the code, terraform will figure out what needs to add/destroy and run only what have changed.
Working in a single repository, terraform will create a local state file on your working directory. This is fast and reliable when working alone. When working with a team (either in an opensource project/service or it is something work related) you need to share the state with others. Eitherwise the result will be catastrophic as each person will have no idea of the infrastructure state of the service.
In this blog post, I will try to explain how to use GitLab to store the terraform state into a remote repository by using the tf backend: http which is REST.
Greate a new private GitLab Project
We need the Project ID which is under the project name in the top.
Create a new api token
Verify that your Project has the ability to store terraform state files
You are ready to clone the git repository to your system.
Backend
Reading the documentation in the below links
seems that the only thing we need to do, is to expand our terraform project with this:
terraform {
backend "http" {
}
}
Doing that, we inform our IaC that our terraform backend should be a remote address.
Took me a while to figure this out, but after re-reading all the necessary documentation materials the idea is to declare your backend on gitlab and to do this, we need to initialize the http backend.
The only Required configuration setting is the remote address and should be something like this:
terraform {
backend "http" {
address = "https://gitlab.com/api/v4/projects/<PROJECT_ID>/terraform/state/<STATE_NAME>"
}
}
Where PROJECT_ID and STATE_NAME are relative to your project.
In this article, we go with
GITLAB_PROJECT_ID="40961586"
GITLAB_TF_STATE_NAME="tf_state"Terraform does not allow to use variables in the backend http, so the preferable way is to export them to our session.
and we -of course- need the address:
TF_HTTP_ADDRESS="https://gitlab.com/api/v4/projects/${GITLAB_PROJECT_ID}/terraform/state/${GITLAB_TF_STATE_NAME}"
For convience reasons, I will create a file named: terraform.config outside of this git repo
cat > ../terraform.config <<EOF
export -p GITLAB_PROJECT_ID="40961586"
export -p GITLAB_TF_STATE_NAME="tf_state"
export -p GITLAB_URL="https://gitlab.com/api/v4/projects"
# Address
export -p TF_HTTP_ADDRESS="${GITLAB_URL}/${GITLAB_PROJECT_ID}/terraform/state/${GITLAB_TF_STATE_NAME}"
EOF
source ../terraform.config
this should do the trick.
Authentication
In order to authenticate via tf against GitLab to store the tf remote state, we need to also set two additional variables:
# Authentication
TF_HTTP_USERNAME="api"
TF_HTTP_PASSWORD="<TOKEN>"
put them in the above terraform.config file.
Pretty much we are done!
Initialize Terraform
source ../terraform.config
terraform init
Initializing the backend...
Successfully configured the backend "http"! Terraform will automatically
use this backend unless the backend configuration changes.
Initializing provider plugins...
- Finding latest version of hashicorp/http...
- Finding latest version of hashicorp/random...
- Finding latest version of hashicorp/template...
- Finding dmacvicar/libvirt versions matching ">= 0.7.0"...
- Installing hashicorp/random v3.4.3...
- Installed hashicorp/random v3.4.3 (signed by HashiCorp)
- Installing hashicorp/template v2.2.0...
- Installed hashicorp/template v2.2.0 (signed by HashiCorp)
- Installing dmacvicar/libvirt v0.7.0...
- Installed dmacvicar/libvirt v0.7.0 (unauthenticated)
- Installing hashicorp/http v3.2.1...
- Installed hashicorp/http v3.2.1 (signed by HashiCorp)
Terraform has created a lock file .terraform.lock.hcl to record the provider
selections it made above. Include this file in your version control repository
so that Terraform can guarantee to make the same selections by default when
you run "terraform init" in the future.
...
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
Remote state
by running
terraform plan
we can now see the remote terraform state in the gitlab
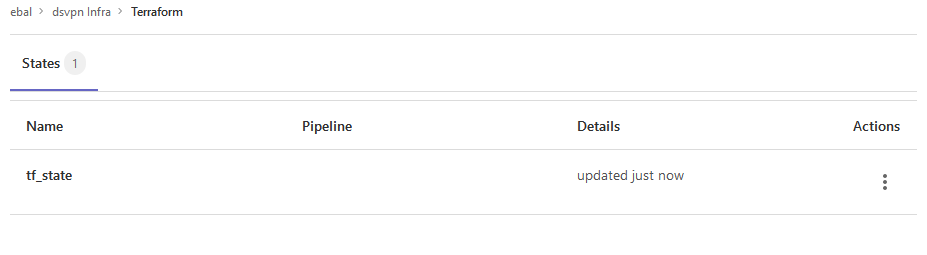
Opening Actions –> Copy terraform init command we can see the below configuration:
export GITLAB_ACCESS_TOKEN=<YOUR-ACCESS-TOKEN>
terraform init
-backend-config="address=https://gitlab.com/api/v4/projects/40961586/terraform/state/tf_state"
-backend-config="lock_address=https://gitlab.com/api/v4/projects/40961586/terraform/state/tf_state/lock"
-backend-config="unlock_address=https://gitlab.com/api/v4/projects/40961586/terraform/state/tf_state/lock"
-backend-config="username=api"
-backend-config="password=$GITLAB_ACCESS_TOKEN"
-backend-config="lock_method=POST"
-backend-config="unlock_method=DELETE"
-backend-config="retry_wait_min=5"
Update terraform backend configuration
I dislike running a “long” terraform init command, so we will put these settings to our tf code.
Separating the static changes from the dynamic, our Backend http config can become something like this:
terraform {
backend "http" {
lock_method = "POST"
unlock_method = "DELETE"
retry_wait_min = 5
}
}
but we need to update our terraform.config once more, to include all the variables of the http backend configuration for locking and unlocking the state.
# Lock
export -p TF_HTTP_LOCK_ADDRESS="${TF_HTTP_ADDRESS}/lock"
# Unlock
export -p TF_HTTP_UNLOCK_ADDRESS="${TF_HTTP_ADDRESS}/lock"Terraform Config
So here is our entire terraform config file
# GitLab
export -p GITLAB_URL="https://gitlab.com/api/v4/projects"
export -p GITLAB_PROJECT_ID="<>"
export -p GITLAB_TF_STATE_NAME="tf_state"
# Terraform
# Address
export -p TF_HTTP_ADDRESS="${GITLAB_URL}/${GITLAB_PROJECT_ID}/terraform/state/${GITLAB_TF_STATE_NAME}"
# Lock
export -p TF_HTTP_LOCK_ADDRESS="${TF_HTTP_ADDRESS}/lock"
# Unlock
export -p TF_HTTP_UNLOCK_ADDRESS="${TF_HTTP_ADDRESS}/lock"
# Authentication
export -p TF_HTTP_USERNAME="api"
export -p TF_HTTP_PASSWORD="<>"
And pretty much that’s it!
Other Colleagues
So in order our team mates/colleagues want to make changes to this specific gitlab repo (or even extended to include a pipeline) they need
- Git clone the repo
- Edit the terraform.config
- Initialize terraform (terraform init)
And terraform will use the remote state file.
In the last few months of this year, a business question exists in all our minds:
-Can we reduce Cost ?
-Are there any legacy cloud resources that we can remove ?
The answer is YES, it is always Yes. It is part of your Technical Debt (remember that?).
In our case we had to check a few cloud resources, but the most impressive were our Object Storage Service that in the past we were using Buckets and Objects as backup volumes … for databases … database clusters!!
So let’s find out what is our Techinical Debt in our OBS … ~ 1.8PB . One petabyte holds 1000 terabytes (TB), One terabyte holds 1000 gigabytes (GB).
We have confirmed with our colleagues and scheduled the decomissions of these legacy buckets/objects. We’ve noticed that a few of them are in TB sizes with million of objects and in some cases with not a hierarchy structure (paths) so there is an issue with command line tools or web UI tools.
The problem is called LISTING and/or PAGING.
That means we can not list in a POSIX way (nerdsssss) all our objects so we can try delete them. We need to PAGE them in 50 or 100 objects and that means we need to batch our scripts. This could be a very long/time based job.
Then after a couple days of reading manuals (remember these ?), I found that we can create a Lifecycle Policy to our Buckets !!!
But before going on to setup the Lifecycle policy, just a quick reminder how the Object Lifecycle works
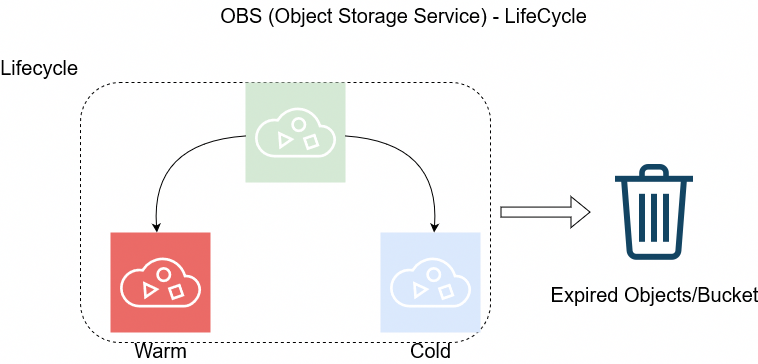
The objects can be in Warm/Cold or in Expired State as buckets support versioning. This has to do with the retention policy of logs/data.
So in order to automatically delete ALL objects from a bucket, we need to setup up the Expire Time to 1 day.
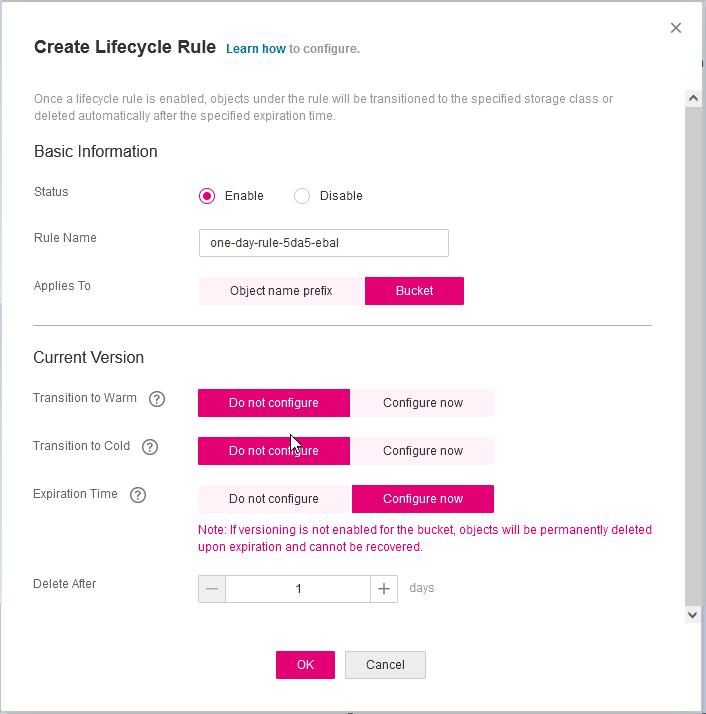
Then you have to wait for 24h and next day
yehhhhhhhhhhhh !
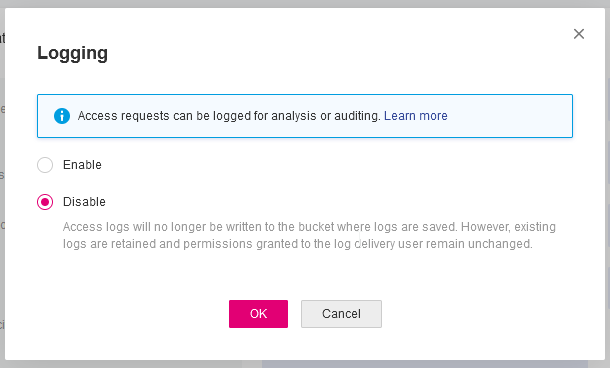
PS. Caveat Remember BEFORE all that, do disable Logging as the default setting is to log every action to a local log path, inside the Bucket.
In this blog post, I’ll try to share my personal notes on how to setup a kubernetes cluster with kubeadm on ubuntu 22.04 LTS Virtual Machines.
I am going to use three (3) Virtual Machines in my local lab. My home lab is based on libvirt Qemu/KVM (Kernel-based Virtual Machine) and I run Terraform as the infrastructure provision tool.
There is a copy of this blog post to github.
https://github.com/ebal/k8s_cluster
If you notice something wrong you can either contact me via the contact page, or open a PR in the github project.
you can also follow me at twitter: https://twitter.com/ebalaskas
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.
- Prerequisites
- Git Terraform Code for the kubernetes cluster
- Control-Plane Node
- Ports on the control-plane node
- Firewall on the control-plane node
- Hosts file in the control-plane node
- No Swap on the control-plane node
- Kernel modules on the control-plane node
- NeedRestart on the control-plane node
- Installing a Container Runtime on the control-plane node
- Installing kubeadm, kubelet and kubectl on the control-plane node
- Initializing the control-plane node
- Create user access config to the k8s control-plane node
- Verify the control-plane node
- Install an overlay network provider on the control-plane node
- Verify CoreDNS is running on the control-plane node
- Worker Nodes
- Ports on the worker nodes
- Firewall on the worker nodes
- Hosts file in the worker node
- No Swap on the worker node
- Kernel modules on the worker node
- NeedRestart on the worker node
- Installing a Container Runtime on the worker node
- Installing kubeadm, kubelet and kubectl on the worker node
- Get Token from the control-plane node
- Get Certificate Hash from the control-plane node
- Join Workers to the kubernetes cluster
- Is the kubernetes cluster running ?
- Kubernetes Dashboard
- Install kubernetes dashboard
- Add a Node Port to kubernetes dashboard
- Patch kubernetes-dashboard
- Edit kubernetes-dashboard Service
- Accessing Kubernetes Dashboard
- Create An Authentication Token (RBAC)
- Creating a Service Account
- Creating a ClusterRoleBinding
- Getting a Bearer Token
- Browsing Kubernetes Dashboard
- Nginx App
- That’s it !
Prerequisites
- at least 3 Virtual Machines of Ubuntu 22.04 (one for control-plane, two for worker nodes)
- 2GB (or more) of RAM on each Virtual Machine
- 2 CPUs (or more) on each Virtual Machine
- 20Gb of hard disk on each Virtual Machine
- No SWAP partition/image/file on each Virtual Machine
Git Terraform Code for the kubernetes cluster
I prefer to have a reproducible infrastructure, so I can very fast create and destroy my test lab. My preferable way of doing things is testing on each step, so I pretty much destroy everything, coping and pasting commands and keep on. I use terraform for the create the infrastructure. You can find the code for the entire kubernetes cluster here: k8s cluster - Terraform code.
If you do not use terraform, skip this step!
You can git clone the repo to review and edit it according to your needs.
git clone https://github.com/ebal/k8s_cluster.git
cd tf_libvirt
You will need to make appropriate changes. Open Variables.tf for that. The most important option to change, is the User option. Change it to your github username and it will download and setup the VMs with your public key, instead of mine!
But pretty much, everything else should work out of the box. Change the vmem and vcpu settings to your needs.
Init terraform before running the below shell script.
terraform init
and then run
./start.sh
output should be something like:
...
Apply complete! Resources: 16 added, 0 changed, 0 destroyed.
Outputs:
VMs = [
"192.168.122.169 k8scpnode",
"192.168.122.40 k8wrknode1",
"192.168.122.8 k8wrknode2",
]
Verify that you have ssh access to the VMs
eg.
ssh -l ubuntu 192.168.122.169
replace the IP with what the output gave you.
Ubuntu 22.04 Image
If you noticed in the terraform code, I have the below declaration as the cloud image:
../jammy-server-cloudimg-amd64.img
that means, I’ve already downloaded it, in the upper directory to speed things up!
cd ../
curl -sLO https://cloud-images.ubuntu.com/jammy/current/focal-server-cloudimg-amd64.img
cd -
Control-Plane Node
Let’s us now start the configure of the k8s control-plane node.
Ports on the control-plane node
Kubernetes runs a few services that needs to be accessable from the worker nodes.
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 6443 | Kubernetes API server | All |
| TCP | Inbound | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | Inbound | 10250 | Kubelet API | Self, Control plane |
| TCP | Inbound | 10259 | kube-scheduler | Self |
| TCP | Inbound | 10257 | kube-controller-manager | Self |
Although etcd ports are included in control plane section, you can also host your
own etcd cluster externally or on custom ports.
Firewall on the control-plane node
We need to open the necessary ports on the CP’s (control-plane node) firewall.
sudo ufw allow 6443/tcp
sudo ufw allow 2379:2380/tcp
sudo ufw allow 10250/tcp
sudo ufw allow 10259/tcp
sudo ufw allow 10257/tcp
#sudo ufw disable
sudo ufw status
the output should be
To Action From
-- ------ ----
22/tcp ALLOW Anywhere
6443/tcp ALLOW Anywhere
2379:2380/tcp ALLOW Anywhere
10250/tcp ALLOW Anywhere
10259/tcp ALLOW Anywhere
10257/tcp ALLOW Anywhere
22/tcp (v6) ALLOW Anywhere (v6)
6443/tcp (v6) ALLOW Anywhere (v6)
2379:2380/tcp (v6) ALLOW Anywhere (v6)
10250/tcp (v6) ALLOW Anywhere (v6)
10259/tcp (v6) ALLOW Anywhere (v6)
10257/tcp (v6) ALLOW Anywhere (v6)
Hosts file in the control-plane node
We need to update the /etc/hosts with the internal IP and hostname.
This will help when it is time to join the worker nodes.
echo $(hostname -I) $(hostname) | sudo tee -a /etc/hosts
Just a reminder: we need to update the hosts file to all the VMs.
To include all the VMs’ IPs and hostnames.
If you already know them, then your /etc/hosts file should look like this:
192.168.122.169 k8scpnode
192.168.122.40 k8wrknode1
192.168.122.8 k8wrknode2
replace the IPs to yours.
No Swap on the control-plane node
Be sure that SWAP is disabled in all virtual machines!
sudo swapoff -a
and the fstab file should not have any swap entry.
The below command should return nothing.
sudo grep -i swap /etc/fstab
If not, edit the /etc/fstab and remove the swap entry.
If you follow my terraform k8s code example from the above github repo,
you will notice that there isn’t any swap entry in the cloud init (user-data) file.
Nevertheless it is always a good thing to douple check.
Kernel modules on the control-plane node
We need to load the below kernel modules on all k8s nodes, so k8s can create some network magic!
- overlay
- br_netfilter
Run the below bash snippet that will do that, and also will enable the forwarding features of the network.
sudo tee /etc/modules-load.d/kubernetes.conf <<EOF
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
sudo lsmod | grep netfilter
sudo tee /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
NeedRestart on the control-plane node
Before installing any software, we need to make a tiny change to needrestart program. This will help with the automation of installing packages and will stop asking -via dialog- if we would like to restart the services!
echo "\$nrconf{restart} = 'a';" | sudo tee -a /etc/needrestart/needrestart.conf
Installing a Container Runtime on the control-plane node
It is time to choose which container runtime we are going to use on our k8s cluster. There are a few container runtimes for k8s and in the past docker were used to. Nowadays the most common runtime is the containerd that can also uses the cgroup v2 kernel features. There is also a docker-engine runtime via CRI. Read here for more details on the subject.
curl -sL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/docker-keyring.gpg
sudo apt-add-repository -y "deb https://download.docker.com/linux/ubuntu jammy stable"
sleep 5
sudo apt -y install containerd.io
containerd config default \
| sed 's/SystemdCgroup = false/SystemdCgroup = true/' \
| sudo tee /etc/containerd/config.toml
sudo systemctl restart containerd.service
We have also enabled the
systemd cgroup driverso the control-plane node can use the cgroup v2 features.
Installing kubeadm, kubelet and kubectl on the control-plane node
Install the kubernetes packages (kubedam, kubelet and kubectl) by first adding the k8s repository on our virtual machine. To speed up the next step, we will also download the configuration container images.
sudo curl -sLo /etc/apt/trusted.gpg.d/kubernetes-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
sudo apt-add-repository -y "deb http://apt.kubernetes.io/ kubernetes-xenial main"
sleep 5
sudo apt install -y kubelet kubeadm kubectl
sudo kubeadm config images pull
Initializing the control-plane node
We can now initialize our control-plane node for our kubernetes cluster.
There are a few things we need to be careful about:
- We can specify the control-plane-endpoint if we are planning to have a high available k8s cluster. (we will skip this for now),
- Choose a Pod network add-on (next section) but be aware that CoreDNS (DNS and Service Discovery) will not run till then (later),
- define where is our container runtime socket (we will skip it)
- advertise the API server (we will skip it)
But we will define our Pod Network CIDR to the default value of the Pod network add-on so everything will go smoothly later on.
sudo kubeadm init --pod-network-cidr=10.244.0.0/16
Keep the output in a notepad.
Create user access config to the k8s control-plane node
Our k8s control-plane node is running, so we need to have credentials to access it.
The kubectl reads a configuration file (that has the token), so we copying this from k8s admin.
rm -rf $HOME/.kube
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
ls -la $HOME/.kube/config
alias k="kubectl"
Verify the control-plane node
Verify that the kubernets is running.
That means we have a k8s cluster - but only the control-plane node is running.
kubectl cluster-info
#kubectl cluster-info dump
k get nodes -o wide; k get pods -A -o wide
Install an overlay network provider on the control-plane node
As I mentioned above, in order to use the DNS and Service Discovery services in the kubernetes (CoreDNS) we need to install a Container Network Interface (CNI) based Pod network add-on so that your Pods can communicate with each other.
We will use flannel as the simplest of them.
k apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
Verify CoreDNS is running on the control-plane node
Verify that the control-plane node is Up & Running and the control-plane pods (as coredns pods) are also running
$ k get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8scpnode Ready control-plane 54s v1.25.0 192.168.122.169 <none> Ubuntu 22.04.1 LTS 5.15.0-46-generic containerd://1.6.8
$ k get pods -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-flannel kube-flannel-ds-zqv2b 1/1 Running 0 36s 192.168.122.169 k8scpnode <none> <none>
kube-system coredns-565d847f94-lg54q 1/1 Running 0 38s 10.244.0.2 k8scpnode <none> <none>
kube-system coredns-565d847f94-ms8zk 1/1 Running 0 38s 10.244.0.3 k8scpnode <none> <none>
kube-system etcd-k8scpnode 1/1 Running 0 50s 192.168.122.169 k8scpnode <none> <none>
kube-system kube-apiserver-k8scpnode 1/1 Running 0 50s 192.168.122.169 k8scpnode <none> <none>
kube-system kube-controller-manager-k8scpnode 1/1 Running 0 50s 192.168.122.169 k8scpnode <none> <none>
kube-system kube-proxy-pv7tj 1/1 Running 0 39s 192.168.122.169 k8scpnode <none> <none>
kube-system kube-scheduler-k8scpnode 1/1 Running 0 50s 192.168.122.169 k8scpnode <none> <none>
That’s it with the control-plane node !
Worker Nodes
The below instructions works pretty much the same on both worker nodes.
I will document the steps for the worker1 node but do the same for the worker2 node.
Ports on the worker nodes
As we learned above on the control-plane section, kubernetes runs a few services
| Protocol | Direction | Port Range | Purpose | Used By |
|---|---|---|---|---|
| TCP | Inbound | 10250 | Kubelet API | Self, Control plane |
| TCP | Inbound | 30000-32767 | NodePort Services | All |
Firewall on the worker nodes
so we need to open the necessary ports on the worker nodes too.
sudo ufw allow 10250/tcp
sudo ufw allow 30000:32767/tcp
sudo ufw status
output should look like
To Action From
-- ------ ----
22/tcp ALLOW Anywhere
10250/tcp ALLOW Anywhere
30000:32767/tcp ALLOW Anywhere
22/tcp (v6) ALLOW Anywhere (v6)
10250/tcp (v6) ALLOW Anywhere (v6)
30000:32767/tcp (v6) ALLOW Anywhere (v6)
The next few steps are pretty much exactly the same as in the control-plane node.
In order to keep this documentation short, I’ll just copy/paste the commands.
Hosts file in the worker node
Update the /etc/hosts file to include the IPs and hostname of all VMs.
192.168.122.169 k8scpnode
192.168.122.40 k8wrknode1
192.168.122.8 k8wrknode2
No Swap on the worker node
sudo swapoff -a
Kernel modules on the worker node
sudo tee /etc/modules-load.d/kubernetes.conf <<EOF
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
sudo lsmod | grep netfilter
sudo tee /etc/sysctl.d/kubernetes.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
NeedRestart on the worker node
echo "\$nrconf{restart} = 'a';" | sudo tee -a /etc/needrestart/needrestart.conf
Installing a Container Runtime on the worker node
curl -sL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/docker-keyring.gpg
sudo apt-add-repository -y "deb https://download.docker.com/linux/ubuntu jammy stable"
sleep 5
sudo apt -y install containerd.io
containerd config default \
| sed 's/SystemdCgroup = false/SystemdCgroup = true/' \
| sudo tee /etc/containerd/config.toml
sudo systemctl restart containerd.service
Installing kubeadm, kubelet and kubectl on the worker node
sudo curl -sLo /etc/apt/trusted.gpg.d/kubernetes-keyring.gpg https://packages.cloud.google.com/apt/doc/apt-key.gpg
sudo apt-add-repository -y "deb http://apt.kubernetes.io/ kubernetes-xenial main"
sleep 5
sudo apt install -y kubelet kubeadm kubectl
sudo kubeadm config images pull
Get Token from the control-plane node
To join nodes to the kubernetes cluster, we need to have a couple of things.
- a token from control-plane node
- the CA certificate hash from the contol-plane node.
If you didnt keep the output the initialization of the control-plane node, that’s okay.
Run the below command in the control-plane node.
sudo kubeadm token list
and we will get the initial token that expires after 24hours.
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
zt36bp.uht4cziweef1jo1h 23h 2022-08-31T18:38:16Z authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
In this case is the
zt36bp.uht4cziweef1jo1hGet Certificate Hash from the control-plane node
To get the CA certificate hash from the control-plane-node, we need to run a complicated command:
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
and in my k8s cluster is:
a4833f8c82953370610efaa5ed93b791337232c3a948b710b2435d747889c085Join Workers to the kubernetes cluster
So now, we can Join our worker nodes to the kubernetes cluster.
Run the below command on both worker nodes:
sudo kubeadm join 192.168.122.169:6443 \
--token zt36bp.uht4cziweef1jo1h \
--discovery-token-ca-cert-hash sha256:a4833f8c82953370610efaa5ed93b791337232c3a948b710b2435d747889c085
we get this message
Run ‘kubectl get nodes’ on the control-plane to see this node join the cluster.
Is the kubernetes cluster running ?
We can verify that
kubectl get nodes -o wide
kubectl get pods -A -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8scpnode Ready control-plane 64m v1.25.0 192.168.122.169 <none> Ubuntu 22.04.1 LTS 5.15.0-46-generic containerd://1.6.8
k8wrknode1 Ready <none> 2m32s v1.25.0 192.168.122.40 <none> Ubuntu 22.04.1 LTS 5.15.0-46-generic containerd://1.6.8
k8wrknode2 Ready <none> 2m28s v1.25.0 192.168.122.8 <none> Ubuntu 22.04.1 LTS 5.15.0-46-generic containerd://1.6.8NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-flannel kube-flannel-ds-52g92 1/1 Running 0 2m32s 192.168.122.40 k8wrknode1 <none> <none>
kube-flannel kube-flannel-ds-7qlm7 1/1 Running 0 2m28s 192.168.122.8 k8wrknode2 <none> <none>
kube-flannel kube-flannel-ds-zqv2b 1/1 Running 0 64m 192.168.122.169 k8scpnode <none> <none>
kube-system coredns-565d847f94-lg54q 1/1 Running 0 64m 10.244.0.2 k8scpnode <none> <none>
kube-system coredns-565d847f94-ms8zk 1/1 Running 0 64m 10.244.0.3 k8scpnode <none> <none>
kube-system etcd-k8scpnode 1/1 Running 0 64m 192.168.122.169 k8scpnode <none> <none>
kube-system kube-apiserver-k8scpnode 1/1 Running 0 64m 192.168.122.169 k8scpnode <none> <none>
kube-system kube-controller-manager-k8scpnode 1/1 Running 1 (12m ago) 64m 192.168.122.169 k8scpnode <none> <none>
kube-system kube-proxy-4khw6 1/1 Running 0 2m32s 192.168.122.40 k8wrknode1 <none> <none>
kube-system kube-proxy-gm27l 1/1 Running 0 2m28s 192.168.122.8 k8wrknode2 <none> <none>
kube-system kube-proxy-pv7tj 1/1 Running 0 64m 192.168.122.169 k8scpnode <none> <none>
kube-system kube-scheduler-k8scpnode 1/1 Running 1 (12m ago) 64m 192.168.122.169 k8scpnode <none> <none>
That’s it !
Our k8s cluster is running.
Kubernetes Dashboard
is a general purpose, web-based UI for Kubernetes clusters. It allows users to manage applications running in the cluster and troubleshoot them, as well as manage the cluster itself.
We can proceed by installing a k8s dashboard to our k8s cluster.
Install kubernetes dashboard
One simple way to install the kubernetes-dashboard, is by applying the latest (as of this writing) yaml configuration file.
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.6.1/aio/deploy/recommended.yaml
the output of the above command should be something like
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
Verify the installation
kubectl get all -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/dashboard-metrics-scraper-64bcc67c9c-kvll7 1/1 Running 0 2m16s
pod/kubernetes-dashboard-66c887f759-rr4gn 1/1 Running 0 2m16s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/dashboard-metrics-scraper ClusterIP 10.110.25.61 <none> 8000/TCP 2m16s
service/kubernetes-dashboard ClusterIP 10.100.65.122 <none> 443/TCP 2m16s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/dashboard-metrics-scraper 1/1 1 1 2m16s
deployment.apps/kubernetes-dashboard 1/1 1 1 2m16s
NAME DESIRED CURRENT READY AGE
replicaset.apps/dashboard-metrics-scraper-64bcc67c9c 1 1 1 2m16s
replicaset.apps/kubernetes-dashboard-66c887f759 1 1 1 2m16s
Add a Node Port to kubernetes dashboard
Kubernetes Dashboard by default runs on a internal 10.x.x.x IP.
To access the dashboard we need to have a NodePort in the kubernetes-dashboard service.
We can either Patch the service or edit the yaml file.
Patch kubernetes-dashboard
kubectl --namespace kubernetes-dashboard patch svc kubernetes-dashboard -p '{"spec": {"type": "NodePort"}}'
output
service/kubernetes-dashboard patched
verify the service
kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.110.25.61 <none> 8000/TCP 11m
kubernetes-dashboard NodePort 10.100.65.122 <none> 443:32709/TCP 11m
we can see the 30480 in the kubernetes-dashboard.
Edit kubernetes-dashboard Service
kubectl edit svc -n kubernetes-dashboard kubernetes-dashboard
and chaning the service type from
type: ClusterIPto
type: NodePortAccessing Kubernetes Dashboard
The kubernetes-dashboard has two (2) pods, one (1) for metrics, one (2) for the dashboard.
To access the dashboard, first we need to identify in which Node is running.
kubectl get pods -n kubernetes-dashboard -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
dashboard-metrics-scraper-64bcc67c9c-fs7pt 1/1 Running 0 2m43s 10.244.1.9 k8wrknode1 <none> <none>
kubernetes-dashboard-66c887f759-pzt4z 1/1 Running 0 2m44s 10.244.2.9 k8wrknode2 <none> <none>
In my setup the dashboard pod is running on the worker node 2 and from the /etc/hosts is on the 192.168.122.8 IP.
The NodePort is 32709
k get svc -n kubernetes-dashboard -o wide
So, we can open a new tab on our browser and type:
https://192.168.122.8:32709
and accept the self-signed certificate!
Create An Authentication Token (RBAC)
Last step for the kubernetes-dashboard is to create an authentication token.
Creating a Service Account
Create a new yaml file, with kind: ServiceAccount that has access to kubernetes-dashboard namespace and has name: admin-user.
cat > kubernetes-dashboard.ServiceAccount.yaml <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
EOF
add this service account to the k8s cluster
kubectl apply -f kubernetes-dashboard.ServiceAccount.yaml
output
serviceaccount/admin-user createdCreating a ClusterRoleBinding
We need to bind the Service Account with the kubernetes-dashboard via Role-based access control.
cat > kubernetes-dashboard.ClusterRoleBinding.yaml <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
apply this yaml file
kubectl apply -f kubernetes-dashboard.ClusterRoleBinding.yaml
clusterrolebinding.rbac.authorization.k8s.io/admin-user created
That means, our Service Account User has all the necessary roles to access the kubernetes-dashboard.
Getting a Bearer Token
Final step is to create/get a token for our user.
kubectl -n kubernetes-dashboard create token admin-user
eyJhbGciOiJSUzI1NiIsImtpZCI6Im04M2JOY2k1Yk1hbFBhLVN2cjA4X1pkdktXNldqWkR4bjB6MGpTdFgtVHcifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNjYxOTU2NDQ1LCJpYXQiOjE2NjE5NTI4NDUsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJhZG1pbi11c2VyIiwidWlkIjoiN2M4OWIyZDktMGIwYS00ZDg4LTk2Y2EtZDU3NjhjOWU2ZGYxIn19LCJuYmYiOjE2NjE5NTI4NDUsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDphZG1pbi11c2VyIn0.RMRQkZZhcoC5vCvck6hKfqXJ4dfN4JoQyAaClHZvOMI6JgQZEfB2-_Qsh5MfFApJUEit-0TX9r3CzW3JqvB7dmpTPxUQvHK68r82WGveBVp1wF37UyXu_IzxiCQzpCWYr3GcVGAGZVBbhhqNYm765FV02ZA_khHrW3WpB80ikhm_TNLkOS6Llq2UiLFZyHHmjl5pwvGzT7YXZe8s-llZSgc0UenEwPG-82eE279oOy6r4_NltoV1HB3uu0YjUJPlkqAPnHuSfAA7-8A3XAAVHhRQvFPea1qZLc4-oD24AcU0FjWqDMILEyE8zaD2ci8zEQBMoxcf2qmj0wn9cfbZwQ
Add this token to the previous login page
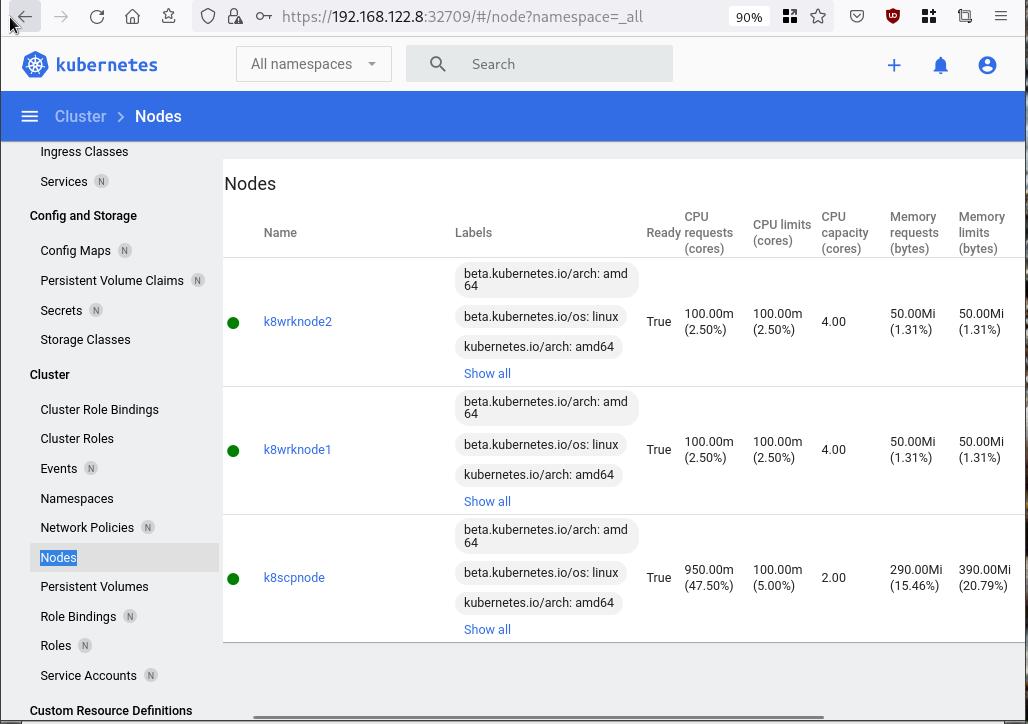
Browsing Kubernetes Dashboard
eg. Cluster –> Nodes
Nginx App
Before finishing this blog post, I would also like to share how to install a simple nginx-app as it is customary to do such thing in every new k8s cluster.
But plz excuse me, I will not get into much details.
You should be able to understand the below k8s commands.
Install nginx-app
kubectl create deployment nginx-app --image=nginx --replicas=2
deployment.apps/nginx-app createdGet Deployment
kubectl get deployment nginx-app -o wideNAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
nginx-app 2/2 2 2 64s nginx nginx app=nginx-appExpose Nginx-App
kubectl expose deployment nginx-app --type=NodePort --port=80
service/nginx-app exposedVerify Service nginx-app
kubectl get svc nginx-app -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx-app NodePort 10.98.170.185 <none> 80:31761/TCP 27s app=nginx-app
Describe Service nginx-app
kubectl describe svc nginx-app
Name: nginx-app
Namespace: default
Labels: app=nginx-app
Annotations: <none>
Selector: app=nginx-app
Type: NodePort
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.98.170.185
IPs: 10.98.170.185
Port: <unset> 80/TCP
TargetPort: 80/TCP
NodePort: <unset> 31761/TCP
Endpoints: 10.244.1.10:80,10.244.2.10:80
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
Curl Nginx-App
curl http://192.168.122.8:31761
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
Nginx-App from Browser
That’s it !
I hope you enjoyed this blog post.
-ebal
./destroy.sh...
libvirt_domain.domain-ubuntu["k8wrknode1"]: Destroying... [id=446cae2a-ce14-488f-b8e9-f44839091bce]
libvirt_domain.domain-ubuntu["k8scpnode"]: Destroying... [id=51e12abb-b14b-4ab8-b098-c1ce0b4073e3]
time_sleep.wait_for_cloud_init: Destroying... [id=2022-08-30T18:02:06Z]
libvirt_domain.domain-ubuntu["k8wrknode2"]: Destroying... [id=0767fb62-4600-4bc8-a94a-8e10c222b92e]
time_sleep.wait_for_cloud_init: Destruction complete after 0s
libvirt_domain.domain-ubuntu["k8wrknode1"]: Destruction complete after 1s
libvirt_domain.domain-ubuntu["k8scpnode"]: Destruction complete after 1s
libvirt_domain.domain-ubuntu["k8wrknode2"]: Destruction complete after 1s
libvirt_cloudinit_disk.cloud-init["k8wrknode1"]: Destroying... [id=/var/lib/libvirt/images/Jpw2Sg_cloud-init.iso;b8ddfa73-a770-46de-ad16-b0a5a08c8550]
libvirt_cloudinit_disk.cloud-init["k8wrknode2"]: Destroying... [id=/var/lib/libvirt/images/VdUklQ_cloud-init.iso;5511ed7f-a864-4d3f-985a-c4ac07eac233]
libvirt_volume.ubuntu-base["k8scpnode"]: Destroying... [id=/var/lib/libvirt/images/l5Rr1w_ubuntu-base]
libvirt_volume.ubuntu-base["k8wrknode2"]: Destroying... [id=/var/lib/libvirt/images/VdUklQ_ubuntu-base]
libvirt_cloudinit_disk.cloud-init["k8scpnode"]: Destroying... [id=/var/lib/libvirt/images/l5Rr1w_cloud-init.iso;11ef6bb7-a688-4c15-ae33-10690500705f]
libvirt_volume.ubuntu-base["k8wrknode1"]: Destroying... [id=/var/lib/libvirt/images/Jpw2Sg_ubuntu-base]
libvirt_cloudinit_disk.cloud-init["k8wrknode1"]: Destruction complete after 1s
libvirt_volume.ubuntu-base["k8wrknode2"]: Destruction complete after 1s
libvirt_cloudinit_disk.cloud-init["k8scpnode"]: Destruction complete after 1s
libvirt_cloudinit_disk.cloud-init["k8wrknode2"]: Destruction complete after 1s
libvirt_volume.ubuntu-base["k8wrknode1"]: Destruction complete after 1s
libvirt_volume.ubuntu-base["k8scpnode"]: Destruction complete after 2s
libvirt_volume.ubuntu-vol["k8wrknode1"]: Destroying... [id=/var/lib/libvirt/images/Jpw2Sg_ubuntu-vol]
libvirt_volume.ubuntu-vol["k8scpnode"]: Destroying... [id=/var/lib/libvirt/images/l5Rr1w_ubuntu-vol]
libvirt_volume.ubuntu-vol["k8wrknode2"]: Destroying... [id=/var/lib/libvirt/images/VdUklQ_ubuntu-vol]
libvirt_volume.ubuntu-vol["k8scpnode"]: Destruction complete after 0s
libvirt_volume.ubuntu-vol["k8wrknode2"]: Destruction complete after 0s
libvirt_volume.ubuntu-vol["k8wrknode1"]: Destruction complete after 0s
random_id.id["k8scpnode"]: Destroying... [id=l5Rr1w]
random_id.id["k8wrknode2"]: Destroying... [id=VdUklQ]
random_id.id["k8wrknode1"]: Destroying... [id=Jpw2Sg]
random_id.id["k8wrknode2"]: Destruction complete after 0s
random_id.id["k8scpnode"]: Destruction complete after 0s
random_id.id["k8wrknode1"]: Destruction complete after 0s
Destroy complete! Resources: 16 destroyed.
So you build a GitLab project, you created a pipeline and then a scheduler to run every week your pipeline.
And then you realize that you are polluting the internet with deprecated (garbage) things, at some point you have a debug option on, bla bla bla… etc etc.
It is time to clean up your mess!
Create a GitLab API Token
Select scopes: api.
Verify API token
run something like this
export GITLAB_API="glpat-HldkXzyurwBmroAdQCMo"
curl -sL --header "PRIVATE-TOKEN: ${GITLAB_API}" "https://gitlab.com/api/v4/projects?owned=true" | jq .[].path_with_namespace
you should see your projects.
Get your Project ID
create a new bash variable:
export PROJECT="terraform-provider/terraform-provider-hcloud-ci"
and then use the get rest api call
curl -sL --header "PRIVATE-TOKEN: ${GITLAB_API}" "https://gitlab.com/api/v4/projects?owned=true&search=${PROJECT}&search_namespaces=true" | jq -r .[].id
or you can also put the id into a new bash variable:
export ID=$(curl -sL --header "PRIVATE-TOKEN: ${GITLAB_API}" "https://gitlab.com/api/v4/projects?owned=true&search=${PROJECT}&search_namespaces=true" | jq -r .[].id)
View the previous pipelines
curl -sL \
--header "PRIVATE-TOKEN: ${GITLAB_API}" \
https://gitlab.com/api/v4/projects/${ID}/pipelines | jq .
Remove deprecated pipelines
just delete them via the API
curl -sL --header "PRIVATE-TOKEN: ${GITLAB_API}" "https://gitlab.com/api/v4/projects/${ID}/pipelines?per_page=150" \
| jq -r .[].id \
| awk '{print "curl -sL --header \"PRIVATE-TOKEN: ${GITLAB_API}\" --request DELETE https://gitlab.com/api/v4/projects/${ID}/pipelines/"$1}' \
| sh -x
that’s it !
It’s been a while since I got my hands on python and I came across with an interesting issue of an internal check today, when upgrading an old Proxy Virtual Machine.
Certificate Verify Failed
Suddenly the internal python check was reporting
[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:727)Python Version
python version before the upgrade was Python 2.7.12 , now is Python 2.7.17
According to the online python documentation:
Changed in version 2.7.9: cafile, capath, cadefault, and context were added.
So something has changed but in both versions the verification for self-signed CA should have the same behavior!
Going down the rabbit hole, seems the most relevant info is in here PEP-0476 but in both cases you have to import SSL and this is not 100% the case !
Nevertheless the default behavior now is to verify the certificate in HTTPS and that is what we need to do!
urllib2 proxy
One of requirements is to check that the proxy is working. URLLIB2 needs a ProxyHandler to do so.
proxy_url = "http://{proxy}/".format(**cfg)
proxy_handler = urllib2.ProxyHandler({ 'http' : proxy_url })after that, we need to pass the proxy_handler to a build_opener and get the response
opener = urllib2.build_opener(proxy_handler)
response = opener.open(cfg["url"])
return responseThis will check an internal URL through our proxy but it will fail when trying to verify the self-signed certificate.
SSL
To enable SSL functionality to python2 we need to import the ssl module
import sslafter that it is simple a case of creating a SSLContext to open the https url.
To create an SSL Context, there is a useful function for common purposes
ssl.create_default_context(purpose=Purpose.SERVER_AUTH, cafile=None, capath=None, cadata=None)¶In our case we can pass our internal self-signed CA file as an argument
ctx = ssl.create_default_context(cafile="/etc/certs/ca.pem")perfect.
Build an HTTPS handler
As we are using an build_opener to pass the proxy handler, but we also need to create an additional handler for the SSL (transport layer) in urllib2.
handler = urllib2.HTTPSHandler(context=ctx)okay, our handler has the SSL Context with the CA file in place.
Build Opener
it is time to stitch everything together
## Create SSLContext with CA file to pass to handler
ctx = ssl.create_default_context(cafile="/etc/csi.certs/vm2csi/ca.pem")
## Create an HTTPS Handler with our custom SSL Context
handler = urllib2.HTTPSHandler(context=ctx)
## Create a Proxy Handler
proxy_handler = urllib2.ProxyHandler({ 'http' : proxy_url })
## Stitch together the proxy and https handlers to build an opener
opener = urllib2.build_opener(proxy_handler,handler)
## Get the response
response = opener.open(cfg["url"])
return responseand now we have a proper internal check!