I am an archlinux user using Sony WH-1000XM3 bluetooth noise-cancellation headphones. I am also using pulseaudio and it took me a while to switch the bluetooth headphones to HSP/HFP profile so the microphone can work too. Switching the bluetooth profile of your headphones to HeadSet Audio works but it is only monophonic audio and without noise-cancellation and I had to switch to piperwire also. But at least now the microphone works!
I was wondering how distros that by default have already switched to pipewire deal with this situation. So I started a fedora 34 (beta) edition and attached both my bluetooth adapter TP-LINK UB400 v1 and my web camera Logitech HD Webcam C270.
The test should be to open a jitsi meet and a zoom test meeting and verify that my headphones can work without me doing any stranger CLI magic.
tldr; works out of the box !
lsusb
[root@fedora ~]# lsusb
Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub
Bus 001 Device 004: ID 046d:0825 Logitech, Inc. Webcam C270
Bus 001 Device 003: ID 0a12:0001 Cambridge Silicon Radio, Ltd Bluetooth Dongle (HCI mode)
Bus 001 Device 002: ID 0627:0001 Adomax Technology Co., Ltd QEMU USB Tablet
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
as you can see both usb devices have properly attached to fedora34
kernel
we need Linux kernel > 5.10.x to have a proper support
[root@fedora ~]# uname -a
Linux fedora 5.11.10-300.fc34.x86_64 #1 SMP Thu Mar 25 14:03:32 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux pipewire
and of-course piperwire installed
[root@fedora ~]# rpm -qa | grep -Ei 'blue|pipe|pulse'
libpipeline-1.5.3-2.fc34.x86_64
pulseaudio-libs-14.2-3.fc34.x86_64
pulseaudio-libs-glib2-14.2-3.fc34.x86_64
pipewire0.2-libs-0.2.7-5.fc34.x86_64
bluez-libs-5.56-4.fc34.x86_64
pipewire-libs-0.3.24-4.fc34.x86_64
pipewire-0.3.24-4.fc34.x86_64
bluez-5.56-4.fc34.x86_64
bluez-obexd-5.56-4.fc34.x86_64
pipewire-gstreamer-0.3.24-4.fc34.x86_64
pipewire-pulseaudio-0.3.24-4.fc34.x86_64
gnome-bluetooth-libs-3.34.5-1.fc34.x86_64
gnome-bluetooth-3.34.5-1.fc34.x86_64
bluez-cups-5.56-4.fc34.x86_64
NetworkManager-bluetooth-1.30.2-1.fc34.x86_64
pipewire-alsa-0.3.24-4.fc34.x86_64
pipewire-jack-audio-connection-kit-0.3.24-4.fc34.x86_64
pipewire-utils-0.3.24-4.fc34.x86_64
screenshots
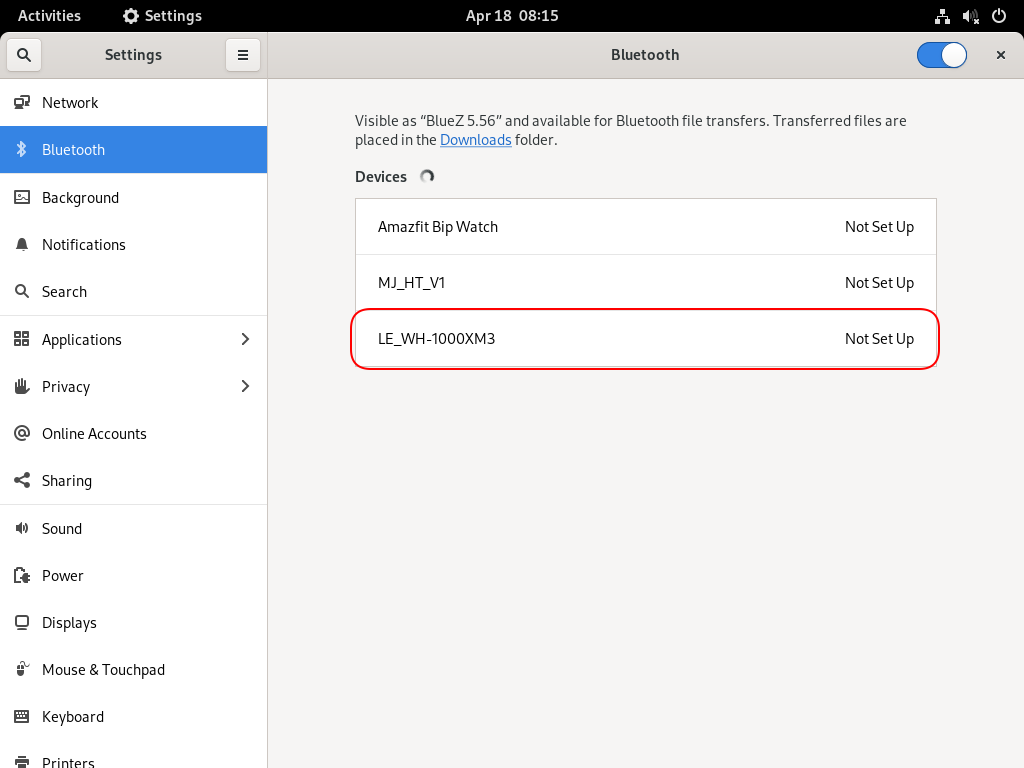
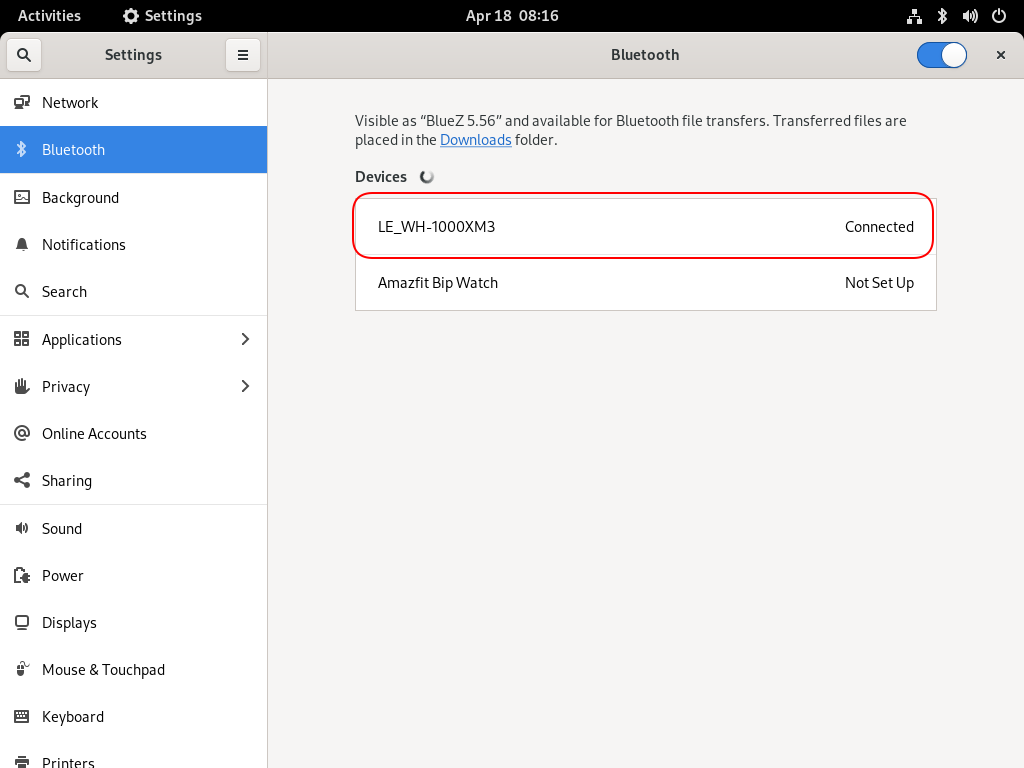
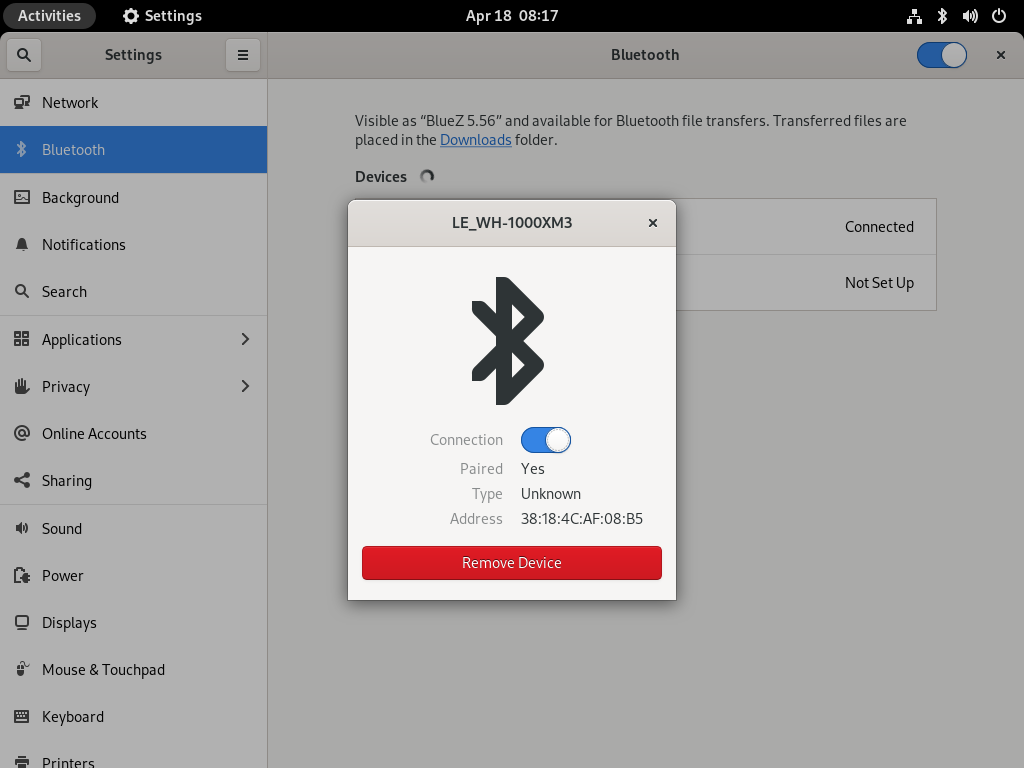
Bluetooth Profiles
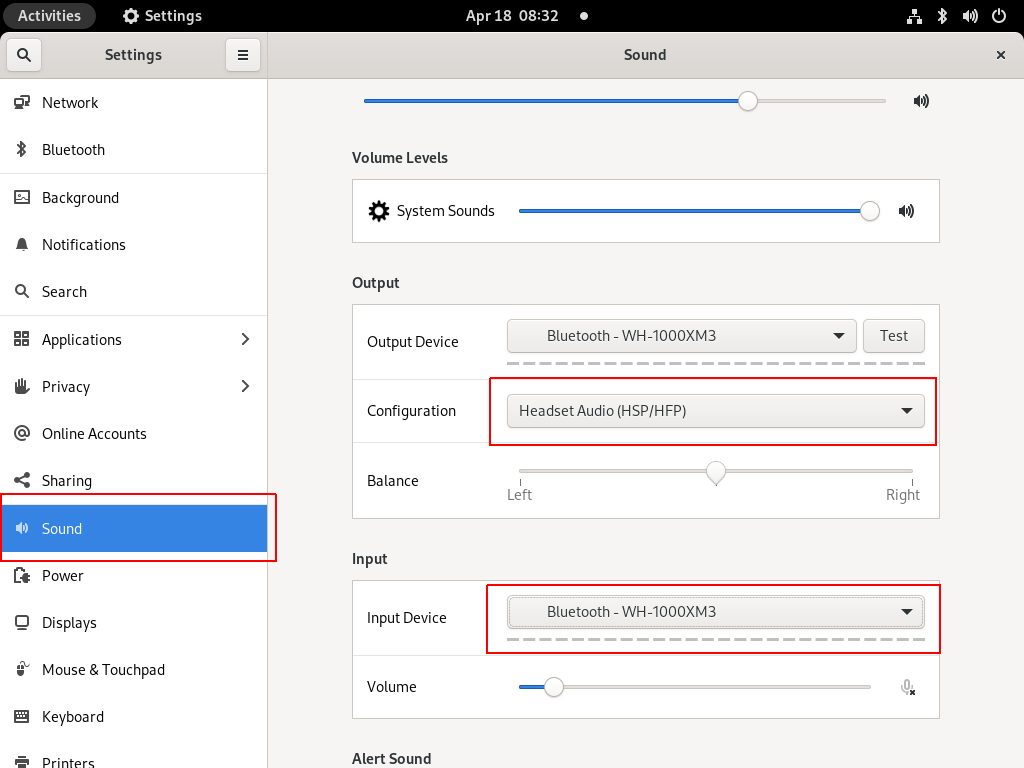
Online Meetings


In WSLv2 there is a way to limit the resources of your linux distro (cpu/memory) to have a better performance on you win10.
To give you an example, this is how it starts on my HP-G5
~$ free -m
total used free shared buffcache available
Mem: 12659 68 12555 0 34 12425
Swap: 4096 0 4096
~$ grep -Ec proc /proc/cpuinfo
8
8 CPU threads, 12G
wslconfig
To define your specs, open cmd and change to your user profile directory
~> cd %UserProfile%
Verify that your WSL distros are stopped:
~> wsl.exe -l -v
NAME STATE VERSION
* Archlinux Running 2
Ubuntu-20.04 Stopped 1
~> wsl.exe -t Archlinux -v
~> wsl.exe -l -v
NAME STATE VERSION
* Archlinux Stopped 2
Ubuntu-20.04 Stopped 1and terminate wsl
~> wsl.exe --shutdown
Create a new (or edit your previous) wsl config file
~> notepad.exe .wslconfigMy current setup is
~> type .wslconfig
[wsl2]
memory=4GB # Limits VM memory in WSL 2 to 4 GB
processors=2 # Makes the WSL 2 VM use two virtual processors
swap=2GB # How much swap space to add to the WSL2 VM. 0 for no swap file.
swapFile=C:\wsl2-swap.vhdx
as you can see, I want 4GB of RAM and 2 CPU , but also I want a 2GB swap file.
Edit this file according to your needs. The full settings can be found here wsl/wsl-config.
Reminder: you have to shutdown WSL
wsl.exe --shutdown
WSLv2 Limited
Now start your fav linux distro and verify
~$ grep -Ec proc /proc/cpuinfo
2
~$ grep -Ei MemTotal /proc/meminfo
MemTotal: 4028776 kB
~$ free
total used free shared buffcache available
Mem: 4028776 46348 3947056 64 35372 3848616
Swap: 2097152 0 2097152
that’s it !
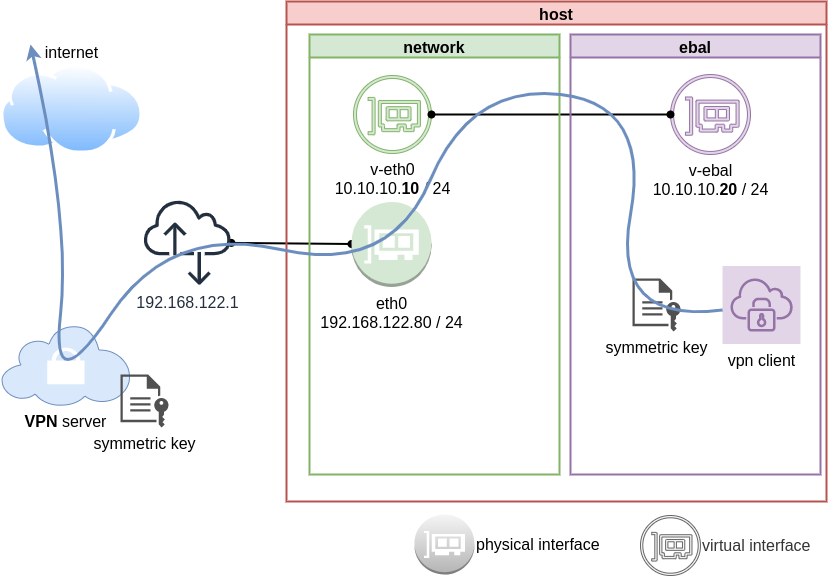
Previously on … Network Namespaces - Part Two we provided internet access to the namespace, enabled a different DNS than our system and run a graphical application (xterm/firefox) from within.
The scope of this article is to run vpn service from this namespace. We will run a vpn-client and try to enable firewall rules inside.
dsvpn
My VPN choice of preference is dsvpn and you can read in the below blog post, how to setup it.
dsvpn is a TCP, point-to-point VPN, using a symmetric key.
The instructions in this article will give you an understanding how to run a different vpn service.
Find your external IP
Before running the vpn client, let’s see what is our current external IP address
ip netns exec ebal curl ifconfig.co
62.103.103.103
The above IP is an example.
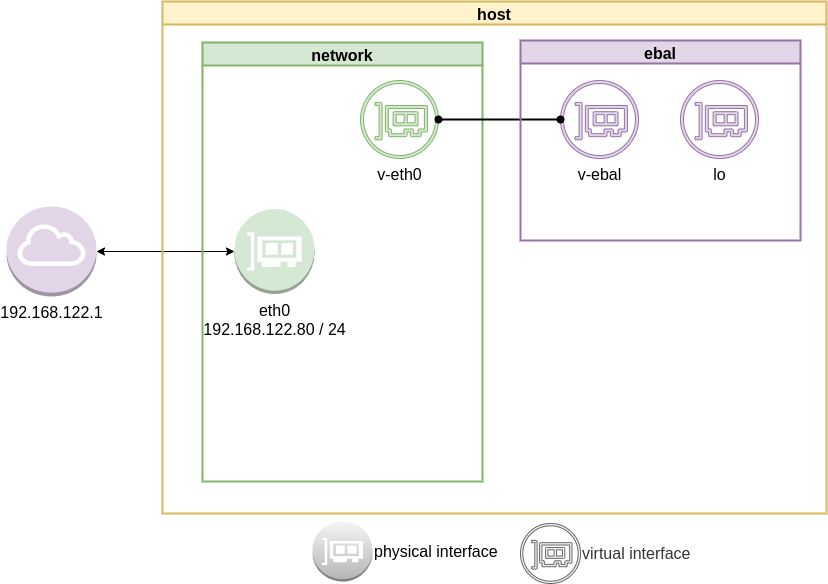
IP address and route of the namespace
ip netns exec ebal ip address show v-ebal
375: v-ebal@if376: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether c2:f3:a4:8a:41:47 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.10.20/24 scope global v-ebal
valid_lft forever preferred_lft forever
inet6 fe80::c0f3:a4ff:fe8a:4147/64 scope link
valid_lft forever preferred_lft forever
ip netns exec ebal ip route show
default via 10.10.10.10 dev v-ebal
10.10.10.0/24 dev v-ebal proto kernel scope link src 10.10.10.20
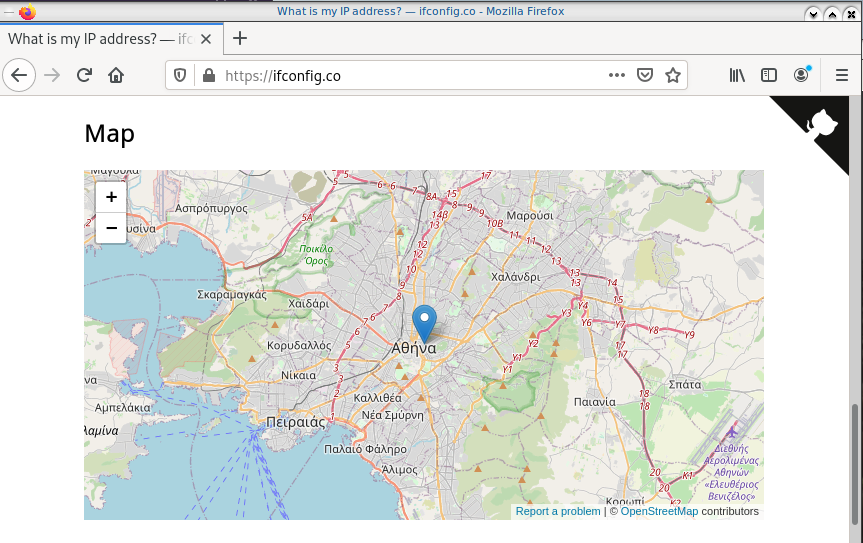
Firefox
Open firefox (see part-two) and visit ifconfig.co we noticed see that the location of our IP is based in Athens, Greece.
ip netns exec ebal bash -c "XAUTHORITY=/root/.Xauthority firefox"
Run VPN client
We have the symmetric key dsvpn.key and we know the VPN server’s IP.
ip netns exec ebal dsvpn client dsvpn.key 93.184.216.34 443
Interface: [tun0]
Trying to reconnect
Connecting to 93.184.216.34:443...
net.ipv4.tcp_congestion_control = bbr
Connected
Host
We can not see this tunnel vpn interface from our host machine
# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 94:de:80:6a:de:0e brd ff:ff:ff:ff:ff:ff
376: v-eth0@if375: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 1a:f7:c2:fb:60:ea brd ff:ff:ff:ff:ff:ff link-netns ebal
netns
but it exists inside the namespace, we can see tun0 interface here
ip netns exec ebal ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 9000 qdisc fq_codel state UNKNOWN mode DEFAULT group default qlen 500
link/none
375: v-ebal@if376: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether c2:f3:a4:8a:41:47 brd ff:ff:ff:ff:ff:ff link-netnsid 0
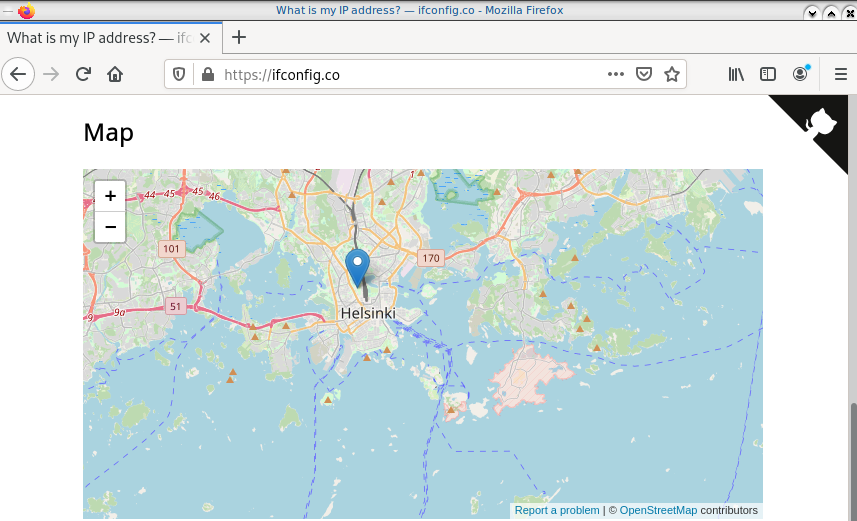
Find your external IP again
Checking your external internet IP from within the namespace
ip netns exec ebal curl ifconfig.co
93.184.216.34Firefox netns
running again firefox, we will noticed that our the location of our IP is based in Helsinki (vpn server’s location).
ip netns exec ebal bash -c "XAUTHORITY=/root/.Xauthority firefox"
systemd
We can wrap the dsvpn client under a systemcd service
[Unit]
Description=Dead Simple VPN - Client
[Service]
ExecStart=ip netns exec ebal /usr/local/bin/dsvpn client /root/dsvpn.key 93.184.216.34 443
Restart=always
RestartSec=20
[Install]
WantedBy=network.targetStart systemd service
systemctl start dsvpn.service
Verify
ip -n ebal a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: tun0: <POINTOPOINT,MULTICAST,NOARP,UP,LOWER_UP> mtu 9000 qdisc fq_codel state UNKNOWN group default qlen 500
link/none
inet 192.168.192.1 peer 192.168.192.254/32 scope global tun0
valid_lft forever preferred_lft forever
inet6 64:ff9b::c0a8:c001 peer 64:ff9b::c0a8:c0fe/96 scope global
valid_lft forever preferred_lft forever
inet6 fe80::ee69:bdd8:3554:d81/64 scope link stable-privacy
valid_lft forever preferred_lft forever
375: v-ebal@if376: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether c2:f3:a4:8a:41:47 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.10.20/24 scope global v-ebal
valid_lft forever preferred_lft forever
inet6 fe80::c0f3:a4ff:fe8a:4147/64 scope link
valid_lft forever preferred_lft forever
ip -n ebal route
default via 10.10.10.10 dev v-ebal
10.10.10.0/24 dev v-ebal proto kernel scope link src 10.10.10.20
192.168.192.254 dev tun0 proto kernel scope link src 192.168.192.1
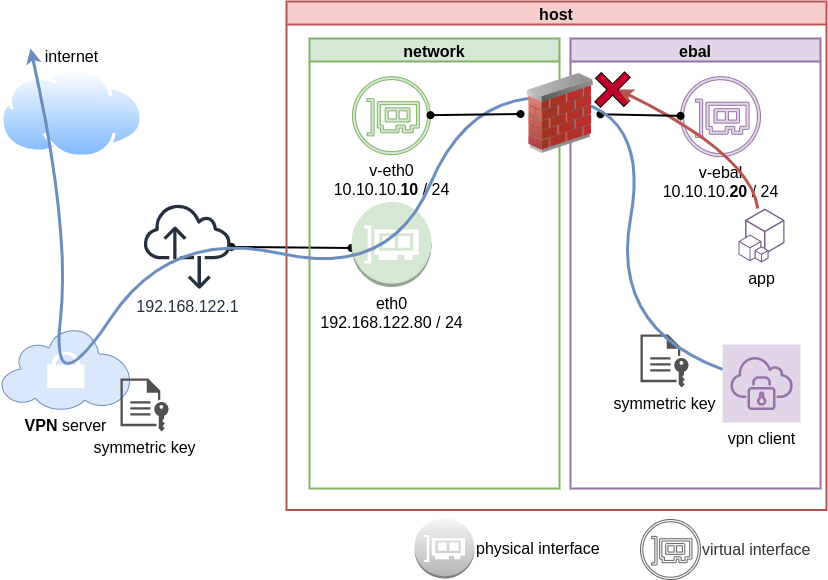
Firewall
We can also have different firewall policies for each namespace
outside
# iptables -nvL | wc -l
127
inside
ip netns exec ebal iptables -nvL
Chain INPUT (policy ACCEPT 9 packets, 2547 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 2 packets, 216 bytes)
pkts bytes target prot opt in out source destination
So for the VPN service running inside the namespace, we can REJECT every network traffic, except the traffic towards our VPN server and of course the veth interface (point-to-point) to our host machine.
iptable rules
Enter the namespace
inside
ip netns exec ebal bash
Before
verify that iptables rules are clear
iptables -nvL
Chain INPUT (policy ACCEPT 25 packets, 7373 bytes)
pkts bytes target prot opt in out source destination
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 4 packets, 376 bytes)
pkts bytes target prot opt in out source destination
Enable firewall
./iptables.netns.ebal.sh
The content of this file
## iptable rules
iptables -A INPUT -i lo -j ACCEPT
iptables -A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
iptables -A INPUT -m conntrack --ctstate INVALID -j DROP
iptables -A INPUT -p icmp --icmp-type 8 -m conntrack --ctstate NEW -j ACCEPT
## netns - incoming
iptables -A INPUT -i v-ebal -s 10.0.0.0/8 -j ACCEPT
## Reject incoming traffic
iptables -A INPUT -j REJECT
## DSVPN
iptables -A OUTPUT -p tcp -m tcp -o v-ebal -d 93.184.216.34 --dport 443 -j ACCEPT
## net-ns outgoing
iptables -A OUTPUT -o v-ebal -d 10.0.0.0/8 -j ACCEPT
## Allow tun
iptables -A OUTPUT -o tun+ -j ACCEPT
## Reject outgoing traffic
iptables -A OUTPUT -p tcp -j REJECT --reject-with tcp-reset
iptables -A OUTPUT -p udp -j REJECT --reject-with icmp-port-unreachable
After
iptables -nvL
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 ctstate INVALID
0 0 ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0 icmptype 8 ctstate NEW
1 349 ACCEPT all -- v-ebal * 10.0.0.0/8 0.0.0.0/0
0 0 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
0 0 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
0 0 ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 ctstate INVALID
0 0 ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0 icmptype 8 ctstate NEW
0 0 ACCEPT all -- v-ebal * 10.0.0.0/8 0.0.0.0/0
0 0 REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT tcp -- * v-ebal 0.0.0.0/0 95.216.215.96 tcp dpt:8443
0 0 ACCEPT all -- * v-ebal 0.0.0.0/0 10.0.0.0/8
0 0 ACCEPT all -- * tun+ 0.0.0.0/0 0.0.0.0/0
0 0 REJECT tcp -- * * 0.0.0.0/0 0.0.0.0/0 reject-with tcp-reset
0 0 REJECT udp -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
0 0 ACCEPT tcp -- * v-ebal 0.0.0.0/0 95.216.215.96 tcp dpt:8443
0 0 ACCEPT all -- * v-ebal 0.0.0.0/0 10.0.0.0/8
0 0 ACCEPT all -- * tun+ 0.0.0.0/0 0.0.0.0/0
0 0 REJECT tcp -- * * 0.0.0.0/0 0.0.0.0/0 reject-with tcp-reset
0 0 REJECT udp -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-port-unreachable
PS: We reject tcp/udp traffic (last 2 linew), but allow icmp (ping).
End of part three.
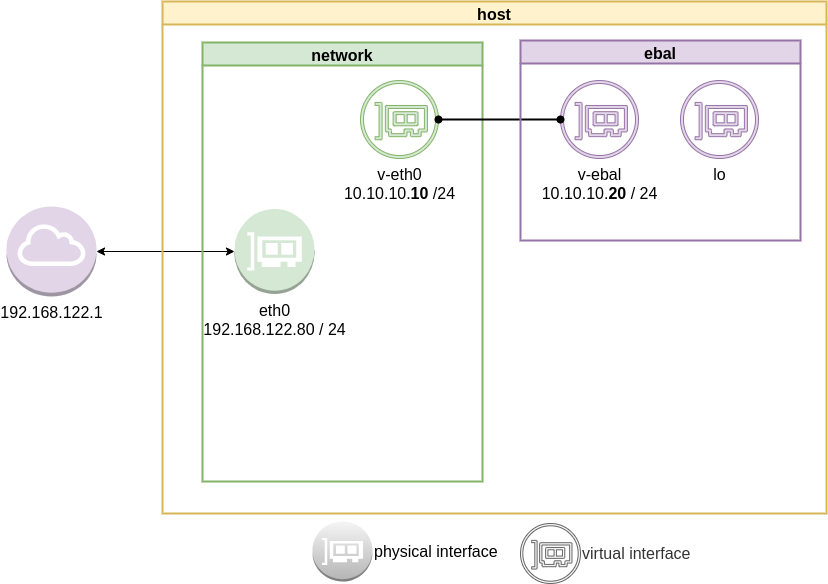
Previously on… Network Namespaces - Part One we discussed how to create an isolated network namespace and use a veth interfaces to talk between the host system and the namespace.
In this article we continue our story and we will try to connect that namespace to the internet.
recap previous commands
ip netns add ebal
ip link add v-eth0 type veth peer name v-ebal
ip link set v-ebal netns ebal
ip addr add 10.10.10.10/24 dev v-eth0
ip netns exec ebal ip addr add 10.10.10.20/24 dev v-ebal
ip link set v-eth0 up
ip netns exec ebal ip link set v-ebal up
Access namespace
ip netns exec ebal bash
# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: v-ebal@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether e2:07:60:da:d5:cf brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.10.20/24 scope global v-ebal
valid_lft forever preferred_lft forever
inet6 fe80::e007:60ff:feda:d5cf/64 scope link
valid_lft forever preferred_lft forever
# ip r
10.10.10.0/24 dev v-ebal proto kernel scope link src 10.10.10.20Ping Veth
It’s not a gateway, this is a point-to-point connection.
# ping -c3 10.10.10.10
PING 10.10.10.10 (10.10.10.10) 56(84) bytes of data.
64 bytes from 10.10.10.10: icmp_seq=1 ttl=64 time=0.415 ms
64 bytes from 10.10.10.10: icmp_seq=2 ttl=64 time=0.107 ms
64 bytes from 10.10.10.10: icmp_seq=3 ttl=64 time=0.126 ms
--- 10.10.10.10 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2008ms
rtt min/avg/max/mdev = 0.107/0.216/0.415/0.140 ms
Ping internet
trying to access anything else …
ip netns exec ebal ping -c2 192.168.122.80
ip netns exec ebal ping -c2 192.168.122.1
ip netns exec ebal ping -c2 8.8.8.8
ip netns exec ebal ping -c2 google.com
root@ubuntu2004:~# ping 192.168.122.80
ping: connect: Network is unreachable
root@ubuntu2004:~# ping 8.8.8.8
ping: connect: Network is unreachable
root@ubuntu2004:~# ping google.com
ping: google.com: Temporary failure in name resolution
root@ubuntu2004:~# exit
exit
exit from namespace.
Gateway
We need to define a gateway route from within the namespace
ip netns exec ebal ip route add default via 10.10.10.10
root@ubuntu2004:~# ip netns exec ebal ip route list
default via 10.10.10.10 dev v-ebal
10.10.10.0/24 dev v-ebal proto kernel scope link src 10.10.10.20
test connectivity - system
we can reach the host system, but we can not visit anything else
# ip netns exec ebal ping -c1 192.168.122.80
PING 192.168.122.80 (192.168.122.80) 56(84) bytes of data.
64 bytes from 192.168.122.80: icmp_seq=1 ttl=64 time=0.075 ms
--- 192.168.122.80 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.075/0.075/0.075/0.000 ms
# ip netns exec ebal ping -c3 192.168.122.80
PING 192.168.122.80 (192.168.122.80) 56(84) bytes of data.
64 bytes from 192.168.122.80: icmp_seq=1 ttl=64 time=0.026 ms
64 bytes from 192.168.122.80: icmp_seq=2 ttl=64 time=0.128 ms
64 bytes from 192.168.122.80: icmp_seq=3 ttl=64 time=0.126 ms
--- 192.168.122.80 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2033ms
rtt min/avg/max/mdev = 0.026/0.093/0.128/0.047 ms
# ip netns exec ebal ping -c3 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
--- 8.8.8.8 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2044ms
root@ubuntu2004:~# ip netns exec ebal ping -c3 google.com
ping: google.com: Temporary failure in name resolution
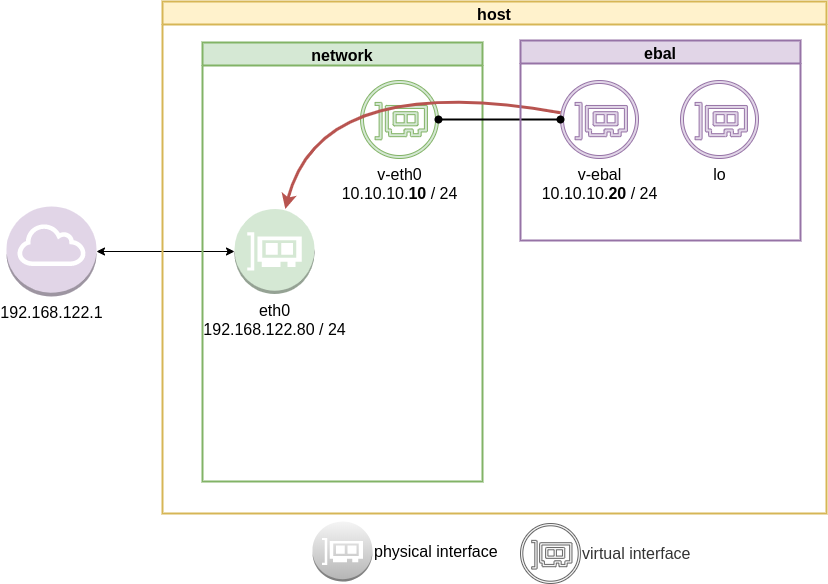
Forward
What is the issue here ?
We added a default route to the network namespace. Traffic will start from our v-ebal (veth interface inside the namespace), goes to the v-eth0 (veth interface to our system) and then … then nothing.
The eth0 receive the network packages but does not know what to do with them. We need to create a forward rule to our host, so the eth0 network interface will know to forward traffic from the namespace to the next hop.
echo 1 > /proc/sys/net/ipv4/ip_forward
or
sysctl -w net.ipv4.ip_forward=1
permanent forward
If we need to permanent tell the eth0 to always forward traffic, then we need to edit /etc/sysctl.conf and add below line:
net.ipv4.ip_forward = 1
To enable this option without reboot our system
sysctl -p /etc/sysctl.conf
verify
root@ubuntu2004:~# sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
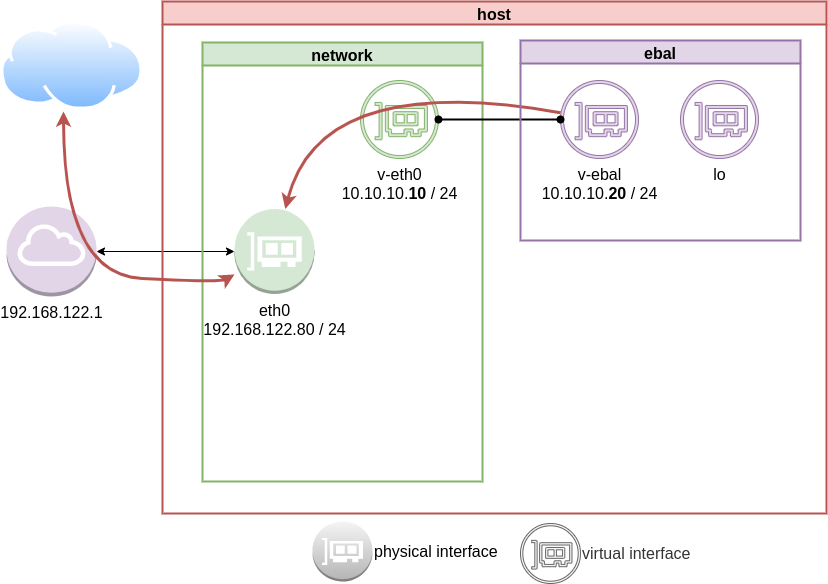
Masquerade
but if we test again, we will notice that nothing happened. Actually something indeed happened but not what we expected. At this moment, eth0 knows how to forward network packages to the next hope (perhaps next hope is the router or internet gateway) but next hop will get a package from an unknown network.
Remember that our internal network, is 10.10.10.20 with a point-to-point connection to 10.10.10.10. So there is no way for network 192.168.122.0/24 to know how to talk to 10.0.0.0/8.
We have to Masquerade all packages that come from 10.0.0.0/8 and the easiest way to do this if via iptables.
Using the postrouting nat table. That means the outgoing traffic with source 10.0.0.0/8 will have a mask, will pretend to be from 192.168.122.80 (eth0) before going to the next hop (gateway).
# iptables --table nat --flush
iptables --table nat --append POSTROUTING --source 10.0.0.0/8 --jump MASQUERADE
iptables --table nat --list
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 10.0.0.0/8 anywhereTest connectivity
test again the namespace connectivity
# ip netns exec ebal ping -c2 192.168.122.80
PING 192.168.122.80 (192.168.122.80) 56(84) bytes of data.
64 bytes from 192.168.122.80: icmp_seq=1 ttl=64 time=0.054 ms
64 bytes from 192.168.122.80: icmp_seq=2 ttl=64 time=0.139 ms
--- 192.168.122.80 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1017ms
rtt min/avg/max/mdev = 0.054/0.096/0.139/0.042 ms
# ip netns exec ebal ping -c2 192.168.122.1
PING 192.168.122.1 (192.168.122.1) 56(84) bytes of data.
64 bytes from 192.168.122.1: icmp_seq=1 ttl=63 time=0.242 ms
64 bytes from 192.168.122.1: icmp_seq=2 ttl=63 time=0.636 ms
--- 192.168.122.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1015ms
rtt min/avg/max/mdev = 0.242/0.439/0.636/0.197 ms
# ip netns exec ebal ping -c2 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=51 time=57.8 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=51 time=58.0 ms
--- 8.8.8.8 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 57.805/57.896/57.988/0.091 ms
# ip netns exec ebal ping -c2 google.com
ping: google.com: Temporary failure in name resolution
success
DNS
almost!
If you carefully noticed above, ping on the IP works.
But no with name resolution.
netns - resolv
Reading ip-netns manual
# man ip-netns | tbl | grep resolv
resolv.conf for a network namespace used to isolate your vpn you would name it /etc/netns/myvpn/resolv.conf.
we can create a resolver configuration file on this location:
/etc/netns/<namespace>/resolv.conf
mkdir -pv /etc/netns/ebal/
echo nameserver 88.198.92.222 > /etc/netns/ebal/resolv.conf
I am using radicalDNS for this namespace.
Verify DNS
# ip netns exec ebal cat /etc/resolv.conf
nameserver 88.198.92.222
Connect to the namespace
ip netns exec ebal bash
root@ubuntu2004:~# cat /etc/resolv.conf
nameserver 88.198.92.222
root@ubuntu2004:~# ping -c 5 ipv4.balaskas.gr
PING ipv4.balaskas.gr (158.255.214.14) 56(84) bytes of data.
64 bytes from ns14.balaskas.gr (158.255.214.14): icmp_seq=1 ttl=50 time=64.3 ms
64 bytes from ns14.balaskas.gr (158.255.214.14): icmp_seq=2 ttl=50 time=64.2 ms
64 bytes from ns14.balaskas.gr (158.255.214.14): icmp_seq=3 ttl=50 time=66.9 ms
64 bytes from ns14.balaskas.gr (158.255.214.14): icmp_seq=4 ttl=50 time=63.8 ms
64 bytes from ns14.balaskas.gr (158.255.214.14): icmp_seq=5 ttl=50 time=63.3 ms
--- ipv4.balaskas.gr ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4006ms
rtt min/avg/max/mdev = 63.344/64.502/66.908/1.246 ms
root@ubuntu2004:~# ping -c3 google.com
PING google.com (172.217.22.46) 56(84) bytes of data.
64 bytes from fra15s16-in-f14.1e100.net (172.217.22.46): icmp_seq=1 ttl=51 time=57.4 ms
64 bytes from fra15s16-in-f14.1e100.net (172.217.22.46): icmp_seq=2 ttl=51 time=55.4 ms
64 bytes from fra15s16-in-f14.1e100.net (172.217.22.46): icmp_seq=3 ttl=51 time=55.2 ms
--- google.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 55.209/55.984/57.380/0.988 ms
bonus - run firefox from within namespace
xterm
start with something simple first, like xterm
ip netns exec ebal xterm
or
ip netns exec ebal xterm -fa liberation -fs 11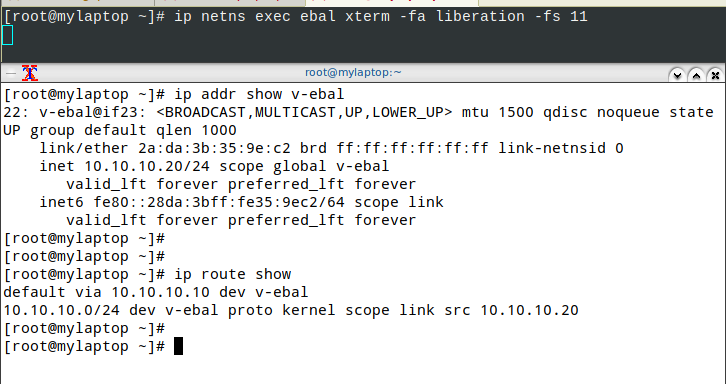
test firefox
trying to run firefox within this namespace, will produce an error
# ip netns exec ebal firefox
Running Firefox as root in a regular user's session is not supported. ($XAUTHORITY is /home/ebal/.Xauthority which is owned by ebal.)
and xauth info will inform us, that the current Xauthority file is owned by our local user.
# xauth info
Authority file: /home/ebal/.Xauthority
File new: no
File locked: no
Number of entries: 4
Changes honored: yes
Changes made: no
Current input: (argv):1
okay, get inside this namespace
ip netns exec ebal bash
and provide a new authority file for firefox
XAUTHORITY=/root/.Xauthority firefox
# XAUTHORITY=/root/.Xauthority firefox
No protocol specified
Unable to init server: Could not connect: Connection refused
Error: cannot open display: :0.0xhost
xhost provide access control to the Xorg graphical server.
By default should look like this:
$ xhost
access control enabled, only authorized clients can connect
We can also disable access control
xhost +
but what we need to do, is to disable access control on local
xhost +local:
firefox
and if we do all that
ip netns exec ebal bash -c "XAUTHORITY=/root/.Xauthority firefox"
End of part two
Have you ever wondered how containers work on the network level? How they isolate resources and network access? Linux namespaces is the magic behind all these and in this blog post, I will try to explain how to setup your own private, isolated network stack on your linux box.
notes based on ubuntu:20.04, root access.
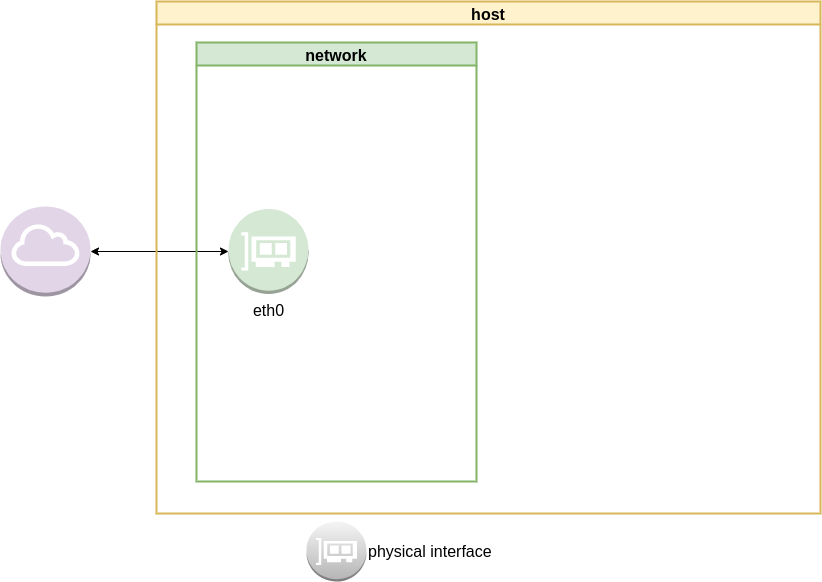
current setup
Our current setup is similar to this
List ethernet cards
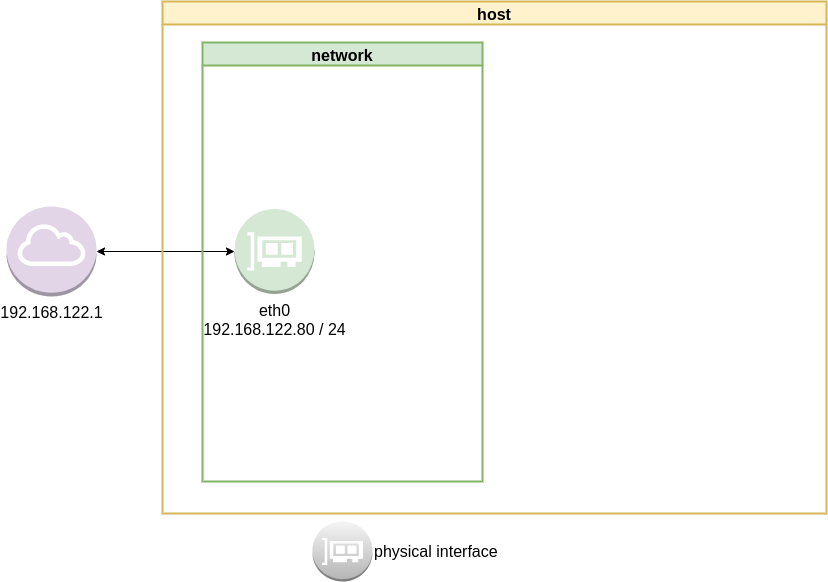
ip address list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:ea:50:87 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.80/24 brd 192.168.122.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:feea:5087/64 scope link
valid_lft forever preferred_lft forever
List routing table
ip route list
default via 192.168.122.1 dev eth0 proto static
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.80
Checking internet access and dns
ping -c 5 libreops.cc
PING libreops.cc (185.199.111.153) 56(84) bytes of data.
64 bytes from 185.199.111.153 (185.199.111.153): icmp_seq=1 ttl=54 time=121 ms
64 bytes from 185.199.111.153 (185.199.111.153): icmp_seq=2 ttl=54 time=124 ms
64 bytes from 185.199.111.153 (185.199.111.153): icmp_seq=3 ttl=54 time=182 ms
64 bytes from 185.199.111.153 (185.199.111.153): icmp_seq=4 ttl=54 time=162 ms
64 bytes from 185.199.111.153 (185.199.111.153): icmp_seq=5 ttl=54 time=168 ms
--- libreops.cc ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4004ms
rtt min/avg/max/mdev = 121.065/151.405/181.760/24.299 ms
linux network namespace management
In this article we will use the below programs:
so, let us start working with network namespaces.
list
To view the network namespaces, we can type:
ip netns
ip netns listThis will return nothing, an empty list.
help
So quicly view the help of ip-netns
# ip netns help
Usage: ip netns list
ip netns add NAME
ip netns attach NAME PID
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
ip netns identify [PID]
ip netns pids NAME
ip [-all] netns exec [NAME] cmd ...
ip netns monitor
ip netns list-id [target-nsid POSITIVE-INT] [nsid POSITIVE-INT]
NETNSID := auto | POSITIVE-INTmonitor
To monitor in real time any changes, we can open a new terminal and type:
ip netns monitor
Add a new namespace
ip netns add ebal
List namespaces
ip netns list
root@ubuntu2004:~# ip netns add ebal
root@ubuntu2004:~# ip netns list
ebal
We have one namespace
Delete Namespace
ip netns del ebal
Full example
root@ubuntu2004:~# ip netns
root@ubuntu2004:~# ip netns list
root@ubuntu2004:~# ip netns add ebal
root@ubuntu2004:~# ip netns list
ebal
root@ubuntu2004:~# ip netns
ebal
root@ubuntu2004:~# ip netns del ebal
root@ubuntu2004:~#
root@ubuntu2004:~# ip netns
root@ubuntu2004:~# ip netns list
root@ubuntu2004:~#
monitor
root@ubuntu2004:~# ip netns monitor
add ebal
delete ebal
Directory
When we create a new network namespace, it creates an object under /var/run/netns/.
root@ubuntu2004:~# ls -l /var/run/netns/
total 0
-r--r--r-- 1 root root 0 May 9 16:44 ebal
exec
We can run commands inside a namespace.
eg.
ip netns exec ebal ip a
root@ubuntu2004:~# ip netns exec ebal ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
bash
we can also open a shell inside the namespace and run commands throught the shell.
eg.
root@ubuntu2004:~# ip netns exec ebal bash
root@ubuntu2004:~# ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
root@ubuntu2004:~# exit
exit
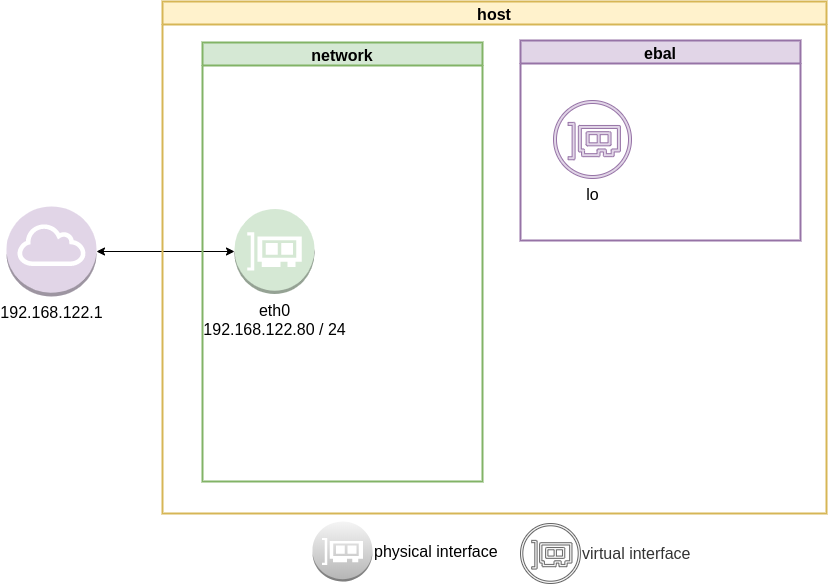
as you can see, the namespace is isolated from our system. It has only one local interface and nothing else.
We can bring up the loopback interface up
root@ubuntu2004:~# ip link set lo up
root@ubuntu2004:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
root@ubuntu2004:~# ip rveth
The veth devices are virtual Ethernet devices. They can act as tunnels between network namespaces to create a bridge to a physical network device in another namespace, but can also be used as standalone network devices.
Think Veth as a physical cable that connects two different computers. Every veth is the end of this cable.
So we need 2 virtual interfaces to connect our system and the new namespace.
ip link add v-eth0 type veth peer name v-ebal
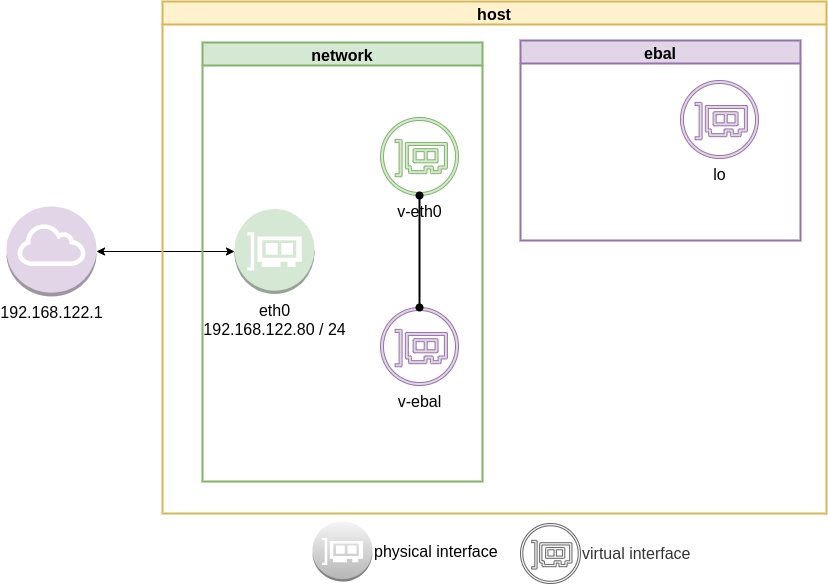
eg.
root@ubuntu2004:~# ip link add v-eth0 type veth peer name v-ebal
root@ubuntu2004:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:ea:50:87 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.80/24 brd 192.168.122.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:feea:5087/64 scope link
valid_lft forever preferred_lft forever
3: v-ebal@v-eth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether d6:86:88:3f:eb:42 brd ff:ff:ff:ff:ff:ff
4: v-eth0@v-ebal: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 3e:85:9b:dd:c7:96 brd ff:ff:ff:ff:ff:ff
Attach veth0 to namespace
Now we are going to move one virtual interface (one end of the cable) to the new network namespace
ip link set v-ebal netns ebal
we will see that the interface is not showing on our system
root@ubuntu2004:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:ea:50:87 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.80/24 brd 192.168.122.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:feea:5087/64 scope link
valid_lft forever preferred_lft forever
4: v-eth0@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 3e:85:9b:dd:c7:96 brd ff:ff:ff:ff:ff:ff link-netns ebal
inside the namespace
root@ubuntu2004:~# ip netns exec ebal ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: v-ebal@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether d6:86:88:3f:eb:42 brd ff:ff:ff:ff:ff:ff link-netnsid 0
Connect the two virtual interfaces
outside
ip addr add 10.10.10.10/24 dev v-eth0
root@ubuntu2004:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:ea:50:87 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.80/24 brd 192.168.122.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:feea:5087/64 scope link
valid_lft forever preferred_lft forever
4: v-eth0@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 3e:85:9b:dd:c7:96 brd ff:ff:ff:ff:ff:ff link-netns ebal
inet 10.10.10.10/24 scope global v-eth0
valid_lft forever preferred_lft forever
inside
ip netns exec ebal ip addr add 10.10.10.20/24 dev v-ebal
root@ubuntu2004:~# ip netns exec ebal ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: v-ebal@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether d6:86:88:3f:eb:42 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.10.10.20/24 scope global v-ebal
valid_lft forever preferred_lft forever
Both Interfaces are down!
But both interfaces are down, now we need to set up both interfaces:
outside
ip link set v-eth0 up
root@ubuntu2004:~# ip link set v-eth0 up
root@ubuntu2004:~# ip link show v-eth0
4: v-eth0@if3: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN mode DEFAULT group default qlen 1000
link/ether 3e:85:9b:dd:c7:96 brd ff:ff:ff:ff:ff:ff link-netns ebal
inside
ip netns exec ebal ip link set v-ebal up
root@ubuntu2004:~# ip netns exec ebal ip link set v-ebal up
root@ubuntu2004:~# ip netns exec ebal ip link show v-ebal
3: v-ebal@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether d6:86:88:3f:eb:42 brd ff:ff:ff:ff:ff:ff link-netnsid 0
did it worked?
Let’s first see our routing table:
outside
root@ubuntu2004:~# ip r
default via 192.168.122.1 dev eth0 proto static
10.10.10.0/24 dev v-eth0 proto kernel scope link src 10.10.10.10
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.80
inside
root@ubuntu2004:~# ip netns exec ebal ip r
10.10.10.0/24 dev v-ebal proto kernel scope link src 10.10.10.20
Ping !
outside
root@ubuntu2004:~# ping -c 5 10.10.10.20
PING 10.10.10.20 (10.10.10.20) 56(84) bytes of data.
64 bytes from 10.10.10.20: icmp_seq=1 ttl=64 time=0.028 ms
64 bytes from 10.10.10.20: icmp_seq=2 ttl=64 time=0.042 ms
64 bytes from 10.10.10.20: icmp_seq=3 ttl=64 time=0.052 ms
64 bytes from 10.10.10.20: icmp_seq=4 ttl=64 time=0.042 ms
64 bytes from 10.10.10.20: icmp_seq=5 ttl=64 time=0.071 ms
--- 10.10.10.20 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4098ms
rtt min/avg/max/mdev = 0.028/0.047/0.071/0.014 ms
inside
root@ubuntu2004:~# ip netns exec ebal bash
root@ubuntu2004:~#
root@ubuntu2004:~# ping -c 5 10.10.10.10
PING 10.10.10.10 (10.10.10.10) 56(84) bytes of data.
64 bytes from 10.10.10.10: icmp_seq=1 ttl=64 time=0.046 ms
64 bytes from 10.10.10.10: icmp_seq=2 ttl=64 time=0.042 ms
64 bytes from 10.10.10.10: icmp_seq=3 ttl=64 time=0.041 ms
64 bytes from 10.10.10.10: icmp_seq=4 ttl=64 time=0.044 ms
64 bytes from 10.10.10.10: icmp_seq=5 ttl=64 time=0.053 ms
--- 10.10.10.10 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 4088ms
rtt min/avg/max/mdev = 0.041/0.045/0.053/0.004 ms
root@ubuntu2004:~# exit
exit
It worked !!
End of part one.
I use Linux Software RAID for years now. It is reliable and stable (as long as your hard disks are reliable) with very few problems. One recent issue -that the daily cron raid-check was reporting- was this:
WARNING: mismatch_cnt is not 0 on /dev/md0
Raid Environment
A few details on this specific raid setup:
RAID 5 with 4 Drives
with 4 x 1TB hard disks and according the online raid calculator:
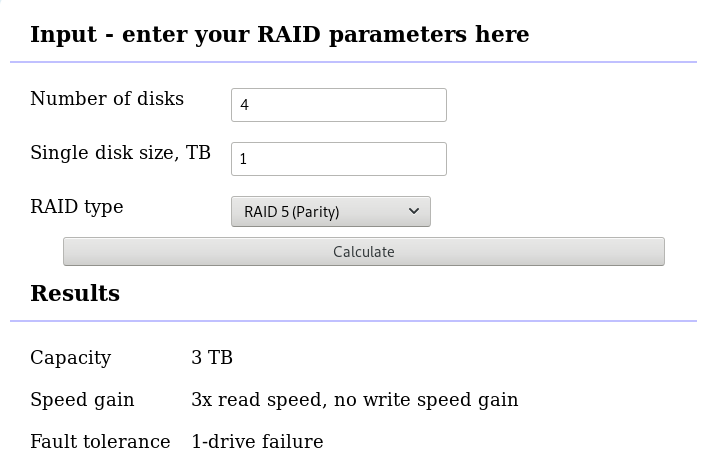
that means this setup is fault tolerant and cheap but not fast.
Raid Details
# /sbin/mdadm --detail /dev/md0
raid configuration is valid
/dev/md0:
Version : 1.2
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sat Oct 27 04:38:04 2018
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : ServerTwo:0 (local to host ServerTwo)
UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Events : 60352
Number Major Minor RaidDevice State
4 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
6 8 48 2 active sync /dev/sdd
5 8 0 3 active sync /dev/sda
Examine Verbose Scan
with a more detailed output:
# mdadm -Evvvvs
there are a few Bad Blocks, although it is perfectly normal for a two (2) year disks to have some. smartctl is a tool you need to use from time to time.
/dev/sdd:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Name : ServerTwo:0 (local to host ServerTwo)
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 1953266096 (931.39 GiB 1000.07 GB)
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 1953262592 (931.39 GiB 1000.07 GB)
Data Offset : 259072 sectors
Super Offset : 8 sectors
Unused Space : before=258984 sectors, after=3504 sectors
State : clean
Device UUID : bdd41067:b5b243c6:a9b523c4:bc4d4a80
Update Time : Sun Oct 28 09:04:01 2018
Bad Block Log : 512 entries available at offset 72 sectors
Checksum : 6baa02c9 - correct
Events : 60355
Layout : left-symmetric
Chunk Size : 512K
Device Role : Active device 2
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)
/dev/sde:
MBR Magic : aa55
Partition[0] : 8388608 sectors at 2048 (type 82)
Partition[1] : 226050048 sectors at 8390656 (type 83)
/dev/sdc:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Name : ServerTwo:0 (local to host ServerTwo)
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 1953263024 (931.39 GiB 1000.07 GB)
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 1953262592 (931.39 GiB 1000.07 GB)
Data Offset : 259072 sectors
Super Offset : 8 sectors
Unused Space : before=258992 sectors, after=3504 sectors
State : clean
Device UUID : a90e317e:43848f30:0de1ee77:f8912610
Update Time : Sun Oct 28 09:04:01 2018
Checksum : 30b57195 - correct
Events : 60355
Layout : left-symmetric
Chunk Size : 512K
Device Role : Active device 1
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)
/dev/sdb:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Name : ServerTwo:0 (local to host ServerTwo)
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 1953263024 (931.39 GiB 1000.07 GB)
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 1953262592 (931.39 GiB 1000.07 GB)
Data Offset : 259072 sectors
Super Offset : 8 sectors
Unused Space : before=258984 sectors, after=3504 sectors
State : clean
Device UUID : ad7315e5:56cebd8c:75c50a72:893a63db
Update Time : Sun Oct 28 09:04:01 2018
Bad Block Log : 512 entries available at offset 72 sectors
Checksum : b928adf1 - correct
Events : 60355
Layout : left-symmetric
Chunk Size : 512K
Device Role : Active device 0
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)
/dev/sda:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Name : ServerTwo:0 (local to host ServerTwo)
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 1953263024 (931.39 GiB 1000.07 GB)
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 1953262592 (931.39 GiB 1000.07 GB)
Data Offset : 259072 sectors
Super Offset : 8 sectors
Unused Space : before=258984 sectors, after=3504 sectors
State : clean
Device UUID : f4e1da17:e4ff74f0:b1cf6ec8:6eca3df1
Update Time : Sun Oct 28 09:04:01 2018
Bad Block Log : 512 entries available at offset 72 sectors
Checksum : bbe3e7e8 - correct
Events : 60355
Layout : left-symmetric
Chunk Size : 512K
Device Role : Active device 3
Array State : AAAA ('A' == active, '.' == missing, 'R' == replacing)
MisMatch Warning
WARNING: mismatch_cnt is not 0 on /dev/md0
So this is not a critical error, rather tells us that there are a few blocks that are “Not Synced Yet” across all disks.
Status
Checking the Multiple Device (md) driver status:
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]We verify that none job is running on the raid.
Repair
We can run a manual repair job:
# echo repair >/sys/block/md0/md/sync_action
now status looks like:
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[=========>...........] resync = 45.6% (445779112/976631296) finish=54.0min speed=163543K/sec
unused devices: <none>
Progress
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[============>........] resync = 63.4% (619673060/976631296) finish=38.2min speed=155300K/sec
unused devices: <none>Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[================>....] resync = 81.9% (800492148/976631296) finish=21.6min speed=135627K/sec
unused devices: <none>
Finally
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
unused devices: <none>
Check
After repair is it useful to check again the status of our software raid:
# echo check >/sys/block/md0/md/sync_action
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[=>...................] check = 9.5% (92965776/976631296) finish=91.0min speed=161680K/sec
unused devices: <none>and finally
# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdc[1] sda[5] sdd[6] sdb[4]
2929893888 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
unused devices: <none>The problem
The last couple weeks, a backup server I am managing is failing to make backups!
The backup procedure (a script via cron daemon) is to rsync data from a primary server to it’s /backup directory. I was getting cron errors via email, informing me that the previous rsync script hasnt already finished when the new one was starting (by checking a lock file). This was strange as the time duration is 12hours. 12 hours werent enough to perform a ~200M data transfer over a 100Mb/s network port. That was really strange.
This is the second time in less than a year that this server is making problems. A couple months ago I had to remove a faulty disk from the software raid setup and check the system again. My notes on the matter, can be found here:
https://balaskas.gr/blog/2016/10/17/linux-raid-mdadm-md0/
Identify the problem
So let us start to identify the problem. A slow rsync can mean a lot of things, especially over ssh. Replacing network cables, viewing dmesg messages, rebooting servers or even changing the filesystem werent changing any things for the better. Time to move on the disks.
Manage and Monitor software RAID devices
On this server, I use raid5 with four hard disks:
# mdadm --verbose --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sun May 7 11:00:32 2017
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : ServerTwo:0 (local to host ServerTwo)
UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Events : 10496
Number Major Minor RaidDevice State
4 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
6 8 48 2 active sync /dev/sdd
5 8 0 3 active sync /dev/sda
View hardware parameters of hard disk drive
aka test the hard disks:
# hdparm -Tt /dev/sda
/dev/sda:
Timing cached reads: 2490 MB in 2.00 seconds = 1245.06 MB/sec
Timing buffered disk reads: 580 MB in 3.01 seconds = 192.93 MB/sec# hdparm -Tt /dev/sdb
/dev/sdb:
Timing cached reads: 2520 MB in 2.00 seconds = 1259.76 MB/sec
Timing buffered disk reads: 610 MB in 3.00 seconds = 203.07 MB/sec
# hdparm -Tt /dev/sdc
/dev/sdc:
Timing cached reads: 2512 MB in 2.00 seconds = 1255.43 MB/sec
Timing buffered disk reads: 570 MB in 3.01 seconds = 189.60 MB/sec# hdparm -Tt /dev/sdd
/dev/sdd:
Timing cached reads: 2 MB in 7.19 seconds = 285.00 kB/sec
Timing buffered disk reads: 2 MB in 5.73 seconds = 357.18 kB/secRoot Cause
Seems that one of the disks (/dev/sdd) in raid5 setup, is not performing as well as the others. The same hard disk had a problem a few months ago.
What I did the previous time, was to remove the disk, reformatting it in Low Level Format and add it again in the same setup. The system rebuild the raid5 and after 24hours everything was performing fine.
However the same hard disk seems that still has some issues . Now it is time for me to remove it and find a replacement disk.
Remove Faulty disk
I need to manually fail and then remove the faulty disk from the raid setup.
Failing the disk
Failing the disk manually, means that mdadm is not recognizing the disk as failed (as it did previously). I need to tell mdadm that this specific disk is a faulty one:
# mdadm --manage /dev/md0 --fail /dev/sdd
mdadm: set /dev/sdd faulty in /dev/md0Removing the disk
now it is time to remove the faulty disk from our raid setup:
# mdadm --manage /dev/md0 --remove /dev/sdd
mdadm: hot removed /dev/sdd from /dev/md0
Show details
# mdadm --verbose --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Array Size : 2929893888 (2794.16 GiB 3000.21 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 4
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Sun May 7 11:08:44 2017
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Name : ServerTwo:0 (local to host ServerTwo)
UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Events : 10499
Number Major Minor RaidDevice State
4 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
4 0 0 4 removed
5 8 0 3 active sync /dev/sda
Mounting the Backup
Now it’s time to re-mount the backup directory and re-run the rsync script
mount /backup/
and run the rsync with verbose and progress parameters to review the status of syncing
/usr/bin/rsync -zravxP --safe-links --delete-before --partial --protect-args -e ssh 192.168.2.1:/backup/ /backup/
Everything seems ok.
A replacement order has already been placed.
Rsync times manage to hit ~ 10.27MB/s again!
rsync time for a daily (12h) diff is now again in normal rates:
real 15m18.112s
user 0m34.414s
sys 0m36.850sLinux Raid
This blog post is created as a mental note for future reference
Linux Raid is the de-facto way for decades in the linux-world on how to create and use a software raid. RAID stands for: Redundant Array of Independent Disks. Some people use the I for inexpensive disks, I guess that works too!
In simple terms, you can use a lot of hard disks to behave as one disk with special capabilities!
You can use your own inexpensive/independent hard disks as long as they have the same geometry and you can do almost everything. Also it’s pretty easy to learn and use linux raid. If you dont have the same geometry, then linux raid will use the smallest one from your disks. Modern methods, like LVM and BTRFS can provide an abstract layer with more capabilities to their users, but some times (or because something you have built a loooong time ago) you need to go back to basics.
And every time -EVERY time- I am searching online for all these cool commands that those cool kids are using. Cause what’s more exciting than replacing your -a decade ago- linux raid setup this typical Saturday night?
Identify your Hard Disks
% find /sys/devices/ -type f -name model -exec cat {} \;
ST1000DX001-1CM1
ST1000DX001-1CM1
ST1000DX001-1CM1
% lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 931.5G 0 disk
sdb 8:16 0 931.5G 0 disk
sdc 8:32 0 931.5G 0 disk
% lsblk -io KNAME,TYPE,SIZE,MODEL
KNAME TYPE SIZE MODEL
sda disk 931.5G ST1000DX001-1CM1
sdb disk 931.5G ST1000DX001-1CM1
sdc disk 931.5G ST1000DX001-1CM1
Create a RAID-5 with 3 Disks
Having 3 hard disks of 1T size, we are going to use the raid-5 Level . That means that we have 2T of disk usage and the third disk with keep the parity of the first two disks. Raid5 provides us with the benefit of loosing one hard disk without loosing any data from our hard disk scheme.

% mdadm -C -v /dev/md0 --level=5 --raid-devices=3 /dev/sda /dev/sdb /dev/sdc
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 512K
mdadm: sze set to 5238784K
mdadm: Defaulting to version 1.2 metadata
md/raid:md0 raid level 5 active with 2 our of 3 devices, algorithm 2
mdadm: array /dev/md0 started.
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0: active raid5 sdc[3] sdb[2] sda[1]
10477568 blocks super 1.2 level 5, 512k chink, algorith 2 [3/3] [UUU]
unused devices: <none>
running lsblk will show us our new scheme:
# lsblk -io KNAME,TYPE,SIZE,MODEL
KNAME TYPE SIZE MODEL
sda disk 931.5G ST1000DX001-1CM1
md0 raid5 1.8T
sdb disk 931.5G ST1000DX001-1CM1
md0 raid5 1.8T
sdc disk 931.5G ST1000DX001-1CM1
md0 raid5 1.8T
Save the Linux Raid configuration into a file
Software linux raid means that the raid configuration is actually ON the hard disks. You can take those 3 disks and put them to another linux box and everything will be there!! If you are keeping your operating system to another harddisk, you can also change your linux distro from one to another and your data will be on your linux raid5 and you can access them without any extra software from your new linux distro.
But it is a good idea to keep the basic conf to a specific configuration file, so if you have hardware problems your machine could understand what type of linux raid level you need to have on those broken disks!
% mdadm --detail --scan >> /etc/mdadm.conf
% cat /etc/mdadm.conf
ARRAY /dev/md0 metadata=1.2 name=MyServer:0 UUID=ef5da4df:3e53572e:c3fe1191:925b24cf
UUID - Universally Unique IDentifier
Be very careful that the above UUID is the UUID of the linux raid on your disks.
We have not yet created a filesystem over this new disk /dev/md0 and if you need to add this filesystem under your fstab file you can not use the UUID of the linux raid md0 disk.
Below there is an example on my system:
% blkid
/dev/sda: UUID="ef5da4df-3e53-572e-c3fe-1191925b24cf" UUID_SUB="f4e1da17-e4ff-74f0-b1cf-6ec86eca3df1" LABEL="MyServer:0" TYPE="linux_raid_member"
/dev/sdb: UUID="ef5da4df-3e53-572e-c3fe-1191925b24cf" UUID_SUB="ad7315e5-56ce-bd8c-75c5-0a72893a63db" LABEL="MyServer:0" TYPE="linux_raid_member"
/dev/sdc: UUID="ef5da4df-3e53-572e-c3fe-1191925b24cf" UUID_SUB="a90e317e-4384-8f30-0de1-ee77f8912610" LABEL="MyServer:0" TYPE="linux_raid_member"
/dev/md0: LABEL="data" UUID="48fc963a-2128-4d35-85fb-b79e2546dce7" TYPE="ext4"
% cat /etc/fstab
UUID=48fc963a-2128-4d35-85fb-b79e2546dce7 /backup auto defaults 0 0
Replacing a hard disk
Hard disks will fail you. This is a fact that every sysadmin knows from day one. Systems will fail at some point in the future. So be prepared and keep backups !!
Failing a disk
Now it’s time to fail (if not already) the disk we want to replace:
% mdadm --manage /dev/md0 --fail /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md0
Remove a broken disk
Here is a simple way to remove a broken disk from your linux raid configuration. Remember with raid5 level we can manage with 2 hard disks.
% mdadm --manage /dev/md0 --remove /dev/sdb
mdadm: hot removed /dev/sdb from /dev/md0
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
unused devices: <none>
dmesg shows:
% dmesg | tail
md: data-check of RAID array md0
md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for data-check.
md: using 128k window, over a total of 976631296k.
md: md0: data-check done.
md/raid:md0: Disk failure on sdb, disabling device.
md/raid:md0: Operation continuing on 2 devices.
RAID conf printout:
--- level:5 rd:3 wd:2
disk 0, o:0, dev:sda
disk 1, o:1, dev:sdb
disk 2, o:1, dev:sdc
RAID conf printout:
--- level:5 rd:3 wd:2
disk 0, o:0, dev:sda
disk 2, o:1, dev:sdc
md: unbind<sdb>
md: export_rdev(sdb)
Adding a new disk - replacing a broken one
Now it’s time to add a new and (if possible) clean hard disk. Just to be sure, I always wipe with dd the first few kilobytes of every disk with zeros.
Using mdadm to add this new disk:
# mdadm --manage /dev/md0 --add /dev/sdb
mdadm: added /dev/sdb
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb[4] sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[>....................] recovery = 0.2% (2753372/976631296) finish=189.9min speed=85436K/sec
unused devices: <none>
For a 1T Hard Disk is about 3h of recovering data. Keep that in mind on scheduling the maintenance window.
after a few minutes:
% cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb[4] sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[>....................] recovery = 4.8% (47825800/976631296) finish=158.3min speed=97781K/sec
unused devices: <none>
mdadm shows:
% mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Wed Feb 26 21:00:17 2014
Raid Level : raid5
Array Size : 1953262592 (1862.78 GiB 2000.14 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 3
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Mon Oct 17 21:52:05 2016
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Rebuild Status : 58% complete
Name : MyServer:0 (local to host MyServer)
UUID : ef5da4df:3e53572e:c3fe1191:925b24cf
Events : 554
Number Major Minor RaidDevice State
1 8 16 1 active sync /dev/sda
4 8 32 0 spare rebuilding /dev/sdb
3 8 48 2 active sync /dev/sdc
You can use watch command that refreshes every two seconds your terminal with the output :
# watch cat /proc/mdstat
Every 2.0s: cat /proc/mdstat Mon Oct 17 21:53:34 2016
Personalities : [raid6] [raid5] [raid4]
md0 : active raid5 sdb[4] sda[1] sdc[3]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/2] [_UU]
[===========>.........] recovery = 59.4% (580918844/976631296) finish=69.2min speed=95229K/sec
unused devices: <none>
Growing a Linux Raid
Even so … 2T is not a lot of disk usage these days! If you need to grow-extend your linux raid, then you need hard disks with the same geometry (or larger).
Steps on growing your linux raid are also simply:
# Umount the linux raid device:
% umount /dev/md0
# Add the new disk
% mdadm --add /dev/md0 /dev/sdd
# Check mdstat
% cat /proc/mdstat
# Grow linux raid by one device
% mdadm --grow /dev/md0 --raid-devices=4
# watch mdstat for reshaping to complete - also 3h+ something
% watch cat /proc/mdstat
# Filesystem check your linux raid device
% fsck -y /dev/md0
# Resize - Important
% resize2fs /dev/md0
But sometimes life happens …
Need 1 spare to avoid degraded array, and only have 0.
mdadm: Need 1 spare to avoid degraded array, and only have 0.
or
mdadm: Failed to initiate reshape!
Sometimes you get an error that informs you that you can not grow your linux raid device! It’s not time to panic or flee the scene. You’ve got this. You have already kept a recent backup before you started and you also reading this blog post!
You need a (an extra) backup-file !
% mdadm --grow --raid-devices=4 --backup-file=/tmp/backup.file /dev/md0
mdadm: Need to backup 3072K of critical section..
% cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sda[4] sdb[0] sdd[3] sdc[1]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[>....................] reshape = 0.0
% (66460/976631296) finish=1224.4min speed=13292K/sec
unused devices: <none>
1224.4min seems a lot !!!
dmesg shows:
% dmesg
[ 36.477638] md: Autodetecting RAID arrays.
[ 36.477649] md: Scanned 0 and added 0 devices.
[ 36.477654] md: autorun ...
[ 36.477658] md: ... autorun DONE.
[ 602.987144] md: bind<sda>
[ 603.219025] RAID conf printout:
[ 603.219036] --- level:5 rd:3 wd:3
[ 603.219044] disk 0, o:1, dev:sdb
[ 603.219050] disk 1, o:1, dev:sdc
[ 603.219055] disk 2, o:1, dev:sdd
[ 608.650884] RAID conf printout:
[ 608.650896] --- level:5 rd:3 wd:3
[ 608.650903] disk 0, o:1, dev:sdb
[ 608.650910] disk 1, o:1, dev:sdc
[ 608.650915] disk 2, o:1, dev:sdd
[ 684.308820] RAID conf printout:
[ 684.308832] --- level:5 rd:4 wd:4
[ 684.308840] disk 0, o:1, dev:sdb
[ 684.308846] disk 1, o:1, dev:sdc
[ 684.308851] disk 2, o:1, dev:sdd
[ 684.308855] disk 3, o:1, dev:sda
[ 684.309079] md: reshape of RAID array md0
[ 684.309089] md: minimum _guaranteed_ speed: 1000 KB/sec/disk.
[ 684.309094] md: using maximum available idle IO bandwidth (but not more than 200000 KB/sec) for reshape.
[ 684.309105] md: using 128k window, over a total of 976631296k.
mdstat
% cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sda[4] sdb[0] sdd[3] sdc[1]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[>....................] reshape = 0.0
% (349696/976631296) finish=697.9min speed=23313K/sec
unused devices: <none>ok it’s now 670minutes
Time to use watch:
(after a while)
% watch cat /proc/mdstat
Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid5 sda[4] sdb[0] sdd[3] sdc[1]
1953262592 blocks super 1.2 level 5, 512k chunk, algorithm 2 [4/4] [UUUU]
[===========>......] reshape = 66.1% (646514752/976631296) finish=157.4min speed=60171K/sec
unused devices: <none>
mdadm shows:
% mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Feb 6 13:06:34 2014
Raid Level : raid5
Array Size : 1953262592 (1862.78 GiB 2000.14 GB)
Used Dev Size : 976631296 (931.39 GiB 1000.07 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Sat Oct 22 14:59:33 2016
State : clean, reshaping
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : left-symmetric
Chunk Size : 512K
Reshape Status : 66% complete
Delta Devices : 1, (3->4)
Name : MyServer:0
UUID : d635095e:50457059:7e6ccdaf:7da91c9b
Events : 1536
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
3 8 48 2 active sync /dev/sdd
4 8 0 3 active sync /dev/sdabe patient and keep an aye on mdstat under proc.
So basically those are the steps, hopefuly you will find them useful.
- First linux distro i ‘ve ever used: Red Hat 5.2 but i couldnt find a way to power up X
- Used SuSE Linux 6.3 for about six months. There was a tool named sax or sox that you could configure your video card from command line.
- After that was Mandrake 8.2 and kept Mandrake for several years.
- Did a trial with Linux From Scratch and of course Slackware was always just a click (download) far away but i returned to mandrake
- Left from mandrake just about mandriva came in and started to use ubuntu. Before all the crappy decisions!
- Used ubuntu for almost 3 years but did some tests with fedora … never liked it !
- At 2009 did an error with rm (i removed the entire usr dir) and tried archlinux for the first time.
- NEVER looked back, never installed another linux distro, never had a problem in my life!